PySpark – GroupBy 并按降序对 DataFrame 进行排序
在本文中,我们将讨论如何对 PySpark DataFrame 进行分组,然后按降序对其进行排序。
使用的方法
- groupBy(): pyspark 中的 groupBy()函数用于对 DataFrame 上的相同分组数据,同时对分组数据执行聚合函数。
Syntax: DataFrame.groupBy(*cols)
Parameters:
- cols→ Columns by which we need to group data
- sort(): sort()函数用于对一列或多列进行排序。默认情况下,它按升序排序。
Syntax: sort(*cols, ascending=True)
Parameters:
- cols→ Columns by which sorting is needed to be performed.
- PySpark DataFrame 还提供orderBy()函数来对一列或多列进行排序。默认情况下,它按升序排序。
Syntax: orderBy(*cols, ascending=True)
Parameters:
- cols→ Columns by which sorting is needed to be performed.
- ascending→ Boolean value to say that sorting is to be done in ascending order
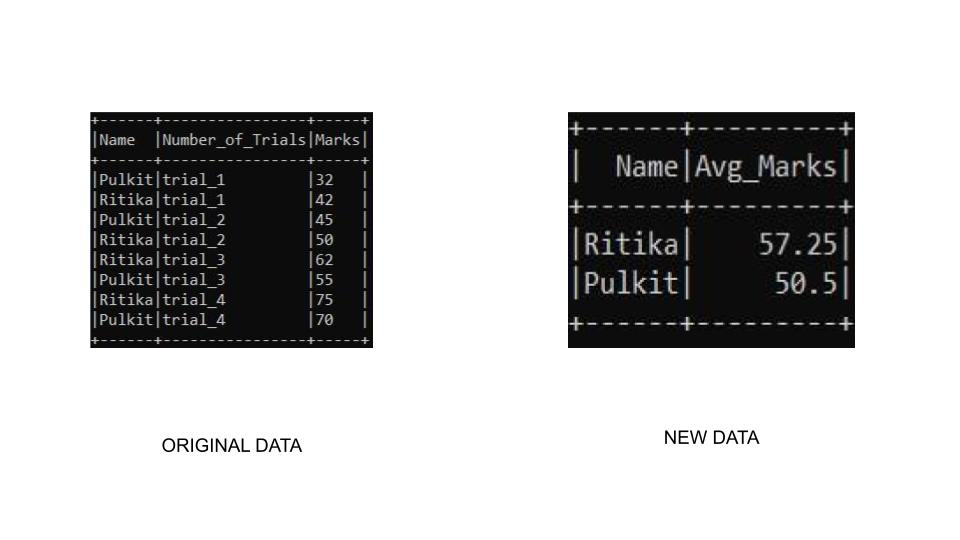
示例 1:在此示例中,我们将按名称和聚合标记对数据框进行分组。我们将使用 sort()函数对表进行排序,在该函数中我们将使用 col()函数和 desc()函数访问列以按降序对其进行排序。
Python3
# import the required modules
from pyspark.sql import SparkSession
from pyspark.sql.functions import avg, col, desc
# Start spark session
spark = SparkSession.builder.appName("GeeksForGeeks").getOrCreate()
# Define sample data
simpleData = [("Pulkit","trial_1",32),
("Ritika","trial_1",42),
("Pulkit","trial_2",45),
("Ritika","trial_2",50),
("Ritika","trial_3",62),
("Pulkit","trial_3",55),
("Ritika","trial_4",75),
("Pulkit","trial_4",70)
]
# define the schema
schema = ["Name","Number_of_Trials","Marks"]
# create a dataframe
df = spark.createDataFrame(data=simpleData, schema = schema)
# group by name and aggrigate using
# average marks sort the column using
# col and desc() function
df.groupBy("Name") \
.agg(avg("Marks").alias("Avg_Marks")) \
.sort(col("Avg_Marks").desc()) \
.show()
# stop spark session
spark.stop()Python3
# import the required modules
from pyspark.sql import SparkSession
from pyspark.sql.functions import avg, col, desc
# Start spark session
spark = SparkSession.builder.appName("Student_Info").getOrCreate()
# sample dataset
simpleData = [("Pulkit","trial_1",32),
("Ritika","trial_1",42),
("Pulkit","trial_2",45),
("Ritika","trial_2",50),
("Ritika","trial_3",62),
("Pulkit","trial_3",55),
("Ritika","trial_4",75),
("Pulkit","trial_4",70)
]
# define the schema to be used
schema = ["Name","Number_of_Trials","Marks"]
# create the dataframe
df = spark.createDataFrame(data=simpleData, schema = schema)
# perform groupby operation on name table
# aggrigate marks and give it a new name
# sort in descending order by avg_marks
df.groupBy("Name") \
.agg(avg("Marks").alias("Avg_Marks")) \
.sort(desc("Avg_Marks")) \
.show()
# stop sparks session
spark.stop()Python3
# import required modules
from pyspark.sql import SparkSession
from pyspark.sql.functions import avg, col, desc
# Start spark session
spark = SparkSession.builder.appName("Student_Info").getOrCreate()
# sample dataset
simpleData = [("Pulkit","trial_1",32),
("Ritika","trial_1",42),
("Pulkit","trial_2",45),
("Ritika","trial_2",50),
("Ritika","trial_3",62),
("Pulkit","trial_3",55),
("Ritika","trial_4",75),
("Pulkit","trial_4",70)
]
# define the schema
schema = ["Name","Number_of_Trials","Marks"]
# create a dataframe
df = spark.createDataFrame(data=simpleData, schema = schema)
df.groupBy("Name")\
.agg(avg("Marks").alias("Avg_Marks"))\
.orderBy("Avg_Marks", ascending=False)\
.show()
# stop sparks session
spark.stop()输出:
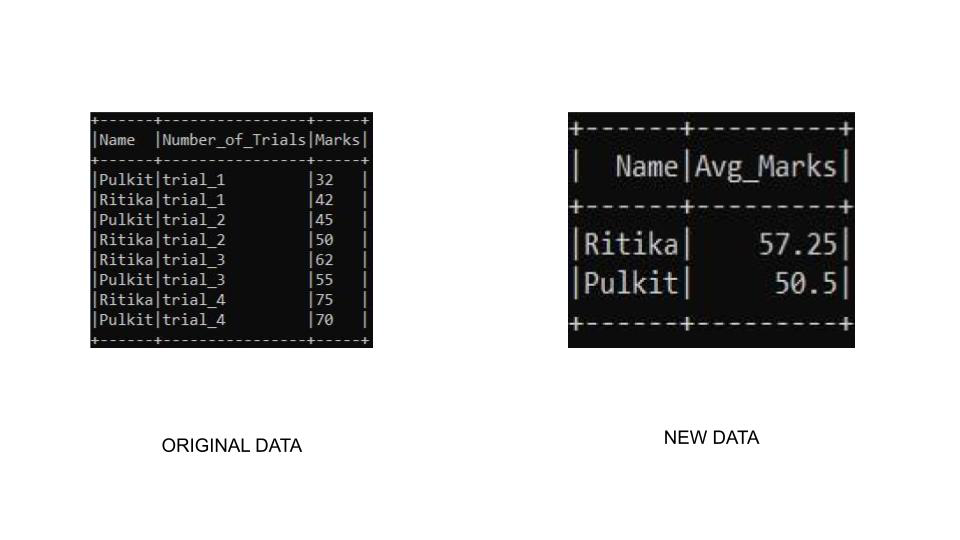
示例 2:在此示例中,我们将按名称和聚合标记对数据框进行分组。我们将使用 sort()函数对表进行排序,在该函数中我们将访问 desc()函数的列以按降序对其进行排序。
蟒蛇3
# import the required modules
from pyspark.sql import SparkSession
from pyspark.sql.functions import avg, col, desc
# Start spark session
spark = SparkSession.builder.appName("Student_Info").getOrCreate()
# sample dataset
simpleData = [("Pulkit","trial_1",32),
("Ritika","trial_1",42),
("Pulkit","trial_2",45),
("Ritika","trial_2",50),
("Ritika","trial_3",62),
("Pulkit","trial_3",55),
("Ritika","trial_4",75),
("Pulkit","trial_4",70)
]
# define the schema to be used
schema = ["Name","Number_of_Trials","Marks"]
# create the dataframe
df = spark.createDataFrame(data=simpleData, schema = schema)
# perform groupby operation on name table
# aggrigate marks and give it a new name
# sort in descending order by avg_marks
df.groupBy("Name") \
.agg(avg("Marks").alias("Avg_Marks")) \
.sort(desc("Avg_Marks")) \
.show()
# stop sparks session
spark.stop()
输出:

示例 3:在本示例中,我们将按名称和聚合标记对数据框进行分组。我们将使用 orderBy()函数对表进行排序,在该函数中,我们将升序参数作为 False 传递,以按降序对数据进行排序。
蟒蛇3
# import required modules
from pyspark.sql import SparkSession
from pyspark.sql.functions import avg, col, desc
# Start spark session
spark = SparkSession.builder.appName("Student_Info").getOrCreate()
# sample dataset
simpleData = [("Pulkit","trial_1",32),
("Ritika","trial_1",42),
("Pulkit","trial_2",45),
("Ritika","trial_2",50),
("Ritika","trial_3",62),
("Pulkit","trial_3",55),
("Ritika","trial_4",75),
("Pulkit","trial_4",70)
]
# define the schema
schema = ["Name","Number_of_Trials","Marks"]
# create a dataframe
df = spark.createDataFrame(data=simpleData, schema = schema)
df.groupBy("Name")\
.agg(avg("Marks").alias("Avg_Marks"))\
.orderBy("Avg_Marks", ascending=False)\
.show()
# stop sparks session
spark.stop()
输出: