Linux 中的过滤器
过滤器是将纯文本(存储在文件中或由另一个程序生成)作为标准输入,将其转换为有意义的格式,然后将其作为标准输出返回的程序。 Linux 有许多过滤器。一些最常用的过滤器解释如下:
1. cat :逐行显示文件的文本。
句法:
cat [path]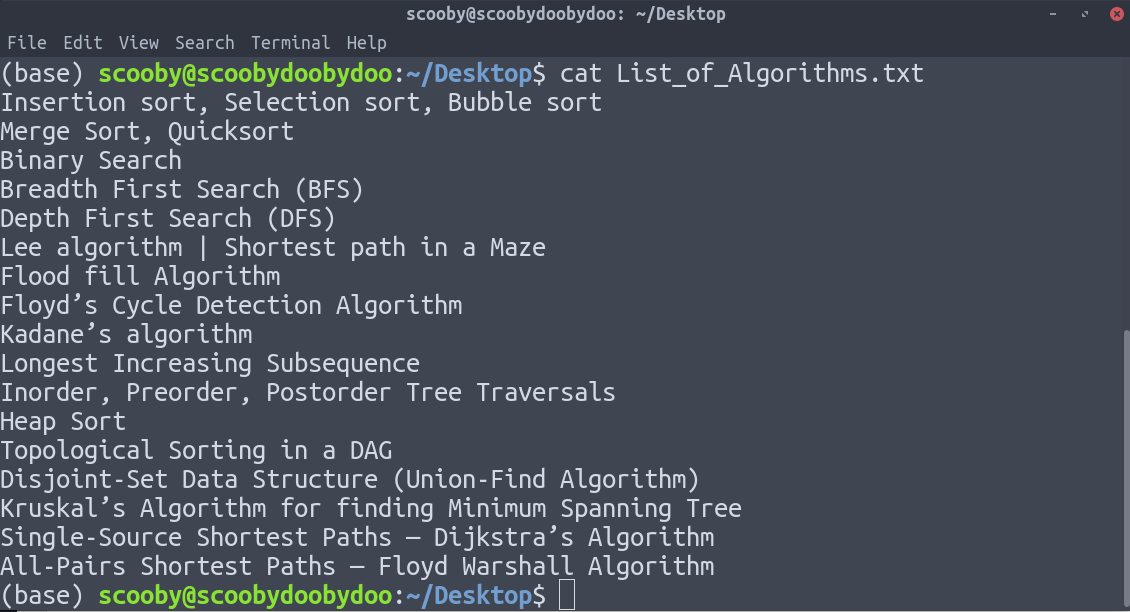
