项目理念 |我的愿景
项目名称:我的愿景
目标:这个项目背后的想法是创建一个应用程序,帮助有视力障碍的人分析他们的周围环境。
描述:要分析他们周围的一切,他们只需用手机拍照,应用程序会自动学习照片中的内容/物体,并提供语音帮助,了解附近物体的类型。
但可能有一个问题,视障人士将如何操作此应用程序。好吧,他们所要做的就是在移动设备上的任何虚拟助手的帮助下打开此应用程序,然后,为了拍照,他们可以使用任何一个音量键或相机按钮。
然后将捕获的图片输入到预训练的卷积神经网络(CNN),并且该图片中所有检测到的对象都将被标记。然后这些标签将被传递到文本到语音引擎,该引擎通过使用自然语言处理 (NLP) 分析和处理文本将文本转换为语音。
这个想法的一个优点是它不仅限于移动应用程序。在高级层面上,人们可以实现这个想法来构建一些可以以类似方式工作的小工具,但不是手动拍照,它可以拍摄周围环境的实时图像(如在自动驾驶汽车中)并为视障人士提供语音帮助通过使用不同类型的传感器,人们不仅可以了解附近物体的类型,还可以了解该物体的大致距离。
流程图: 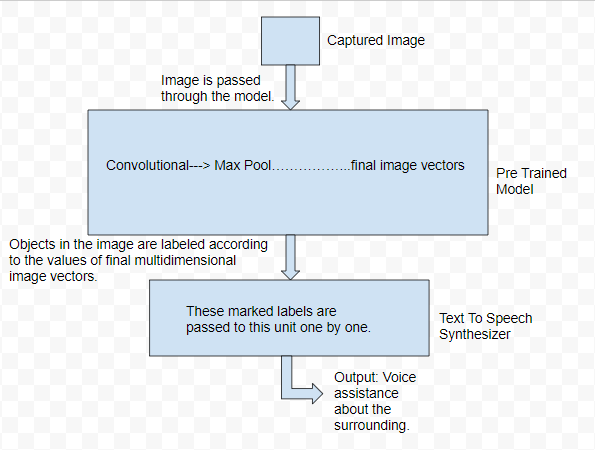
使用的工具:
- 对于硬件的观点:
- 具有优质相机的移动设备。
- 学习模型权重的良好处理能力。
- 对于软件的观点:
- 谷歌火力基地。
- 谷歌云服务。
- 安卓/视觉工作室。
- Python, Java,JavaScript。
注意:用于对象检测的算法是YOLO 算法,而对于文本到语音的转换,则使用谷歌云服务。
特点及应用:
- 为视障人士提供语音帮助。
- 使用方便,只需按音量键即可点击图片。
- 这个想法不仅限于一个简单的移动应用程序,因为一个系统可以与其他各种集成
可以在实时图像上工作的设备手动捕获图片汽车)技术而不是拍照
手动一次又一次。 - 通过使用不同类型的传感器,可以大大提高系统的函数质量,因为这
系统可以实现输出到对象的近似距离和类似的其他特征。
重要链接:
Yolo 网站: https://pjreddie.com/darknet/yolo/
从头开始训练自己的模型: https://timebutt.github.io/static/how-to-train-yolov2-to-detect-custom-objects/
文字转语音引擎: https://cloud.google.com/text-to-speech/docs/
谢谢你!
注意:这个项目想法是为 ProGeek Cup 2.0- GeeksforGeeks 的项目竞赛贡献的。