自然语言处理 |标记文本、句子、单词的工作原理
自然语言处理(NLP)是计算机科学、人工智能、信息工程和人机交互的一个子领域。该领域侧重于如何对计算机进行编程以处理和分析大量自然语言数据。这很难执行,因为阅读和理解语言的过程远比乍看之下复杂得多。
标记化是将字符串、文本标记或拆分为标记列表的过程。可以将记号视为部分,就像单词是句子中的记号,句子是段落中的记号。
文章重点——
- 文本成句子标记化
- 句子成词标记化
- 使用正则表达式标记化的句子
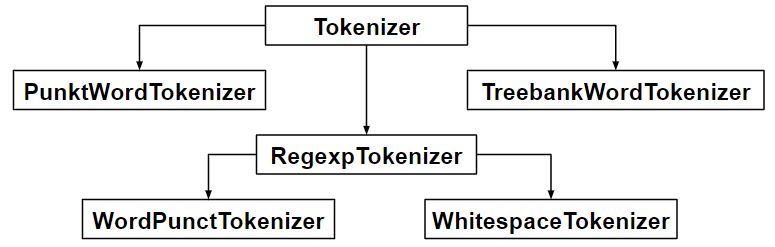
代码 #1:句子标记化——在段落中拆分句子
from nltk.tokenize import sent_tokenize
text = "Hello everyone. Welcome to GeeksforGeeks. You are studying NLP article"
sent_tokenize(text)
输出 :
['Hello everyone.',
'Welcome to GeeksforGeeks.',
'You are studying NLP article']
sent_tokenize是如何工作的?
sent_tokenize函数使用nltk.tokenize.punkt module中的PunktSentenceTokenizer实例,该实例已经过训练,因此非常清楚在哪些字符和标点符号处标记句子的结尾和开头。代码#2: PunktSentenceTokenizer当我们有大量数据时,使用它是有效的。
import nltk.data
# Loading PunktSentenceTokenizer using English pickle file
tokenizer = nltk.data.load('tokenizers/punkt/PY3/english.pickle')
tokenizer.tokenize(text)
输出 :
['Hello everyone.',
'Welcome to GeeksforGeeks.',
'You are studying NLP article']
代码#3:标记不同语言的句子——也可以使用除英语以外的不同pickle文件对不同语言的句子进行标记。
import nltk.data
spanish_tokenizer = nltk.data.load('tokenizers/punkt/PY3/spanish.pickle')
text = 'Hola amigo. Estoy bien.'
spanish_tokenizer.tokenize(text)
输出 :
['Hola amigo.',
'Estoy bien.']
代码 #4:单词标记化——在一个句子中拆分单词。
from nltk.tokenize import word_tokenize
text = "Hello everyone. Welcome to GeeksforGeeks."
word_tokenize(text)
输出 :
['Hello', 'everyone', '.', 'Welcome', 'to', 'GeeksforGeeks', '.']
word_tokenize是如何工作的?
word_tokenize()函数是一个包装函数,它在TreebankWordTokenizer class的实例上调用 tokenize()。代码 #5:使用TreebankWordTokenizer
from nltk.tokenize import TreebankWordTokenizer
tokenizer = TreebankWordTokenizer()
tokenizer.tokenize(text)
输出 :
['Hello', 'everyone.', 'Welcome', 'to', 'GeeksforGeeks', '.']
这些标记器通过使用标点符号和空格分隔单词来工作。正如上面代码输出中提到的,它不会丢弃标点符号,允许用户在预处理时决定如何处理标点符号。代码 #6: PunktWordTokenizer –它不会将标点符号与单词分开。
from nltk.tokenize import PunktWordTokenizer
tokenizer = PunktWordTokenizer()
tokenizer.tokenize("Let's see how it's working.")
输出 :
['Let', "'s", 'see', 'how', 'it', "'s", 'working', '.']
代码#6: WordPunctTokenizer它将标点符号与单词分开。
from nltk.tokenize import WordPunctTokenizer
tokenizer = WordPunctTokenizer()
tokenizer.tokenize("Let's see how it's working.")
输出 :
['Let', "'", 's', 'see', 'how', 'it', "'", 's', 'working', '.']
代码 #7:使用正则表达式
from nltk.tokenize import RegexpTokenizer
tokenizer = RegexpTokenizer("[\w']+")
text = "Let's see how it's working."
tokenizer.tokenize(text)
输出 :
["Let's", 'see', 'how', "it's", 'working']
代码 #7:使用正则表达式
from nltk.tokenize import regexp_tokenize
text = "Let's see how it's working."
regexp_tokenize(text, "[\w']+")
输出 :
["Let's", 'see', 'how', "it's", 'working']