2. head :显示指定文本文件的前 n 行。如果未指定行数,则默认打印前 10 行。
句法:
head [-number_of_lines_to_print] [path] 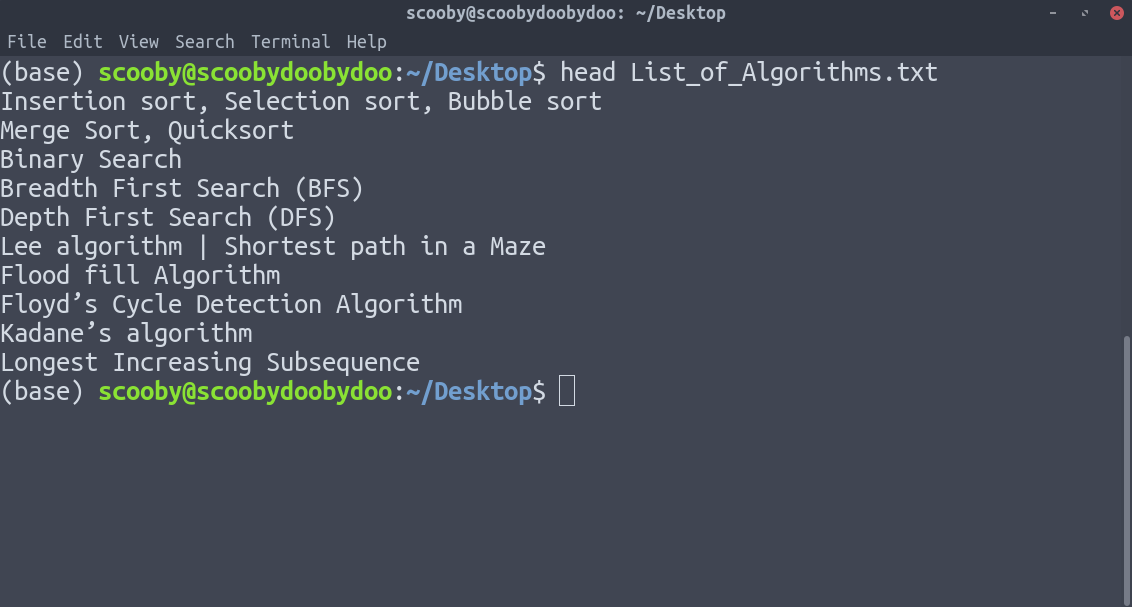
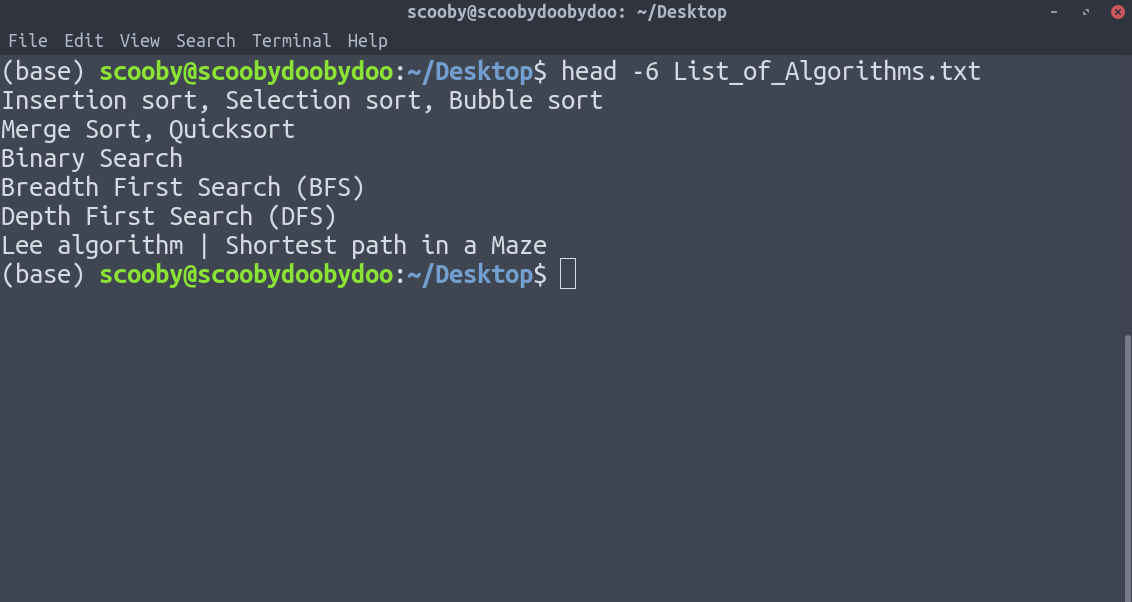
3. tail :它的工作方式与 head 相同,只是顺序相反。 tail 的唯一区别是,它从下到上返回行。
