编译器设计中的阶段分组
编译器是将高级语言翻译成机器可理解形式的软件。通常,编译器由六个状态组成,高级语言的输入代码(也称为源代码)一个接一个地通过每个状态,每个状态处理代码,产生机器可理解的代码或目标代码作为输出.
编译器的这六种状态在一次编译或二次编译的基础上进一步划分为阶段,状态如下:
- 词法分析
- 语法分析
- 语义分析
- 中间代码生成
- 代码优化
- 代码生成
编译器中的阶段:
一般来说,阶段分为两部分:
1. 前端阶段:前端由源语言相关和目标机器独立的那些阶段或阶段的一部分组成。这些通常包括词法分析、语义分析、句法分析、符号表创建和中间代码生成。前端部分也可以包含一小部分代码优化。前端部分还包括与每个阶段一起进行的错误处理。
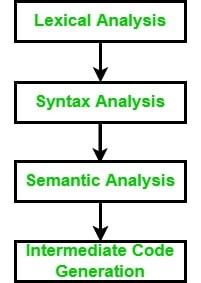
前端阶段
2. 后端阶段:依赖于目标机器而不依赖于源语言的编译器部分包含在后端中。在后端,还包括代码生成和代码优化阶段的必要功能,以及错误处理和符号表操作。
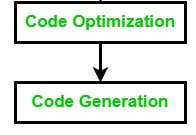
后端阶段
通过编译器:
一个过程是一个组件,其中编译器的一个或多个阶段的部分在实现编译器时组合在一起。一个 pass 读取或扫描源程序的指令或前一个 pass 产生的输出,这会根据其阶段进行必要的转换。
通行证一般有两种
- 一通
- 两次通过
分组
几个阶段组合在一起 传递给一个传递,以便它可以读取输入文件并写入输出文件。
- One-Pass – 在 One-pass 中,所有阶段都归为一个阶段。六个阶段包含在一个通道中。
- 双通道——在双通道中,阶段分为两部分,即编译器的分析或前端部分和编译器的综合部分或后端部分。
One Pass 编译器的目的
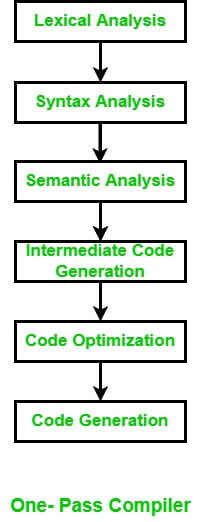
一通编译器
一次编译器生成机器指令结构,因为它看起来像指令流,然后将这些指南的机器地址汇总到生成机器地址后要回补的方向列表。用于通过程序一次。每当处理线源时,都会对其进行检查并删除令牌。
两遍编译器的目的
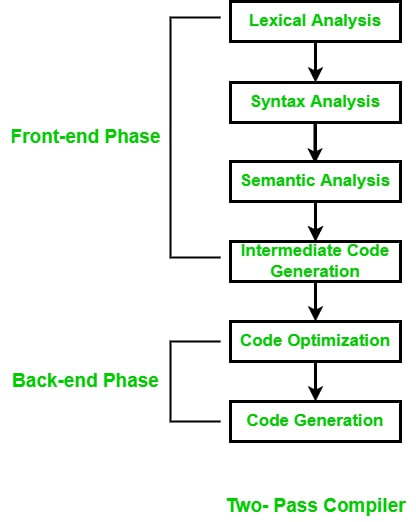
两遍编译器
两遍编译器利用其第一遍进入其符号表中的标识符列表以及与这些标识符相关的内存区域。然后,此时,第二遍将助记操作代码替换为其机器语言等效项,并将标识符的使用替换为其机器地址。在第二遍中,编译器可以读取第一遍传递的结果文档,组装句法树并传递句法检查。此阶段的结果是包含语法树的记录。
减少通过次数
编译器的各个阶段必须出于正当的理由进行分组:分组到单个阶段可以使安排更快,因为编译器不需要移动到各个模块或阶段来获得交互引入需求。减少传递次数与增加读取和写入中间文件的时间效率成反比。在将阶段分组为一次传递时,整个程序必须保存在内存中,以保证每个阶段都有适当的数据流,因为与过去阶段交付的数据相比,一个阶段可能需要意外请求中的数据。源程序或目标程序的内部描述是不同的。因此,内存的内部结构可能大于输入和输出。