布隆过滤器用于集合成员资格,确定成员是否存在于集合中。布隆过滤器由伯顿·布鲁姆( Burton H.Bloom)于1970年在一篇名为《带有允许误差的散列编码中的时空权衡》中提出。布隆过滤器是一种概率数据结构,适用于哈希编码方法(类似于HashTable)。
什么时候需要布隆过滤器?
请考虑以下情况之一:
- 假设我们有一些元素的列表,并且我们想检查给定的元素是否存在?
- 考虑您正在使用电子邮件服务,并且正在尝试使用给定用户名已经存在或不存在的功能来实现注册端点?
- 假设您给定了一组列入黑名单的IP,并且想过滤掉给定IP是不是列入黑名单的IP?
如果没有Bloom Filter的帮助,可以解决这些问题吗?
让我们尝试使用HashSet解决这些问题
import java.util.HashSet;
import java.util.Set;
public class SetDemo {
public static void main(String[] args)
{
Set blackListedIPs
= new HashSet<>();
blackListedIPs.add("192.170.0.1");
blackListedIPs.add("75.245.10.1");
blackListedIPs.add("10.125.22.20");
// true
System.out.println(
blackListedIPs
.contains(
"75.245.10.1"));
// false
System.out.println(
blackListedIPs
.contains(
"101.125.20.22"));
}
}
true
false
为什么像HashSet或HashTable这样的数据结构会失败?
当我们的数据集有限时,HashSet或HashTable可以很好地工作,但当我们处理大量数据集时可能不合适。对于大数据集,需要大量时间和大量内存。
像数据结构一样,数据集的大小与HashSet的插入时间
----------------------------------------------
|Number of UUIDs Insertion Time(ms) |
----------------------------------------------
|10 <1 |
|100 3 |
|1, 000 58 |
|10, 000 122 |
|100, 000 836 |
|1, 000, 000 7395 |
----------------------------------------------
像数据结构这样的HashSet的数据集大小与内存(JVM堆)的大小
----------------------------------------------
|Number of UUIDs JVM heap used(MB) |
----------------------------------------------
|10 <2 |
|100 <2 |
|1, 000 3 |
|10, 000 9 |
|100, 000 37 |
|1, 000, 000 264 |
-----------------------------------------------
因此很明显,如果我们有大量的数据集,那么像Set或HashTable这样的常规数据结构是不可行的,在这里,将使用Bloom过滤器。请参阅本文以获取有关两者之间比较的更多详细信息:Bloom过滤器和Hashtable之间的区别
如何借助Bloom Filter解决这些问题?
让我们采用大小为N的位数组(在这里为24),并用二进制零初始化每个位,现在采用一些哈希函数(您可以根据需要选择任意数量,这里为示例说明采用了两个哈希函数)。

- 现在,将您必须拥有的第一个IP传递给两个hash函数,该函数会生成一些如下所示的随机数
hashFunction_1(192.170.0.1) : 2 hashFunction_2(192.170.0.1) : 6现在,转到索引2和6,并将该位标记为二进制1。

- 现在,通过您拥有的第二个IP,然后执行相同的步骤。
hashFunction_1(75.245.10.1) : 4 hashFunction_2(75.245.10.1) : 10现在,转到索引4和10,并将该位标记为二进制1。

- 同样,将第三个IP传递给both哈希函数,并假设您获得了以下哈希函数输出
hashFunction_1(10.125.22.20) : 10 hashFunction_2(10.125.22.20) : 19‘
现在,转到索引10和19并将其标记为二进制1,这里索引10已被先前的条目标记,因此只需将索引19标记为二进制1。
现在,该检查数据集中是否存在IP,
- 测试输入#1
假设我们要检查IP 75.245.10.1 。使用与添加上述输入相同的两个哈希函数传递此IP。hashFunction_1(75.245.10.1) : 4 hashFunction_2(75.245.10.1) : 10现在,转到索引并检查该位,如果索引4和10都用二进制1标记,则IP 75.245.10.1存在于集合中,否则就没有数据集。
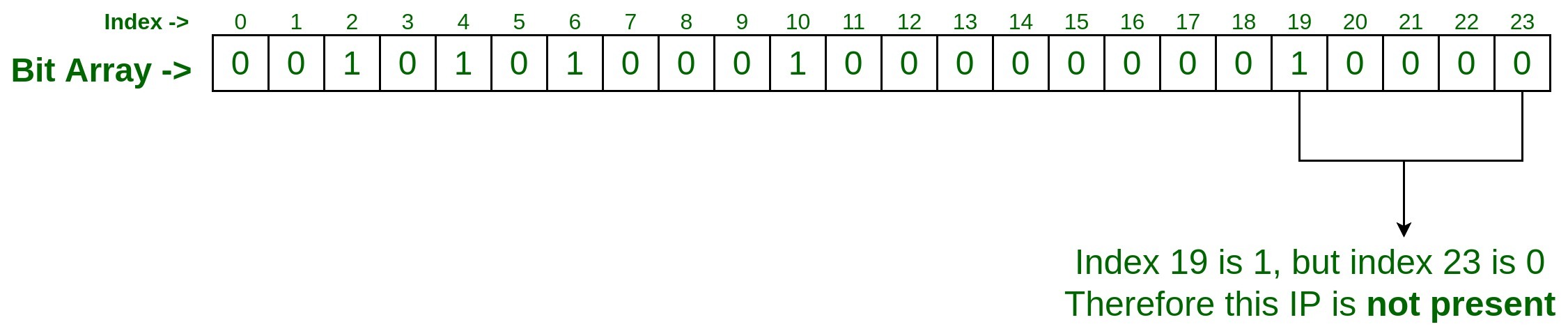
- 测试输入2
假设我们要检查集合中是否存在IP 75.245.20.30 ?因此,过程将是相同的,使用与添加上述输入相同的两个哈希函数传递此IP。hashFunction_1(75.245.20.30) : 19 hashFunction_2(75.245.20.30) : 23由于在索引19处将其设置为1,但在索引23处将其设置为0,因此我们可以说给定IP 75.245.20.30不存在于集合中。

