在Python使用 BeautifulSoup 从 HTML 中提取 JSON
在本文中,我们将使用Python的BeautifulSoup 从 HTML 中提取 JSON。
需要的模块
- bs4 : Beautiful Soup(bs4) 是一个Python库,用于从 HTML 和 XML 文件中提取数据。这个模块没有内置于Python。要安装此类型,请在终端中输入以下命令。
pip install bs4- requests : Request 允许您非常轻松地发送 HTTP/1.1 请求。这个模块也没有内置于Python。要安装此类型,请在终端中输入以下命令。
pip install requests方法:
- 导入所有需要的模块。
- 在 get函数(UDF) 中传递 URL,以便它将 GET 请求传递给 URL,并返回响应。
Syntax: requests.get(url, args)
- 现在使用 bs4 解析 HTML 内容。
Syntax: BeautifulSoup(page.text, ‘html.parser’)
Parameters:
- page.text : It is the raw HTML content.
- html.parser : Specifying the HTML parser we want to use.
- 现在使用 find()函数获取所有需要的数据。
现在找到带有 li, a, p 标签的客户列表,其中有一些唯一的类或 id。您可以在浏览器中打开网页,通过右键单击查看相关元素,如图所示。
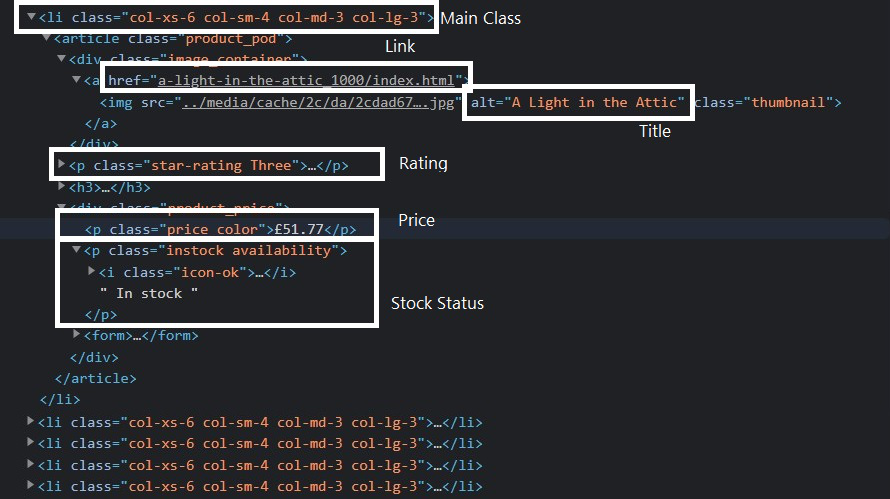
- 创建一个 Json 文件并使用json.dump()方法将Python对象转换为适当的 JSON 对象。
下面是完整的实现:
Python3
# Import the required modules
import requests
from bs4 import BeautifulSoup
import json
# Function will return a list of dictionaries
# each containing infomation of books.
def json_from_html_using_bs4(base_url):
# requests.get(url) returns a response that is saved
# in a reponse object called page.
page = requests.get(base_url)
# page.text gives us access to the web data in text
# format, we pass it as an argument to BeautifulSoup
# along with the html.parser which will create a
# parsed tree in soup.
soup = BeautifulSoup(page.text, "html.parser")
# soup.find_all finds the div's, all having the same
# class "col-xs-6 col-sm-4 col-md-3 col-lg-3" that is
# stored in books
books = soup.find_all(
'li', attrs={'class':
'col-xs-6 col-sm-4 col-md-3 col-lg-3'})
# Initialise the required variables
star = ['One', 'Two', 'Three', 'Four', 'Five']
res, book_no = [], 1
# Iterate books classand check for the given tags
# to get the information of each books.
for book in books:
# Title of book in ![]() tag with "alt" key.
title = book.find('img')['alt']
# Link of book in tag with "href" key
link = base_url[:37] + book.find('a')['href']
# Rating of book from
tag with "alt" key.
title = book.find('img')['alt']
# Link of book in tag with "href" key
link = base_url[:37] + book.find('a')['href']
# Rating of book from tag
for index in range(5):
find_stars = book.find(
'p', attrs={'class': 'star-rating ' + star[index]})
# Check which star-rating class is not
# returning None and then break the loop
if find_stars is not None:
stars = star[index] + " out of 5"
break
# Price of book from
tag in price_color class
price = book.find('p', attrs={'class': 'price_color'
}).text
# Stock Status of book from
tag in
# instock availability class.
instock = book.find('p', attrs={'class':
'instock availability'}).text.strip()
# Create a dictionary with the above book information
data = {'book no': str(book_no), 'title': title,
'rating': stars, 'price': price, 'link': link,
'stock': instock}
# Append the dictionary to the list
res.append(data)
book_no += 1
return res
# Main Function
if __name__ == "__main__":
# Enter the url of website
base_url = "https://books.toscrape.com/catalogue/page-1.html"
# Function will return a list of dictionaries
res = json_from_html_using_bs4(base_url)
# Convert the python objects into json object and export
# it to books.json file.
with open('books.json', 'w', encoding='latin-1') as f:
json.dump(res, f, indent=8, ensure_ascii=False)
print("Created Json File")
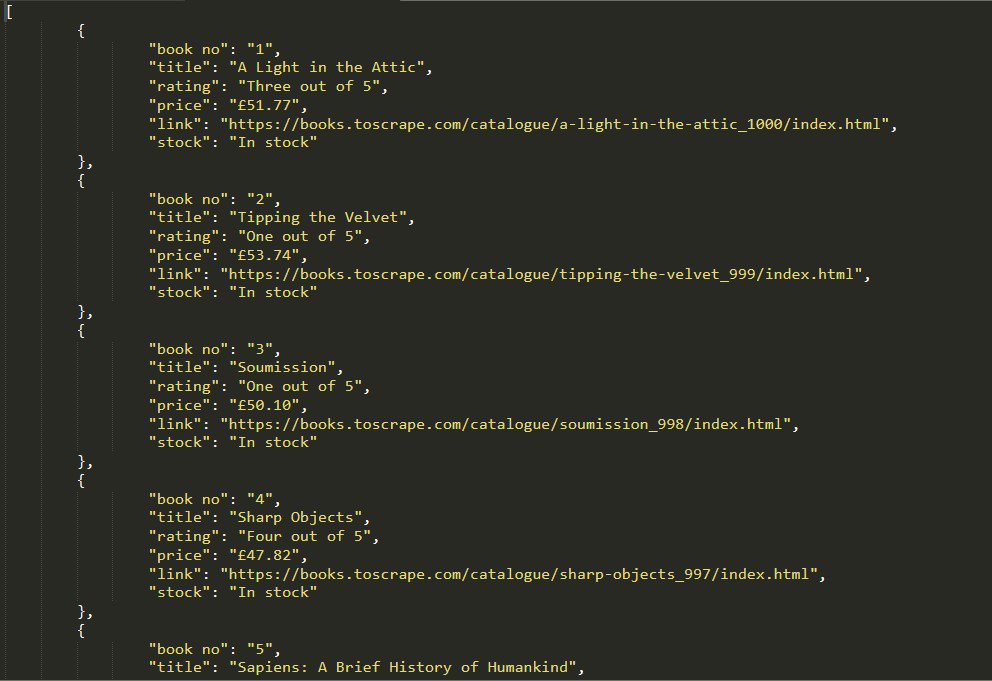
输出:
Created Json File我们的 JSON 文件输出: