长短期记忆网络解释
先决条件:递归神经网络
为了解决深度递归神经网络中梯度消失和爆炸的问题,开发了许多变体。其中最著名的一个是长短期记忆网络(LSTM)。从概念上讲,LSTM 循环单元试图“记住”迄今为止看到的所有过去的网络知识,并“忘记”不相关的数据。这是通过为不同目的引入称为“门”的不同激活函数层来完成的。每个 LSTM 循环单元还维护一个称为内部单元状态的向量,该向量在概念上描述了被前一个 LSTM 循环单元选择保留的信息。一个长短期记忆网络由四个不同的门组成,用于不同的目的,如下所述:-
- 忘记门(f):它决定忘记之前的数据到什么程度。
- Input Gate(i):它决定了写入内部单元状态的信息范围。
- 输入调制门(g):它通常被认为是输入门的一个子部分,许多关于 LSTM 的文献甚至都没有提到它,并假设它在输入门内。它用于调制输入门将写入内部状态单元的信息,方法是向信息添加非线性并使信息为零均值。这样做是为了减少学习时间,因为零均值输入具有更快的收敛速度。虽然这个门的动作没有其他的那么重要,并且通常被视为一个提供技巧的概念,但在 LSTM 单元的结构中包含这个门是一种很好的做法。
- 输出门(o):它确定从当前内部单元状态生成的输出(下一个隐藏状态)。
长短期记忆网络的基本工作流程类似于循环神经网络的工作流程,唯一的区别是内部细胞状态也与隐藏状态一起向前传递。
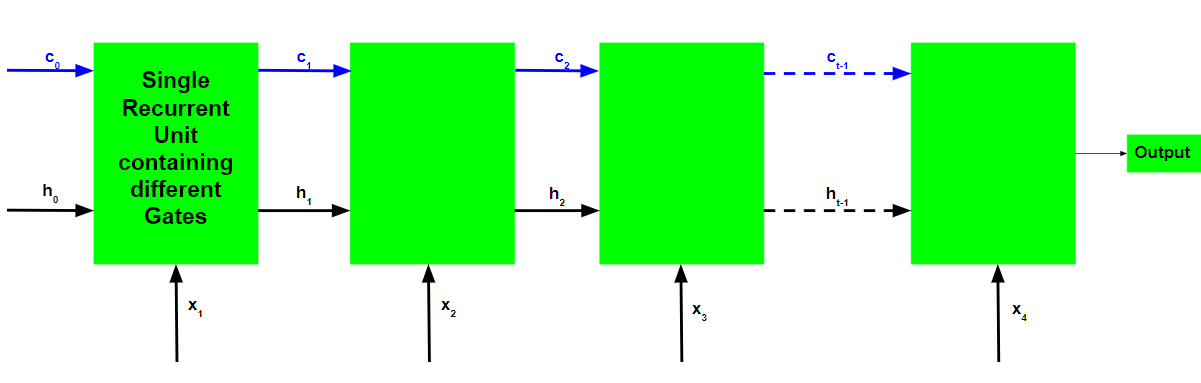
LSTM 循环单元的工作:
- 输入当前输入、先前的隐藏状态和先前的内部单元状态。
- 按照以下步骤计算四个不同门的值:-
- 对于每个门,计算当前输入和前一个隐藏状态的参数化向量,方法是逐元素乘以相关向量以及每个门的相应权重。
- 在参数化向量上按元素对每个门应用相应的激活函数。下面给出了具有要应用于门的激活函数的门列表。
- 计算当前内部细胞状态,首先计算输入门和输入调制门的元素乘法向量,然后计算遗忘门的元素乘法向量和之前的内部细胞状态,然后将这两个向量相加。