为什么Bloom Filter是概率数据结构?
让我们通过另一个测试来了解这一点,这次考虑使用IP 101.125.20.22,并检查其是否存在于设备集中。将此传递给两个哈希函数。考虑我们的哈希函数结果,如下所示。
hashFunction_1(101.125.20.22) : 19
hashFunction_2(101.125.20.22) : 2
现在,访问设置为1的索引19和2,它表示给定的IP 101.125.20.22存在于该集合中。

但是,在将IP添加到位阵列时,已经在数据集中对IP 101.125.20.22进行了处理。这就是所谓的误报:
Expected Output: No
Actual Output: Yes (False Positive)
在这种情况下,索引2和19由其他输入而不是由该IP 101.125.20.22设置为1。这就是所谓的碰撞,这就是为什么它是概率性的,发生概率不是100%。
布隆过滤器会带来什么?
- 当布隆过滤器说,一个元素不存在这是肯定不存在。它保证100%的给定元素在集合中不可用,因为哈希函数给定的索引位中的任何一个都将设置为0。
- 但是当Bloom过滤器说给定元素存在时,它并不是100%肯定的,因为由于冲突,散列函数给定的所有索引位都可能已被其他输入设置为1的机会。
如何从布隆过滤器获得100%的准确结果?
好吧,这只能通过采用更多数量的哈希函数来实现。由于发生碰撞的机会较少,我们采用的哈希函数数量越多,得到的结果越准确。
布隆过滤器的时间和空间复杂度
假设我们有大约4000万个数据集,并且正在使用H哈希函数,则:
Time complexity: O(H), where H is the number of hash functions used
Space complexity: 159 Mb (For 40 million data sets)
Case of False positive: 1 mistake per 10 million (for H = 23)
使用Guava库在Java实现Bloom过滤器:
我们可以使用Guava提供的Java库来实现Bloom过滤器。
- 包括以下Maven依赖项:
com.google.guava guava 19.0 - 编写以下代码来实现布隆过滤器:
// Java program to implement // Bloom Filter using Guava Library import java.nio.charset.Charset; import com.google.common.hash.BloomFilter; import com.google.common.hash.Funnels; public class BloomFilterDemo { public static void main(String[] args) { // Create a Bloom Filter instance BloomFilterblackListedIps = BloomFilter.create( Funnels.stringFunnel( Charset.forName("UTF-8")), 10000); // Add the data sets blackListedIps.put("192.170.0.1"); blackListedIps.put("75.245.10.1"); blackListedIps.put("10.125.22.20"); // Test the bloom filter System.out.println( blackListedIps .mightContain( "75.245.10.1")); System.out.println( blackListedIps .mightContain( "101.125.20.22")); } } 输出:
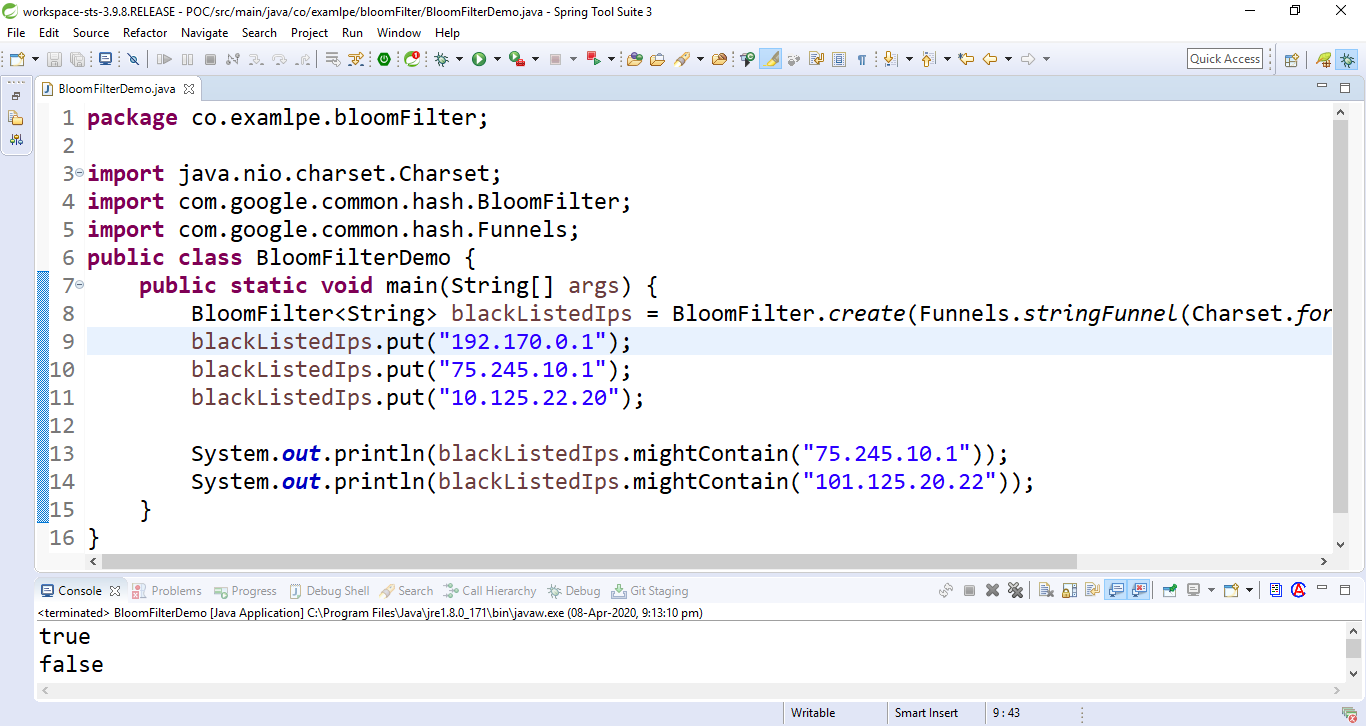
布隆过滤器输出
Note: The above Java code may return a 3% false-positive probability by default.
- 降低假阳性率
在布隆过滤器对象创建中引入另一个参数,如下所示:
