在本文中,我们将研究Kubernetes API以及它如何简化对应用程序生命周期的建模。让我们研究一下使Kubernetes可用,可扩展并且简直很棒的概念。
关于可伸缩应用程序的需求,我们已经讨论了容器和节点,但这只是冰山一角。为了运行一个完全可扩展的应用程序,我们还需要更多的东西。这就是Kubernetes API的用处。它提供了一些非常方便的原语,使管理云原生应用程序变得更加容易。一些API对象是pod和node , Deployments , secrets等等。
让我们以一个示例应用程序为例。我们确定容器是使用Kubernetes的第一步,因此让我们从为运行Hello应用程序而构建的容器开始。这个程序真的很简单。只要有人在端口8080上对其本地IP进行ping操作,它只会返回“ Hello”。
我们要做的第一件事是创建一些机器或节点,以在其上运行我们的应用程序。在这里,我们将使用Google Kubernetes Engine快速入门。我们可以使用Gcloud命令行工具通过以下命令来配置Kubernetes集群:
$ gcloud container cluster create hello-cluster几分钟后,我们将创建一个集群。默认情况下,它带有三个节点。

这是一个很好的起点,但是现在我们需要实际运行我们的应用程序。由于我们使用的是命令行,因此可以使用名为kubectl的便捷工具来使用以下命令与Kubernetes API进行交互:
$ kubectl run dbd --image \
mydb/example-db:1.0.0 --record该命令实际上将创建一个称为部署的Kubernetes API对象。部署是管理应用程序生命周期的抽象。我们可以设置要管理的部署所需的应用程序实例数量,然后确保正在运行的实例或副本数量正确。

如果我们增加所需的副本数量,则部署将看到当前副本数量不足,并增加了另一个副本。

甚至在节点崩溃时也可以使用。如果节点出现故障,当前状态将再次与所需状态不同,Kubernetes将为我们安排另一个副本。
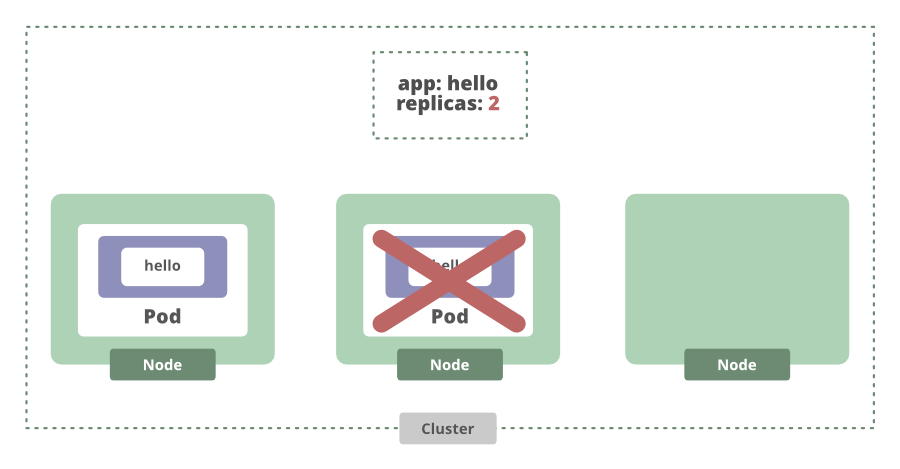
现在我们知道我们的应用程序正在这些节点上运行。要访问它,我们必须使用以下命令创建服务:
$ kubectl expose deployment dbd \
--port 80 --type Loadbalancer这将创建一个可用于访问正在运行的应用程序实例的终结点。在这种情况下,我们有多个应用程序实例。因此,此服务将在两个运行的Pod之间平衡传入请求的负载。对于集群内的任何容器,他们都可以使用服务名称连接到我们的服务。无论哪种方式,该服务都会跟踪pod运行的位置。

这是Kubernetes如何消除手动跟踪容器运行位置的另一个示例。即使某个Pod发生故障,一旦有新Pod恢复在线,该服务也会自动更新其端点列表以新Pod为目标。
Kubernetes对象(如部署和服务)会自动确保我们通过Pod运行正确数量的应用程序实例,并且始终可以访问它们。使用Kubernetes时,以前必须手动编码的功能才成为后来的想法。例如,部署使滚动更新之类的事情变得非常简单。我们可以编辑部署并观察应用程序的版本逐渐变化。假设我们有三个副本,我们想发布一个新版本的应用程序,该应用程序返回“ Bye”而不是“ Hello”。我们可以更新应用程序容器,观察新版本的逐步推出,并且部署将启动新的应用程序实例并开始将流量重新路由到它们。然后,一旦所需数量的新实例联机,旧的应用程序实例将脱机。

这意味着该方法的停机时间为零。由于Kubernetes正在用新实例逐步更新旧Pod实例。像这样的功能,加上在必要时可以快速回滚并跟踪部署历史等功能,所有这些功能都内置在Kubernetes中。
这是使它成为在其上构建其他系统和应用程序的好工具的很大一部分。 Kubernetes API确实确实使管理应用程序生命周期变得容易。基本的基本Pod,服务,部署以及其他一些功能使系统管理员和开发人员可以专注于该应用程序,而不必担心对其进行大规模管理。我们使用命令式方法。我们使用手动命令,而不是使用声明式方法,这是Kubernetes的一大吸引力。