使用 BeautifulSoup 将 HTML 转换为文本
很多时候在使用 Web 自动化时,我们需要将 HTML 代码转换为文本。这可以使用 BeautifulSoup 来完成。该模块提供了 get_text()函数,该函数将 HTML 作为输入并返回文本作为输出。
示例 1:
Python3
# importing the library
from bs4 import BeautifulSoup
# Initializing variable
gfg = BeautifulSoup("Section
BeautifulSoup\
- Example 1
")
# Calculating result
res = gfg.get_text()
# Printing the result
print(res)
Python3
# importing the library
from bs4 import BeautifulSoup
from urllib import request
# Initializing variable
url = "https://www.geeksforgeeks.org/matrix-introduction/"
gfg = BeautifulSoup(request.urlopen(url).read())
# Extracting data for article section
bodyHtml = gfg.find('article', {'class' : 'content'})
# Calculating result
res = bodyHtml.get_text()
# Printing the result
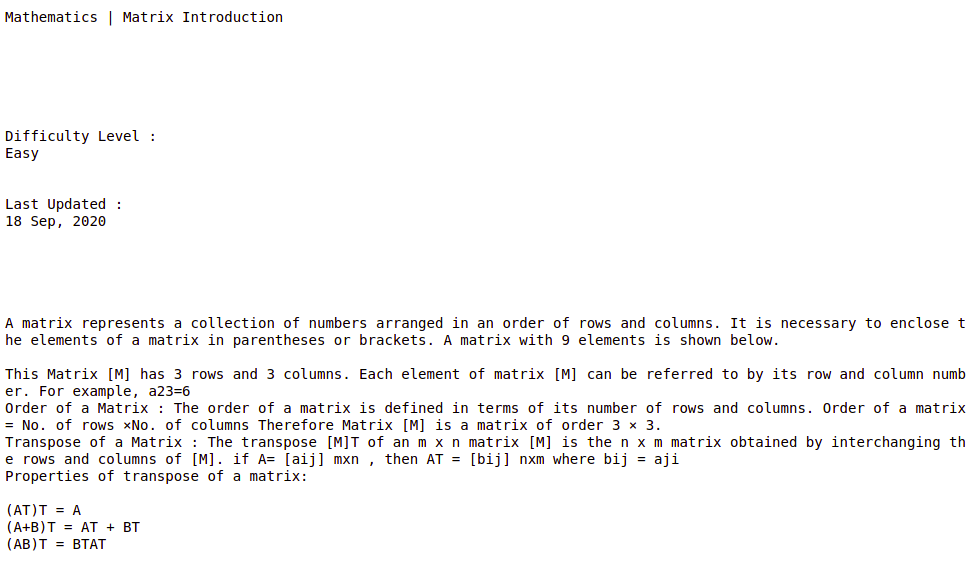
print(res)输出:
Section BeautifulSoupExample 1示例 2:此示例从实时网站中提取数据,然后将其转换为文本。在这个例子中,我们使用了 urllib 库中的 request 模块从 URL 中读取 HTML 数据。
蟒蛇3
# importing the library
from bs4 import BeautifulSoup
from urllib import request
# Initializing variable
url = "https://www.geeksforgeeks.org/matrix-introduction/"
gfg = BeautifulSoup(request.urlopen(url).read())
# Extracting data for article section
bodyHtml = gfg.find('article', {'class' : 'content'})
# Calculating result
res = bodyHtml.get_text()
# Printing the result
print(res)
输出: