特征子集选择过程
特征选择是任何机器学习过程中最关键的预处理活动。它旨在选择对机器学习活动做出最有意义贡献的属性或特征子集。为了理解它,让我们考虑一个小例子,即根据类似学生的过去信息预测学生的体重,这些信息是在“学生体重”数据集中捕获的。该数据集具有卷号、年龄、身高和体重等 04 个特征。卷号对学生的体重没有影响,因此我们取消了此功能。所以现在新的数据集将只有 03 个特征。预计数据集的这个子集将提供比完整集更好的结果。 Age Weight Weight 12 1.1 23 11 1.05 21.6 13 1.2 24.7 11 1.07 21.3 14 1.24 25.2 12 1.12 23.4
上述数据集是一个简化的数据集。在继续之前,我们应该看看为什么我们降低了上述数据集的维数,或者高维数据有什么问题?
高维是指某些数据集中存在大量变量或属性或特征,在 DNA 分析、地理信息系统 (GIS) 等领域更是如此。它有时可能有数百或数千个维度,这是不好的从机器学习方面来看,因为它可能是任何 ML 算法处理的一个巨大挑战。另一方面,将需要大量的计算和大量的时间。此外,建立在大量特征上的模型可能很难理解。由于这些原因,有必要采用特征的子集而不是完整的集合。因此我们可以推断特征选择的目标是:
- 拥有更快、更具成本效益(对计算资源的需求更少)的学习模型
- 更好地理解生成数据的底层模型。
- 提高学习模型的效率。
影响特征选择的主要因素
一种。特征相关性:在监督学习的情况下,输入数据集(即训练数据集)附有类标签。模型是根据训练数据集引入的——因此引入的模型可以将类标签分配给新的、未标记的数据。每个预测变量,即预期贡献信息来决定类标签的值。如果变量没有提供任何信息,则称它是不相关的。如果对预测的信息贡献很小,则称该变量是弱相关的。对预测任务做出重大贡献的其余变量被称为强相关变量。
在无监督学习的情况下,没有训练数据集或标记数据。对相似的数据实例进行分组,并根据不同变量的值评估数据实例的相似性。某些变量不会为决定不同数据实例的相似性提供任何有用的信息。因此,这些变量对分组过程没有显着贡献。这些变量在无监督机器学习任务的上下文中被标记为无关变量。
我们可以通过一个真实的例子来理解这个概念:在文章的开头,我们取了一个学生的随机数据集。在那方面,卷数在预测学生的体重方面没有提供任何重要信息。同样,如果我们试图将具有相似学术能力的学生组合在一起, Roll No真的无法提供任何信息。因此,在对具有相似学业成绩的学生进行分组的情况下,变量Roll No是完全不相关的。当我们选择特征子集时,任何与机器学习任务上下文无关的特征都可能被拒绝。
湾。特征冗余:一个特征可能贡献的信息与一个或多个特征贡献的信息相似。例如,在学生数据集中,年龄和身高这两个特征都提供了相似的信息。这是因为随着年龄的增长,体重预计会增加。同样,随着身高的增加,体重也会增加。因此,在该问题的上下文中,年龄和身高提供了类似的信息。换句话说,无论特征高度是否存在,学习模型都会给出相同的结果。在这种一个特征与另一个特征相似的情况下,该特征在机器学习问题的上下文中被称为潜在冗余。
所有具有潜在冗余的特征都是最终特征子集中拒绝的候选者。只有一组潜在冗余特征中的少数代表性特征被认为是最终特征子集的一部分。所以简而言之,特征选择的主要目标是去除所有不相关的特征,并选取可能冗余的特征的代表性子集。这导致在特定学习任务的上下文中有意义的特征子集。
特征相关性和冗余度的度量
一种。特征相关性度量:在监督学习的情况下,互信息被认为是衡量特征信息贡献的良好度量,以决定类标签的值。这就是为什么它是一个特征与类变量相关性的一个很好的指标。一个特征的互信息值越高,这个特征就越相关。互信息可以计算如下:
其中,类的边际熵, (
特征“x”的边际熵, 
K = 类数, C = 类变量, f = 采用离散值的特征集。在无监督学习的情况下,没有类变量。因此,特征到类的互信息不能用来衡量特征的信息贡献。在无监督学习的情况下,对所有特征计算一次没有一个特征的特征集的熵。然后这些特征按从一个特征得到的信息增益的降序排列 选择特征的百分比(β值是算法的设计参数)作为相关特征。使用以下香农公式计算特征 f 的熵:
选择特征的百分比(β值是算法的设计参数)作为相关特征。使用以下香农公式计算特征 f 的熵:

仅用于采用离散值的特征。对于连续特征,应该先用离散化来估计概率 p(f=x)。
湾。特征冗余度量:信息贡献相似度有多种度量,主要有:
- 基于相关性的措施
- 基于距离的测量
- 其他基于系数的测量
1.基于相关的相似性度量
相关性是两个随机变量之间线性相关性的度量。皮尔逊乘积相关系数是两个随机变量之间最流行和公认的测量相关性之一。对于两个随机特征变量 F 1和 F 2 ,皮尔逊系数定义为:


