在自然语言处理(NLP)和人工智能(AI)研究中,机器理解是一项非常有趣但具有挑战性的任务。有几种方法可以处理自然语言。随着深度学习算法,硬件和TensorFlow等用户友好型API的最新突破,某些任务已经达到一定的精度。本文包含有关各种深度学习模型的TensorFlow实现的信息,重点关注自然语言处理中的问题。该项目文章的目的是帮助机器理解句子的含义,从而提高机器翻译的效率,并与计算系统进行交互以从中获取有用的信息。
了解自然语言处理:
我们评估句子之间关系的能力对于应对各种自然语言挑战(例如文本摘要,信息提取和机器翻译)至关重要。该挑战被正式化为识别文本蕴含(RTE)的自然语言推理任务,该任务涉及将两个句子之间的关系分类为蕴含,矛盾或中立。例如,前提是“加菲猫是猫”,自然包含“加菲猫有爪子”的说法,与“加菲猫是德国牧羊犬”的说法相矛盾,并且对“加菲猫喜欢睡觉”的说法是中立的。
自然语言处理是计算机程序能够理解人类所说的人类语言的能力。 NLP是人工智能的一个组成部分,它处理与处理和分析大量自然语言数据有关的计算机和人类语言之间的交互。通过使用不同的有效手段处理自然数据,自然语言处理可以执行几个不同的任务。这些任务可能包括:
- 回答有关任何问题的问题(Siri *,Alexa *和Cortana *可以做什么)。
- 情绪分析(确定态度是正面,负面还是中立)。
- 图像到文本的映射(使用输入图像创建字幕)。
- 机器翻译(将文本翻译成不同的语言)。
- 语音识别
- 语音(POS)标记的一部分。
- 实体识别
NLP的传统方法涉及许多语言学本身的领域知识。
深度学习在最基本的层面上就是关于表示学习。通过卷积神经网络(CNN),可以使用不同过滤器的组成将对象分类。本文采用类似的方法,通过大型数据集创建单词的表示形式。
会话式AI:自然语言处理功能
- 自然语言处理(NLP)
- 文字挖掘(TM)
- 计算语言学(CL)
- 文本数据上的机器学习(文本上的ML)
- 文本数据的深度学习方法(基于文本的DL)
- 自然语言理解(NLU)
- 自然语言生成(NLG)
对话式AI近年来取得了令人瞩目的进步,其中包括自动语音识别(ASR),文本到语音(TTS)和意图识别方面的显着改进,以及语音助手设备(如Amazon Echo和Google)的显着增长家。
使用深度学习技术可以有效地解决与NLP相关的问题。本文在NLP模型中使用反向传播和随机梯度下降(SGD)4算法。
损失取决于训练集的每个元素,尤其是在计算密集型情况下,这种损失在NLP情况下是正确的,因为数据集很大。由于梯度下降是迭代的,因此必须通过许多步骤来完成,这意味着要遍历数以千计的数据。通过从较大的数据集中选择的随机,较小的数据集中获取平均损失来估算损失。然后计算该样本的导数,并假定该导数是使用梯度下降的正确方向。它甚至可能增加损失,而不是减少损失。通过多次补偿来进行补偿,每次都要执行非常小的步骤。每个步骤的计算成本都较低,总体上将产生更好的性能。 SGD算法是深度学习的核心。
字向量:
单词需要表示为机器学习模型的输入,一种数学方法是使用向量。估计有1300万个英语单词,但其中许多都是相关的。
搜索一个足以编码我们语言中所有语义的N维向量空间(其中N << 1,300万)。为此,需要了解单词之间的相似性和差异。向量的概念和它们之间的距离(余弦,欧几里得等)可以被用来发现单词之间的异同。 
我们如何代表单词的含义?