BloomFilter blackListedIps = BloomFilter.create(Funnels.stringFunnel(Charset.forName("UTF-8")), 10000, 0.005);
BloomFilter blackListedIps = BloomFilter.create(Funnels.stringFunnel(Charset.forName("UTF-8")), 10000, 0.005);
BloomFilter blackListedIps = BloomFilter.create(Funnels.stringFunnel(Charset.forName("UTF-8")), 10000, 0.005);现在,假阳性概率已从0.03降低至0.005 。但是调整此参数会对Bloom过滤器的一侧产生影响。
减少误报概率的效果:
让我们从散列函数,数组位,时间复杂度和空间复杂度方面分析这种影响。
- 让我们看一下不同数据集的插入时间。
----------------------------------------------------------------------------- |Number of UUIDs | Set Insertion Time(ms) | Bloom Filter Insertion Time(ms) | ----------------------------------------------------------------------------- |10 <1 71 | |100 3 17 | |1, 000 58 84 | |10, 000 122 272 | |100, 000 836 556 | |1, 000, 000 7395 5173 | ------------------------------------------------------------------------------ - 现在,让我们看一下内存(JVM堆)
-------------------------------------------------------------------------- |Number of UUIDs | Set JVM heap used(MB) | Bloom filter JVM heap used(MB) | -------------------------------------------------------------------------- |10 <2 0.01 | |100 <2 0.01 | |1, 000 3 0.01 | |10, 000 9 0.02 | |100, 000 37 0.1 | |1, 000, 000 264 0.9 | --------------------------------------------------------------------------- - 位计数
---------------------------------------------- |Suggested size of Bloom Filter | Bit count | ---------------------------------------------- |10 40 | |100 378 | |1, 000 3654 | |10, 000 36231 | |100, 000 361992 | |1, 000, 000 3619846 | ----------------------------------------------- - 用于各种假阳性概率的哈希函数数:
----------------------------------------------- |Suggested FPP of Bloom Filter | Hash Functions| ----------------------------------------------- |3% 5 | |1% 7 | |0.1% 10 | |0.01% 13 | |0.001% 17 | |0.0001% 20 | ------------------------------------------------
结论:
因此可以说,在必须处理低内存消耗的大数据集的情况下,Bloom过滤器是一个不错的选择。同样,我们想要更准确的结果,必须增加哈希函数的数量。