 在哪里
在哪里
在哪里

相关值范围在 +1 和 -1 之间。相关性为 1 (+/-) 表示完全相关。如果相关性为零,则特征似乎没有线性关系。一般对于所有的特征选择问题,都采用一个阈值来判断两个特征是否具有足够的相似度。
2. 基于距离的相似度测量
最常见的距离度量是欧几里得距离,两个特征 F 1和 F 2之间的计算如下:

其中特征表示 n 维数据集。让我们考虑该数据集有两个特征,即正在考虑的主题(F 1 )和标记(F 2 )。两个特征之间的欧几里得距离将按如下方式计算: 2 6 -4 16 3 5.5 -2.5 6.25 6 4 2 4 7 2.5 4.5 20.25 8 3 5 25 6 5.5 0.5 0.25 6 7 -1 1 7 6 1 1 8 6 2 4 9 7 2 4Subjects (F1) Marks (F2) (F1 -F2) (F1 -F2)2
欧几里得距离的更广义形式是Minkowski 距离,测量为
Minkowski 距离采用欧几里得距离(也称为L 2 norm )的形式,其中 r = 2。在 r=1 时,它采用曼哈顿距离(也称为L 1 norm )的形式: 
3. 其他相似性度量
Jaccard 指数/系数用于衡量两个特征之间的相异性,与 Jaccard 指数互补。对于具有二进制值的两个特征,Jaccard 指数测量为: 
在哪里 = 两个特征都为 1 的案例数,
= 两个特征都为 1 的案例数,
 = 特征 1 的值为 0 且特征 2 的值为 1 的案例数,
= 特征 1 的值为 0 且特征 2 的值为 1 的案例数,
 = 特征 1 的值为 1 且特征 2 的值为 0 的案例数。
= 特征 1 的值为 1 且特征 2 的值为 0 的案例数。
杰卡德距离: 
让我们举个例子来更好地理解它。考虑两个特征,F 1和 F 2具有值 (0, 1, 1, 0, 1, 0, 1, 0) 和 (1, 1, 0, 0, 1, 0, 0, 0)。
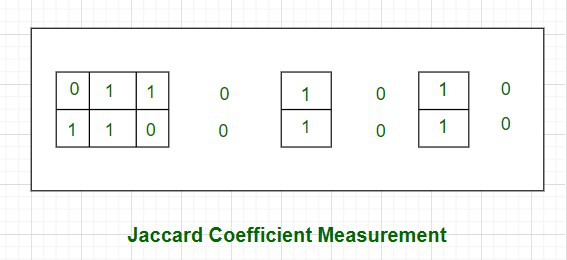
如上图所示,两个值都为 0 的情况已被无边界排除——这表明在计算 Jaccard 系数时将排除它们。
F 1和 F 2的 Jaccard 系数,J = 
因此,这两个特征之间的 Jaccard 距离为 d j = (1 – 0.4) = 0.6
注意:使用相似度系数计算的另一种相似度度量是余弦相似度。为了便于理解,让我们举一个文本分类问题的例子。首先需要将文本转换为特征,其中单词标记是特征,并且单词在文档中出现的次数作为每行中的值。这样的文本数据集中有数千个特征。然而,数据集本质上是稀疏的,因为只有几个单词出现在文档中,因此出现在数据集的一行中。所以每一行都有很少的非零值。但是,非零值可以是任何整数值,因为同一个单词可以出现任意次数。此外,考虑到数据集的稀疏性,需要忽略 0-0 匹配。余弦相似度是文本分类中最流行的度量之一,计算如下:
其中,xy 是 x 和 y 的向量点积 = 
 和
和
所以让我们计算 x 和 y 的余弦相似度,其中 x = (2,4,0,0,2,1,3,0,0) 和 y = (2,1,0,0,3,2,1 ,0,1)。在这种情况下,x 和 y 的点积将是xy = 2*2 + 4*1 + 0*0 + 0*0 + 2*3 + 1*2 + 3*1 + 0*0 + 0*1 = 19.


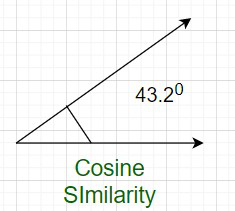
余弦相似度测量 x 和 y 向量之间的角度。因此,如果余弦相似度的值为 1,则 x 和 y 之间的角度为 0 度,这意味着 x 和 y 除了幅度之外是相同的。如果余弦相似度为 0,则 x 和 y 之间的角度为 90 0 。因此,它们没有任何相似之处。在上面的例子中,角度是 43.2 0 。
即使在所有这些步骤之后,还有一些步骤。你可以通过下面的流程图来理解:

特征选择过程
成功完成此循环后,我们得到了所需的功能,并且我们最终也对其进行了测试。