- 通过首先取当前内部单元状态向量的元素级双曲正切,然后与输出门执行元素级乘法来计算当前隐藏状态。
上述工作说明如下:-

请注意,蓝色圆圈表示逐元素乘法。权重矩阵 W 包含当前输入向量和每个门的先前隐藏状态的不同权重。
就像循环神经网络一样,LSTM 网络也在每个时间步生成一个输出,该输出用于使用梯度下降训练网络。
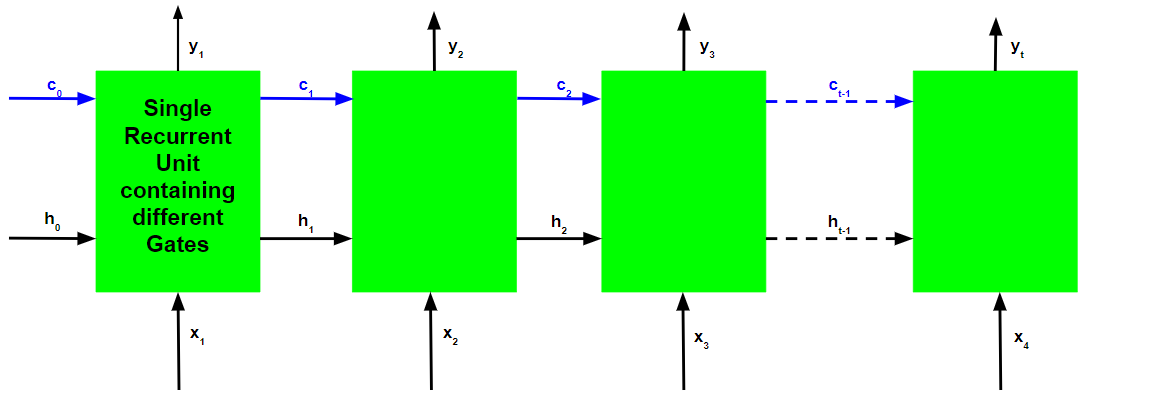
循环神经网络和长短期记忆网络的反向传播算法之间的唯一主要区别与算法的数学有关。
让 是每个时间步的预测输出,并且
是每个时间步的预测输出,并且是每个时间步的实际输出。然后每个时间步的误差由下式给出:-

因此,总误差由所有时间步长的误差总和给出。


同样,值 可以计算为每个时间步的梯度之和。
可以计算为每个时间步的梯度之和。

使用链式法则并使用以下事实 是一个函数
是一个函数 这函数是
这函数是 ,出现以下表达式:-
,出现以下表达式:-

因此,总误差梯度由下式给出:-

请注意,梯度方程涉及一个链 对于 LSTM 反向传播,而梯度方程涉及一个链
对于 LSTM 反向传播,而梯度方程涉及一个链 对于基本的递归神经网络。
对于基本的递归神经网络。
LSTM 如何解决梯度消失和爆炸的问题?
回想一下表达式 .
.

梯度的值由导数链控制,从 .使用表达式扩展此值
.使用表达式扩展此值 :-
:-

对于基本的 RNN,术语 一段时间后开始取大于 1 或小于 1 的值,但始终在相同的范围内。这是梯度消失和爆炸问题的根本原因。在 LSTM 中,术语
一段时间后开始取大于 1 或小于 1 的值,但始终在相同的范围内。这是梯度消失和爆炸问题的根本原因。在 LSTM 中,术语 没有固定的模式,可以在任何时间步取任何正值。因此,不能保证对于无限数量的时间步长,该项将收敛到 0 或完全发散。如果梯度开始向零收敛,则可以相应地调整门的权重以使其更接近 1。由于在训练阶段,网络仅调整这些权重,因此它学习何时让梯度收敛到零和什么时候保存它。
没有固定的模式,可以在任何时间步取任何正值。因此,不能保证对于无限数量的时间步长,该项将收敛到 0 或完全发散。如果梯度开始向零收敛,则可以相应地调整门的权重以使其更接近 1。由于在训练阶段,网络仅调整这些权重,因此它学习何时让梯度收敛到零和什么时候保存它。