句法:
tail [-number_of_lines_to_print] [path]4. sort :默认按字母顺序对行进行排序,但有许多选项可用于修改排序机制。请务必查看主页以查看它可以执行的所有操作。
句法:
sort [-options] [path]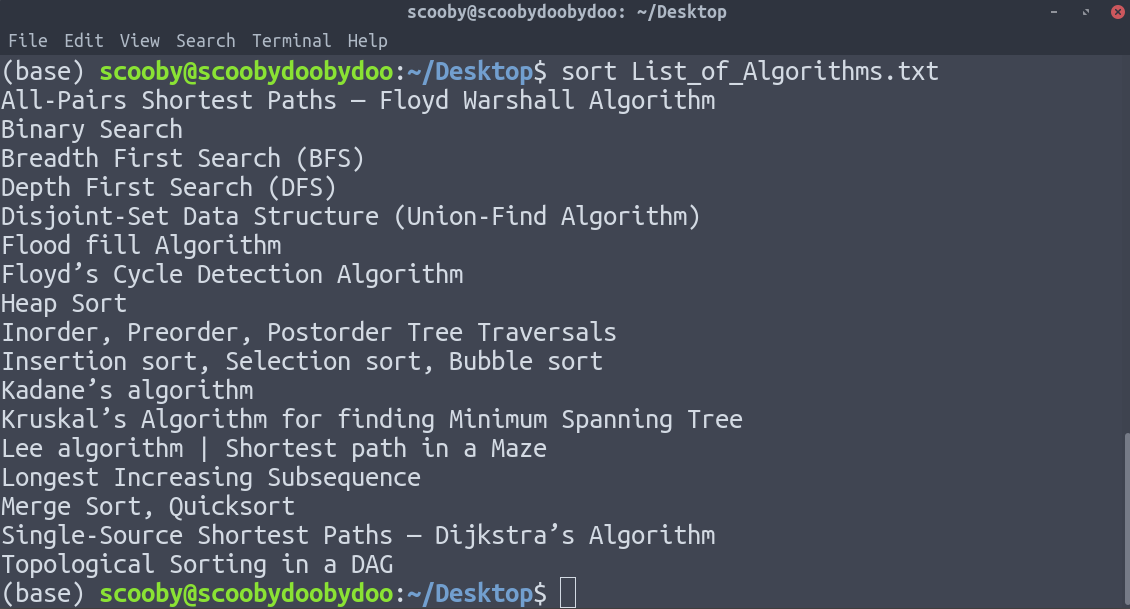
5. uniq :删除重复行。 uniq 有一个限制,它只能删除连续的重复行(尽管这可以通过使用管道来解决)。假设我们有以下数据。
句法:
uniq [options] [path]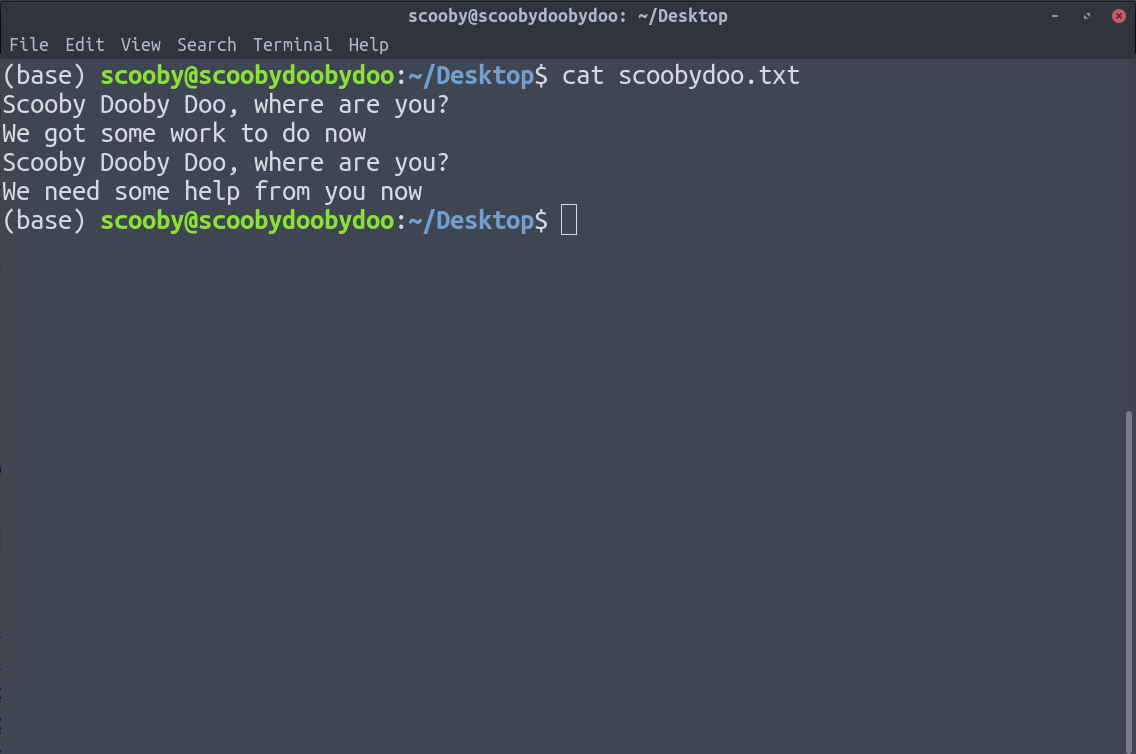
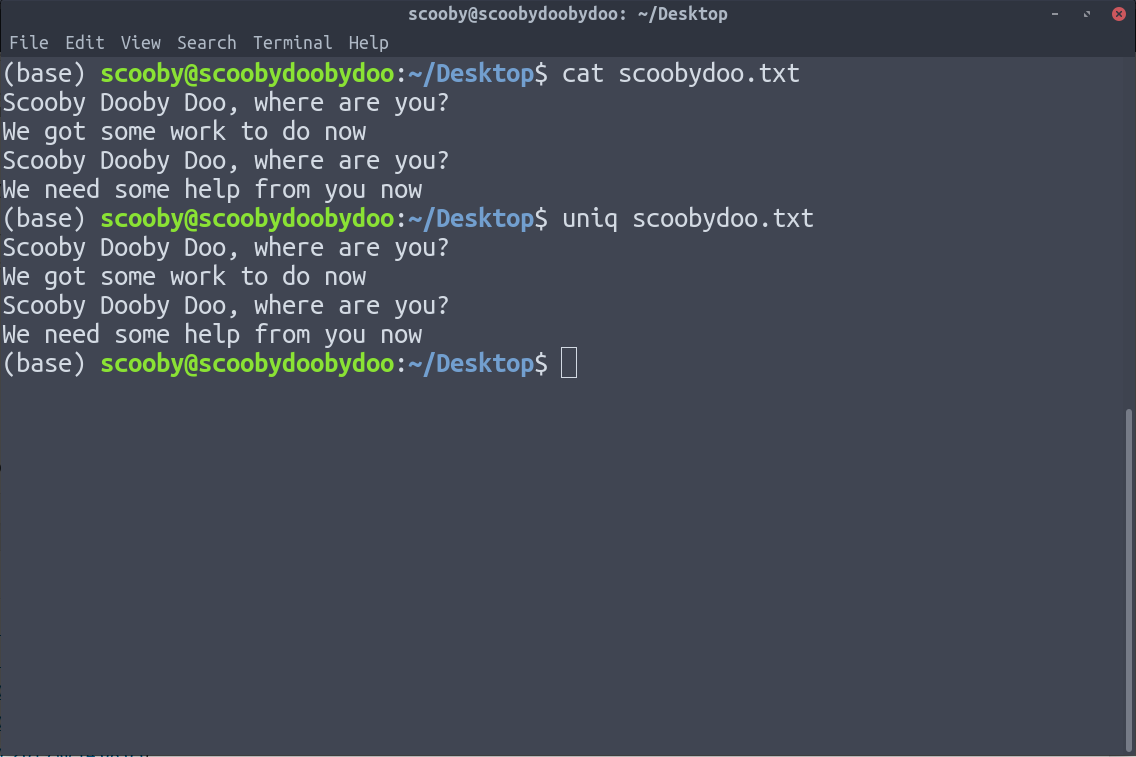
您可以看到应用 uniq 不会删除任何重复的行,因为 uniq 只会删除在一起的重复行。