如果将单独的矢量用于英语词汇表中的所有+13百万个单词,则可能会出现一些问题。首先,将有带有多个“零”和一个“一个”(在不同位置代表不同单词)的大向量。这也称为单热编码。其次,当在Google中搜索诸如“新泽西州的酒店”之类的短语时,期望返回的结果与新泽西州的“汽车旅馆”,“住宿”,“住宿”有关。而且,如果使用单热编码,则这些单词没有相似性的自然概念。理想情况下,同义词/相似词的点积(因为我们正在处理向量)将接近预期结果之一。

Word2vec8是一组模型,可帮助推导单词及其上下文单词之间的关系。预测模型从单词向量的小的随机初始化开始,通过最小化损失函数学习向量。在Word2vec中,这是通过前馈神经网络和SGD算法之类的优化技术实现的。也有基于计数的模型,该模型构成了语料库中单词的共现计数矩阵。大型矩阵,每个“单词”都有一行,“上下文”则有各列。当然,“上下文”的数量很大,因为它的大小实质上是组合的。为了克服大小问题,可以将奇异值分解应用于矩阵,从而减小矩阵的维数并保留最大的信息。
软硬件:
所使用的编程语言是Python 3.5.2,以Intel Optimization for TensorFlow为框架。为了进行培训和计算,使用了由Intel Xeon可扩展处理器支持的Intel AI DevCloud。英特尔AI DevCloud拥有50多个内核以及自己的内存,互连模块和操作系统,可以为正确的应用程序和用例提供出色的主机CPU性能。
NLP的训练模型:Langmod_nn和Memn2n-master
Langmod_nn模型–
Langmod_nn模型6建立了一个三层正向Bigram模型神经网络,该神经网络由一个嵌入层,一个隐藏层和一个最终的softmax层组成,目标是使用语料库中的给定单词来尝试预测下一个单词。
将输入传递到一个尺寸为5000的热编码矢量中。
Input:
A word in a corpus. Because the vocabulary size can get very large, we have limited the vocabulary to the top 5000 words in the corpus, and the rest of the words are replaced with the UNK symbol. Each sentence in the corpus is also double-padded with stop symbols.
Output:
The following word in the corpus also encoded one-hot in a vector the size of the vocabulary.
图层–
该模型由以下三层组成:
嵌入层:每个单词对应一个唯一的嵌入向量,该单词在某些嵌入空间中的表示形式。在这里,所有嵌入的维数均为50。我们通过在常规反向传播过程中对嵌入的矩阵进行矩阵乘法(基本上是表查找)来找到给定单词的嵌入。
隐藏层:完全连接的前馈层,其隐藏层大小为100,并激活了整流线性单元(ReLU)。
Softmax层:完全连接的前馈层,其层大小等于词汇表大小,其中输出矢量的每个元素(对数)对应于词汇表中该词是下一个词的概率。
损失-logits和真实标签之间的正常交叉熵损失,即模型的成本。
优化器–
正常的SGD优化器,学习率为0.05。 
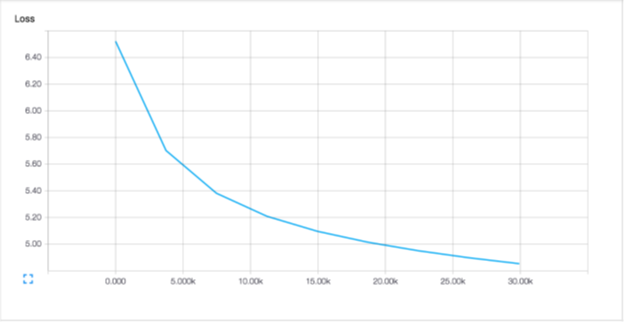
每个时期(大约480,000个示例)大约需要10分钟才能在CPU上进行训练。第五阶段后的测试日志可能性为-846493.44 Memn2n-master:
Memn2n-master7是一个神经网络,具有在可能较大的外部存储器上的反复注意模型。该体系结构是内存网络的一种形式,但与该模型不同,它是端到端训练的,因此在训练过程中需要的监视少得多,从而使其更普遍地适用于实际环境。
输入数据 –
该目录包括第一组20项任务,用于测试bAbI5项目中的文本理解和推理。这20个任务背后的动机是,每个任务都测试文本和推理的独特方面,并因此测试经过训练的模型的不同能力。
对于测试和培训,我们每个都有1000个问题。但是,我们并没有使用太多的数据,因为它可能用处不大。
该模型的结果是测试准确性为99.6%,训练准确性为97.6%和验证准确性为88%。
TensorFlow框架在使用具有良好准确性的NLP模型训练神经网络模型方面已显示出良好的结果。培训,测试和损失结果非常好。 Langmod_nn模型和存储网络可实现良好的准确率,且损失和误差值低。记忆模型的灵活性使其可以应用于各种问题,例如问题解答和语言建模。
结论:
如图所示,NLP提供了广泛的技术和工具,可以应用于生活的所有领域。通过学习模型并在日常交互中使用它们,生活质量将得到极大改善。 NLP技术有助于改善沟通,达成目标并改善每次互动所获得的结果。 NLP帮助人们使用他们已经可用的工具和技术。通过正确学习NLP技术,人们可以实现目标并克服障碍。
将来,NLP将超越统计和基于规则的系统,对语言的自然理解。科技巨头已经进行了一些改进。例如,Facebook *尝试使用深度学习来理解文本,而无需进行解析,标记,命名实体识别(NER)等,而Google试图将语言转换为数学表达式。谷歌和Facebook分别在bAbI任务上使用网格长短期存储网络和端到端存储网络进行端点检测,分别显示了NLP模型可以实现的进步。