先决条件–编译器设计简介
我们基本上有两个阶段的编译器,即分析阶段和综合阶段。分析阶段从给定的源代码创建中间表示。综合阶段从中间表示创建等效的目标程序。
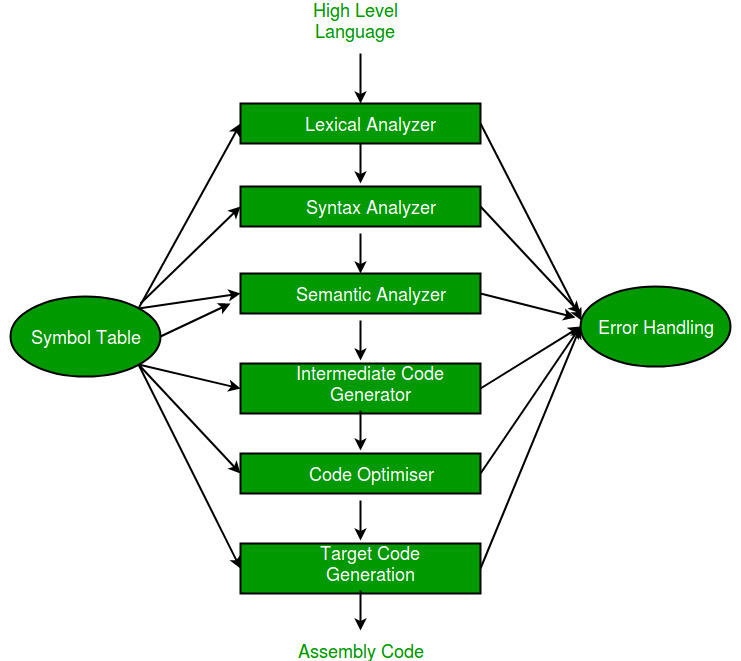
符号表–它是编译器正在使用和维护的数据结构,包括所有标识符的名称及其类型。它可以帮助编译器函数,顺利通过快速查找标识符。
对源程序的分析主要分为三个阶段。他们是:
- 线性分析
这涉及扫描阶段,其中从左到右读取字符流。然后将其分为具有集体意义的各种标记。 - 层次分析-
在此分析阶段中,基于集体含义,将令牌按层次结构分类为嵌套组。 - 语义分析
此阶段用于检查源程序的组件是否有意义。
编译器有两个模块,即前端和后端。词法分析器,语义分析器,语法分析器和中间代码生成器的前端组成。其余部分组装成后端。
- 词法分析器–
也称为扫描仪。它采用预处理器的输出(执行文件包含和宏扩展)作为纯高级语言的输入。它从源程序读取字符并将它们分组为词素(“一起”的字符序列)。每个词素对应一个令牌。标记由词法分析器可以理解的正则表达式定义。它还消除了词法错误(例如,错误的字符),注释和空白。 - 语法分析器–有时称为解析器。它构造了解析树。它一个接一个地获取所有令牌,并使用上下文无关语法构造解析树。
为什么要语法?
编程规则可以在一些产品中完全体现。使用这些生成的结果,我们可以表示程序实际上是什么。必须检查输入是否为所需格式。
解析树也称为派生树。解析树通常构造为检查给定语法中的歧义。有一些与派生树相关的规则。- 任何标识符都是表达式
- 任何数字都可以称为表达式
- 在给定表达式中执行任何操作将始终生成一个表达式。例如,两个表达式的总和也是一个表达式。
- 解析树可以被压缩以形成语法树
如果输入不符合语法,则可以在此级别检测到语法错误。

- 语义分析器–验证语法分析树是否有意义。此外,它还产生了一个经过验证的解析树。它还进行类型检查,标签检查和流控制检查。
- 中间代码生成器–它生成中间代码,这种形式可以很容易地由机器执行。我们有许多流行的中间代码。示例–三个地址代码等。使用依赖于平台的最后两个阶段将中间代码转换为机器语言。
直到中间代码,那里的每个编译器都一样,但是之后,它取决于平台。要构建一个新的编译器,我们不需要从头开始构建它。我们可以从已经存在的编译器中获取中间代码,并构建最后两部分。
- 代码优化器–转换代码,使其消耗更少的资源并产生更快的速度。被转换的代码的含义没有改变。优化可以分为两种类型:与机器有关和与机器无关。
- 目标代码生成器–目标代码生成器的主要目的是编写机器可以理解的代码,并注册分配,指令选择等。输出取决于汇编程序的类型。这是编译的最后阶段。将优化的代码转换为可重定位的机器代码,然后将其形成链接器和加载器的输入。
所有这六个阶段都与符号表管理器和错误处理程序相关联,如上面的框图所示。