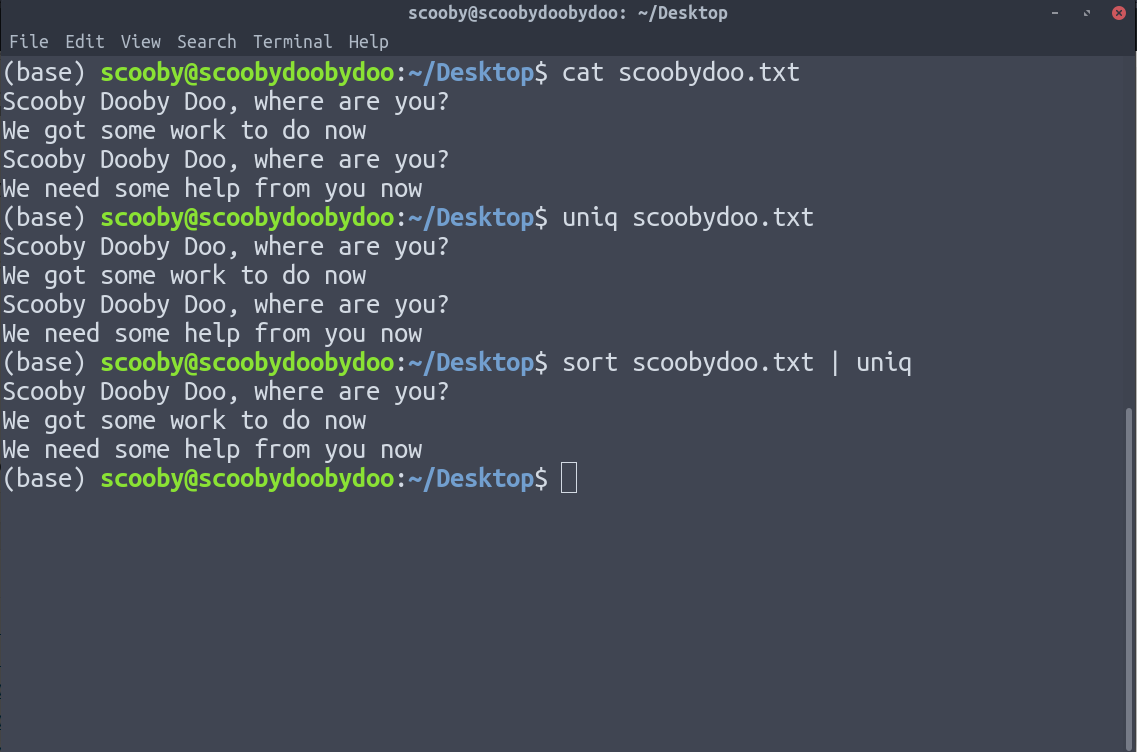
将 uniq 应用于已排序的数据时,它会删除重复的行,因为在对数据进行排序后,重复的行会聚在一起。
6. wc : wc 命令给出数据中的行数、单词数和字符数。
句法:
wc [-options] [path]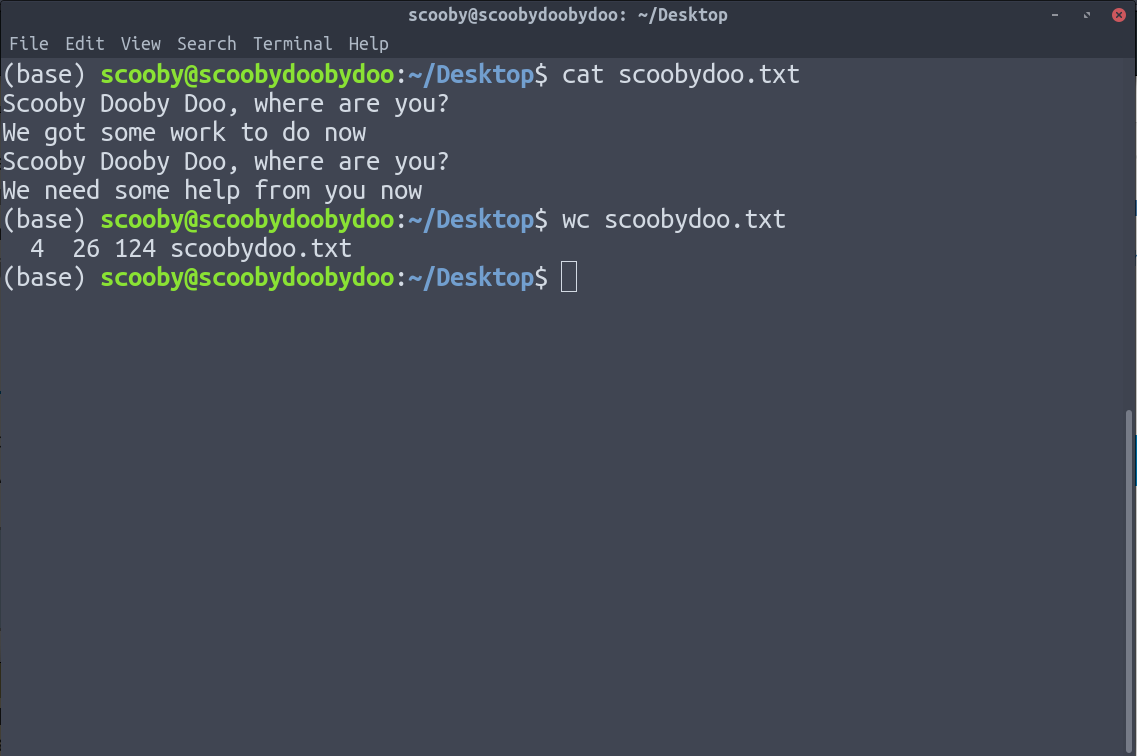
在上图中,wc 给出了 4 个输出:
- 行数
- 字数
- 字符
- 小路
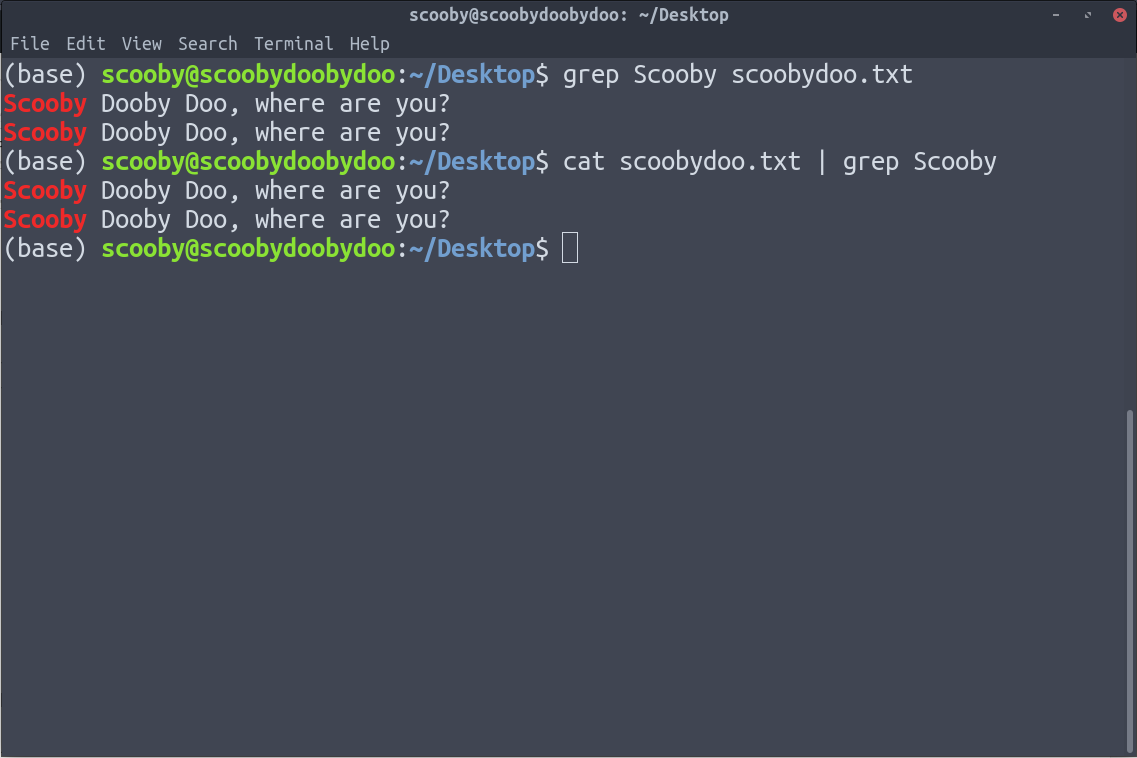
7. grep : grep 用于从文本文件中搜索特定信息。
句法:
grep [options] pattern [path]以下是我们可以实现 grep 的两种方式。
8. tac : tac 与 cat 正好相反,它的工作方式相同,即不是从第 1 行到第 n 行打印,而是从第 n 行到第 1 行打印。这正好是 cat 命令的相反。
句法:
tac [path] 
9. sed : sed 代表流编辑器。它使我们能够有效地对我们的数据应用搜索和替换操作。 sed是一个相当先进的过滤器,它的所有选项都可以在它的手册页上看到。
句法:
sed [path]我们上面使用的表达式非常基本,其形式为“s/search/replace/g”
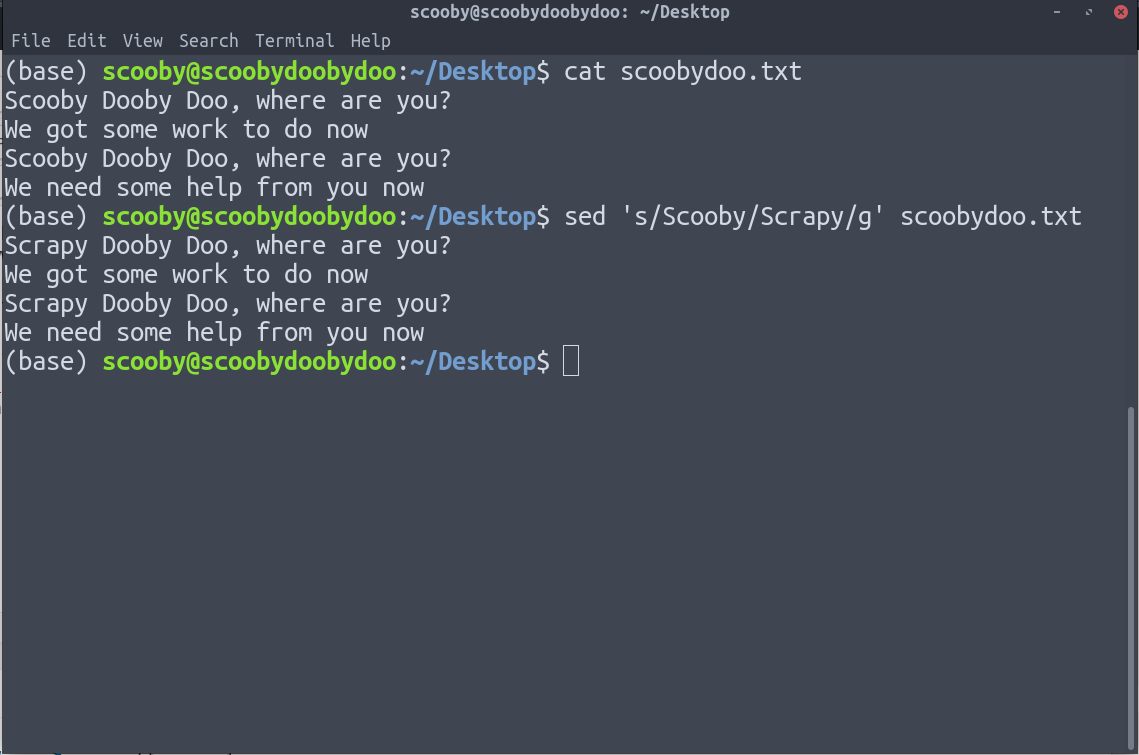
在上图中,我们可以清楚地看到 Scooby 被 Scrapy 取代。
10. nl : nl 用于对我们的文本数据的行进行编号。
句法:
nl [-options] [path]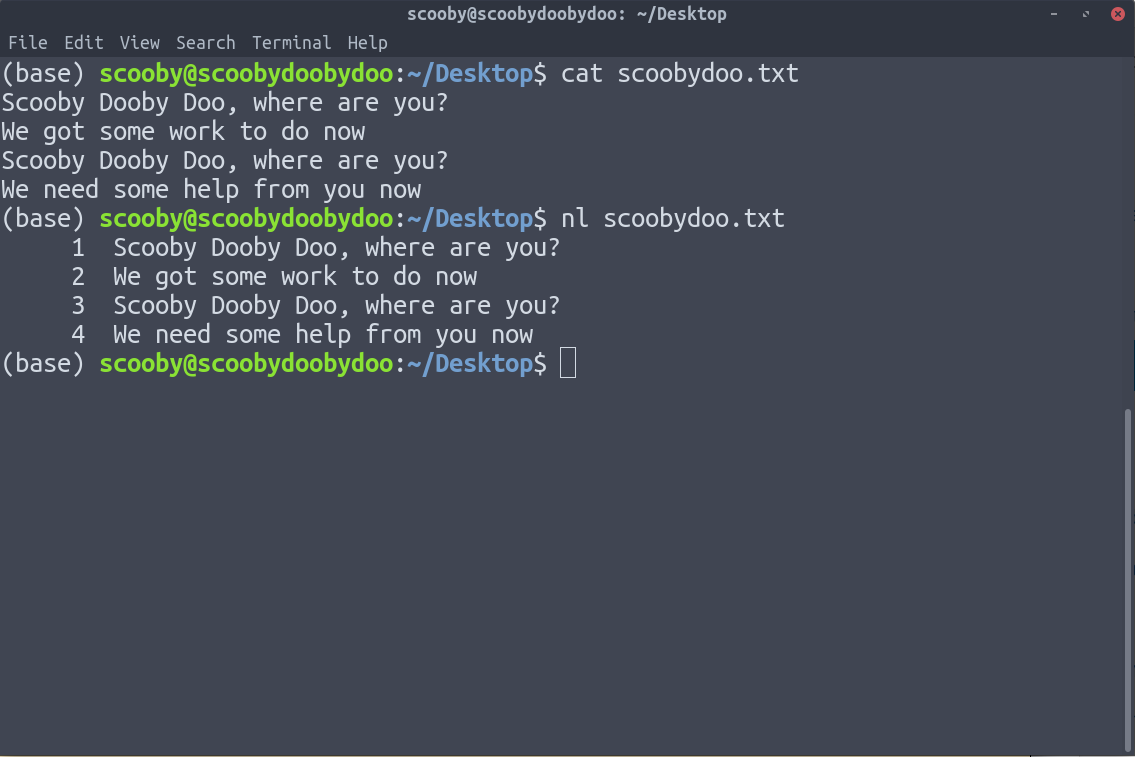
从上图中可以清楚地看到,这些行已经被编号