自然语言处理 |单词搭配
搭配是两个或多个经常一起出现的词,例如 – United States 。在 United 之后还有许多其他词,例如 United Kingdom 和 United Airlines。与自然语言处理的许多方面一样,上下文非常重要。对于搭配,上下文就是一切。
在搭配的情况下,上下文将是单词列表形式的文档。在这个单词列表中发现搭配意味着找到在整个文本中频繁出现的常用短语。 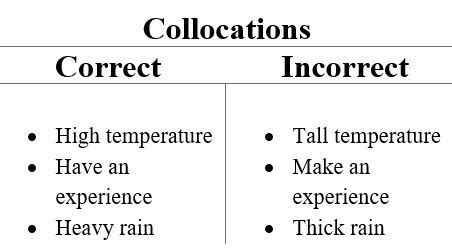
链接到数据 – Monty Python和圣杯脚本
代码 #1:加载库
from nltk.corpus import webtext
# use to find bigrams, which are pairs of words
from nltk.collocations import BigramCollocationFinder
from nltk.metrics import BigramAssocMeasures
代码#2:让我们找到搭配
# Loading the data
words = [w.lower() for w in webtext.words(
'C:\\Geeksforgeeks\\python_and_grail.txt')]
biagram_collocation = BigramCollocationFinder.from_words(words)
biagram_collocation.nbest(BigramAssocMeasures.likelihood_ratio, 15)
输出 :
[("'", 's'),
('arthur', ':'),
('#', '1'),
("'", 't'),
('villager', '#'),
('#', '2'),
(']', '['),
('1', ':'),
('oh', ', '),
('black', 'knight'),
('ha', 'ha'),
(':', 'oh'),
("'", 're'),
('galahad', ':'),
('well', ', ')]
正如我们在上面的代码中看到的那样,以这种方式查找托管不是很有用。因此,下面的代码是通过添加单词过滤器来删除标点符号和停用词的改进版本。代码#3:
from nltk.corpus import stopwords
stopset = set(stopwords.words('english'))
filter_stops = lambda w: len(w) < 3 or w in stopset
biagram_collocation.apply_word_filter(filter_stops)
biagram_collocation.nbest(BigramAssocMeasures.likelihood_ratio, 15)
输出 :
[('black', 'knight'),
('clop', 'clop'),
('head', 'knight'),
('mumble', 'mumble'),
('squeak', 'squeak'),
('saw', 'saw'),
('holy', 'grail'),
('run', 'away'),
('french', 'guard'),
('cartoon', 'character'),
('iesu', 'domine'),
('pie', 'iesu'),
('round', 'table'),
('sir', 'robin'),
('clap', 'clap')]
它在代码中是如何工作的?
- BigramCollocationFinder构造了两个频率分布:
- 每个单词一个
- 另一个用于二元组。
- 频率分布基本上是一个增强的Python字典,其中键是被计数的,值是计数。
- 任何过滤功能通过消除任何不通过过滤器的单词来减小大小
- 使用过滤函数来消除所有只有一个或两个字符的单词以及所有英语停用词,从而获得更清晰的结果。
- 过滤后,搭配查找器准备查找搭配。
代码#4:使用三元组而不是成对。
# Loading Libraries
from nltk.collocations import TrigramCollocationFinder
from nltk.metrics import TrigramAssocMeasures
# Loading data - text file
words = [w.lower() for w in webtext.words(
'C:\Geeksforgeeks\\python_and_grail.txt')]
trigram_collocation = TrigramCollocationFinder.from_words(words)
trigram_collocation.apply_word_filter(filter_stops)
trigram_collocation.apply_freq_filter(3)
trigram_collocation.nbest(TrigramAssocMeasures.likelihood_ratio, 15)
输出 :
[('clop', 'clop', 'clop'),
('mumble', 'mumble', 'mumble'),
('squeak', 'squeak', 'squeak'),
('saw', 'saw', 'saw'),
('pie', 'iesu', 'domine'),
('clap', 'clap', 'clap'),
('dona', 'eis', 'requiem'),
('brave', 'sir', 'robin'),
('heh', 'heh', 'heh'),
('king', 'arthur', 'music'),
('hee', 'hee', 'hee'),
('holy', 'hand', 'grenade'),
('boom', 'boom', 'boom'),
('...', 'dona', 'eis'),
('already', 'got', 'one')]