将数据转换为计算机可以理解的内容的过程称为预处理。预处理的主要形式之一是过滤掉无用的数据。在自然语言处理中,无用的单词(数据)称为停用词。
什么是停用词?
停用词:停用词是搜索引擎已编程忽略的常用词(例如“ the”,“ a”,“ an”,“ in”),无论是在索引条目以进行检索还是在检索它们时搜索查询的结果。
我们不希望这些词占用数据库中的空间,也不会占用宝贵的处理时间。为此,我们可以通过存储您认为要停止使用的单词的列表轻松删除它们。 Python中的NLTK(自然语言工具包)具有以16种不同语言存储的停用词列表。您可以在nltk_data目录中找到它们。 home / pratima / nltk_data / corpora / stopwords是目录地址。(不要忘记更改您的主目录名称) 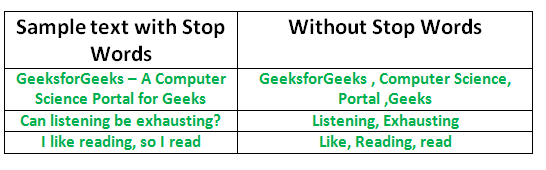
要检查停用词列表,您可以在Python shell中键入以下命令。
import nltk
from nltk.corpus import stopwords
print(stopwords.words('english')){“我们自己”,“她”,“之间”,“自己”,“但是”,“再次”,“在那里”,“大约”,“一次”,“正在”,“不在”,“非常”,“有”,“有”,“他们”,“拥有”,“一个”,“是”,“一些”,“为”,“做”,“其”,“您的”,“这样”,“进入” ,“ of”,“ most”,“ selfself”,“ other”,“ off”,“ is”,“ s”,“ am”,“ or”,“ who”,“ as”,“ from”,“他”,“每个”,“该”,“自己”,“直到”,“下面”,“是”,“我们”,“这些”,“您的”,“他的”,“通过”,“不” ,“不”,“我”,“被”,“她”,“更多”,“他自己”,“此”,“向下”,“应该”,“我们的”,“他们的”,“同时”,“上方”,“两者”,“向上”,“至”,“我们的”,“已经”,“她”,“全部”,“不”,“何时”,“在”,“任何”,“之前” ,“它们”,“相同”,“和”,“被”,“具有”,“在”,“将”,“在”,“做”,“自己”,“然后”,“那个”,“因为”,“什么”,“上方”,“为什么”,“如此”,“可以”,“没有”,“不”,“现在”,“下面”,“他”,“您”,“她自己” ,“有”,“只是”,“在哪里”,“太”,“仅”,“我自己”,“其中”,“那些”,“ i”,“之后”,“很少”,“谁”,“ t’,’being’,’if’,’theirs’,’my’,’against’,’a’,’by’,’doing’,’it’,’how’,’further’,’was’ ,“这里”,“ tha n’}
注意:您甚至可以通过在英语.txt中添加您选择的单词来修改列表。停用词目录中的文件。
使用NLTK删除停用词
以下程序从一段文本中删除停用词:
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
example_sent = """This is a sample sentence,
showing off the stop words filtration."""
stop_words = set(stopwords.words('english'))
word_tokens = word_tokenize(example_sent)
filtered_sentence = [w for w in word_tokens if not w in stop_words]
filtered_sentence = []
for w in word_tokens:
if w not in stop_words:
filtered_sentence.append(w)
print(word_tokens)
print(filtered_sentence)
输出:
['This', 'is', 'a', 'sample', 'sentence', ',', 'showing',
'off', 'the', 'stop', 'words', 'filtration', '.']
['This', 'sample', 'sentence', ',', 'showing', 'stop',
'words', 'filtration', '.']在文件中执行停用词操作
在下面的代码中,text.txt是要在其中删除停用词的原始输入文件。 filteredtext.txt是输出文件。可以使用以下代码完成:
import io
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
# word_tokenize accepts
# a string as an input, not a file.
stop_words = set(stopwords.words('english'))
file1 = open("text.txt")
# Use this to read file content as a stream:
line = file1.read()
words = line.split()
for r in words:
if not r in stop_words:
appendFile = open('filteredtext.txt','a')
appendFile.write(" "+r)
appendFile.close()
这就是我们通过删除不会对将来的操作产生影响的词来提高处理后的内容的效率。