- Python机器学习的数据预处理
- Python机器学习的数据预处理(1)
- 大数据和机器学习的区别
- 大数据和机器学习的区别(1)
- C++中的机器学习
- 机器学习 (1)
- 机器学习中的 P 值
- 机器学习中的 P 值(1)
- C++中的机器学习(1)
- Keras中的深度学习-数据预处理(1)
- Keras中的深度学习-数据预处理
- 机器学习 python (1)
- 机器学习 python 代码示例
- 如何获取用于机器学习的数据集(1)
- 如何获取用于机器学习的数据集
- 机器学习和数据科学(1)
- 机器学习和数据科学
- 机器学习 - 任何代码示例
- 什么是机器学习?
- 机器学习-什么是P值(1)
- 在机器学习中什么是“i” (1)
- 什么是机器学习?(1)
- 机器学习-什么是P值
- 学习 python 机器学习 - 任何代码示例
- 机器学习-什么是机器学习? -指导点(1)
- 机器学习-什么是机器学习? -指导点
- 数据挖掘中的数据预处理(1)
- 数据挖掘中的数据预处理
- 数据挖掘中的数据预处理(1)
📅 最后修改于: 2020-09-27 00:53:37 🧑 作者: Mango
机器学习中的数据预处理
数据预处理是准备原始数据并使之适合于机器学习模型的过程。这是创建机器学习模型的第一步,也是至关重要的一步。
在创建机器学习项目时,并非总是遇到整洁且格式化的数据的情况。而且,在对数据执行任何操作时,必须将其清理并以格式化的方式放置。因此,为此,我们使用数据预处理任务。
为什么我们需要数据预处理?
实际数据通常包含噪声,缺失值,并且可能采用无法使用的格式,无法直接用于机器学习模型。数据预处理是清理数据并使之适合于机器学习模型的必需任务,这也提高了机器学习模型的准确性和效率。
它涉及以下步骤:
- 获取数据集
- 导入库
- 导入数据集
- 查找丢失的数据
- 编码分类数据
- 将数据集分为训练和测试集
- 功能缩放
1)获取数据集
要创建机器学习模型,我们首先需要的是数据集,因为机器学习模型完全可以处理数据。以正确的格式收集的特定问题的数据称为数据集。
数据集可能出于不同目的具有不同的格式,例如,如果我们要创建用于业务目的的机器学习模型,则数据集将与肝病患者所需的数据集不同。因此,每个数据集都不同于另一个数据集。要在我们的代码中使用数据集,我们通常将其放入CSV文件中。但是,有时,我们可能还需要使用HTML或xlsx文件。
什么是CSV文件?
CSV代表“逗号分隔的值”文件;它是一种文件格式,可让我们保存表格数据,例如电子表格。这对于庞大的数据集很有用,并且可以在程序中使用这些数据集。
在这里,我们将使用演示数据集进行数据预处理,并且可以从以下位置下载实践数据集:“ https://www.superdatascience.com/pages/machine-learning。对于实际问题,我们可以在线下载数据集来自各种来源,例如https://www.kaggle.com/uciml/datasets、https://archive.ics.uci.edu/ml/index.php等。
我们还可以通过使用各种API和Python收集数据来创建数据集,并将其放入.csv文件中。
2)导入库
为了使用Python执行数据预处理,我们需要导入一些预定义的Python库。这些库用于执行某些特定的作业。我们将使用三个特定的库来进行数据预处理:
Numpy:Numpy Python库用于在代码中包括任何类型的数学运算。它是Python科学计算的基本软件包。它还支持添加大型多维数组和矩阵。因此,在Python,我们可以将其导入为:
import numpy as nm
在这里,我们使用了nm,它是Numpy的缩写,它将在整个程序中使用。
Matplotlib:第二个库是matplotlib,这是一个Python 2D绘图库,使用此库,我们需要导入一个子库pyplot。该库用于在Python为代码绘制任何类型的图表。它将按以下方式导入:
import matplotlib.pyplot as mpt
在这里,我们使用mpt作为该库的简称。
Pandas:最后一个库是Pandas库,它是最著名的Python库之一,用于导入和管理数据集。它是一个开放源代码的数据处理和分析库。它将按以下方式导入:
在这里,我们使用pd作为该库的简称。考虑下图:

3)导入数据集
现在,我们需要导入为机器学习项目收集的数据集。但是在导入数据集之前,我们需要将当前目录设置为工作目录。要在Spyder IDE中设置工作目录,我们需要执行以下步骤:
- 将您的Python文件保存在包含数据集的目录中。
- 转到Spyder IDE中的“文件资源管理器”选项,然后选择所需的目录。
- 单击F5按钮或运行选项以执行文件。
注意:我们可以将任何目录设置为工作目录,但是它必须包含所需的数据集。
在下图中,我们可以看到Python文件以及所需的数据集。现在,将当前文件夹设置为工作目录。

read_csv() 函数:
现在要导入数据集,我们将使用pandas库的read_csv() 函数 ,该函数用于读取csv文件并对其执行各种操作。使用此函数,我们可以在本地以及通过URL读取csv文件。
我们可以使用read_csv 函数 ,如下所示:
data_set= pd.read_csv('Dataset.csv')
在这里,data_set是用于存储数据集的变量的名称,并且在函数内部,我们传递了数据集的名称。一旦执行了以上代码行,它将成功将数据集导入到我们的代码中。我们还可以通过单击部分变量资源管理器来检查导入的数据集,然后双击data_set。考虑下图:
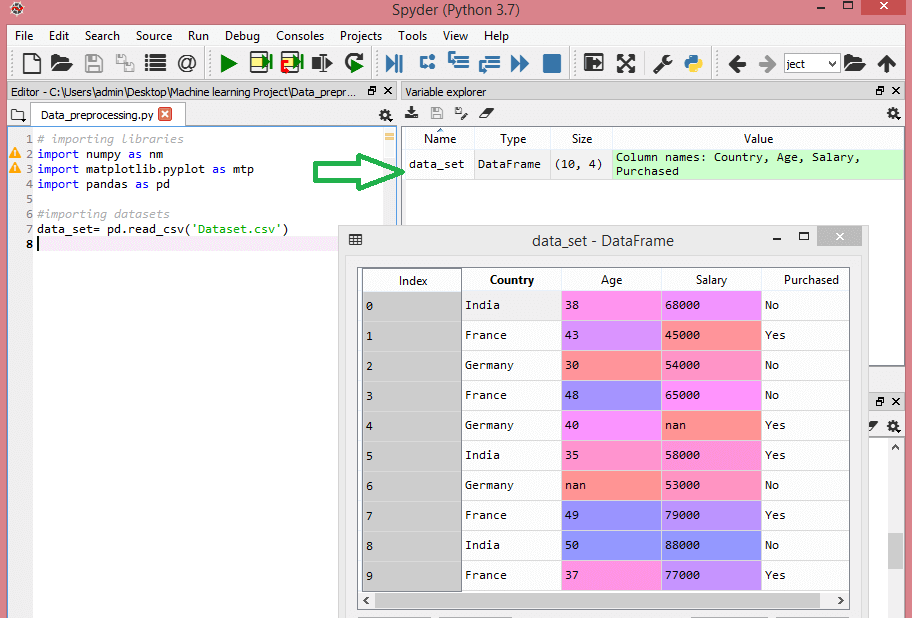
如上图所示,索引从0开始,这是Python的默认索引。我们还可以通过单击格式选项来更改数据集的格式。
提取因变量和自变量:
在机器学习中,从数据集中区分开特征矩阵(自变量)和因变量很重要。在我们的数据集中,有三个独立变量,分别是“国家/地区”,“年龄”和“工资”,一个是“已购买”因变量。
提取自变量:
要提取自变量,我们将使用Pandas库的iloc []方法。它用于从数据集中提取所需的行和列。
x= data_set.iloc[:,:-1].values
在上面的代码中,第一个冒号(:)用于获取所有行,第二个冒号(:)用于所有列。在这里我们使用了:-1,因为我们不想采用最后一列,因为它包含因变量。因此,通过这样做,我们将获得要素矩阵。
通过执行以上代码,我们将获得以下输出:
[['India' 38.0 68000.0]
['France' 43.0 45000.0]
['Germany' 30.0 54000.0]
['France' 48.0 65000.0]
['Germany' 40.0 nan]
['India' 35.0 58000.0]
['Germany' nan 53000.0]
['France' 49.0 79000.0]
['India' 50.0 88000.0]
['France' 37.0 77000.0]]
从上面的输出中可以看到,只有三个变量。
提取因变量:
同样,要提取因变量,我们将使用Pandas .iloc []方法。
y= data_set.iloc[:,3].values
在这里,我们仅使用了最后一行的所有行。它将给出因变量数组。
通过执行以上代码,我们将获得以下输出:
输出:
array(['No', 'Yes', 'No', 'No', 'Yes', 'Yes', 'No', 'Yes', 'No', 'Yes'],
dtype=object)
注意:如果您使用Python语言进行机器学习,则必须进行提取,但对于R语言则不需要。
4)处理遗漏数据:
数据预处理的下一步是处理数据集中的缺失数据。如果我们的数据集包含一些缺失的数据,那么可能会对我们的机器学习模型造成巨大的问题。因此,有必要处理数据集中存在的缺失值。
处理丢失数据的方法:
处理丢失数据的方式主要有两种:
通过删除特定行:第一种方法通常用于处理空值。这样,我们只删除由空值组成的特定行或列。但是这种方法效率不高,删除数据可能会导致信息丢失,从而无法提供准确的输出。
通过计算均值:这样,我们将计算包含任何缺失值的该列或行的均值,并将其放在缺失值的位置。对于具有数字数据(例如年龄,薪水,年等)的功能,此策略很有用。在这里,我们将使用此方法。
为了处理缺失值,我们将在代码中使用Scikit-learn库,其中包含用于构建机器学习模型的各种库。在这里,我们将使用sklearn.preprocessing库的Imputer类。下面是它的代码:
#handling missing data (Replacing missing data with the mean value)
from sklearn.preprocessing import Imputer
imputer= Imputer(missing_values ='NaN', strategy='mean', axis = 0)
#Fitting imputer object to the independent variables x.
imputer= imputer.fit(x[:, 1:3])
#Replacing missing data with the calculated mean value
x[:, 1:3]= imputer.transform(x[:, 1:3])
输出:
array([['India', 38.0, 68000.0],
['France', 43.0, 45000.0],
['Germany', 30.0, 54000.0],
['France', 48.0, 65000.0],
['Germany', 40.0, 65222.22222222222],
['India', 35.0, 58000.0],
['Germany', 41.111111111111114, 53000.0],
['France', 49.0, 79000.0],
['India', 50.0, 88000.0],
['France', 37.0, 77000.0]], dtype=object
正如我们在上面的输出中看到的,缺少的值已被其余列值的均值取代。
5)编码分类数据:
分类数据是具有某些类别的数据,例如在我们的数据集中;有两个类别变量,“国家”和“已购买”。
由于机器学习模型完全适用于数学和数字,但是如果我们的数据集具有分类变量,则在构建模型时可能会造成麻烦。因此,有必要将这些分类变量编码为数字。
对于国家/地区变量:
首先,我们将国家/地区变量转换为分类数据。为此,我们将使用预处理库中的LabelEncoder()类。
#Catgorical data
#for Country Variable
from sklearn.preprocessing import LabelEncoder
label_encoder_x= LabelEncoder()
x[:, 0]= label_encoder_x.fit_transform(x[:, 0])
输出:
Out[15]:
array([[2, 38.0, 68000.0],
[0, 43.0, 45000.0],
[1, 30.0, 54000.0],
[0, 48.0, 65000.0],
[1, 40.0, 65222.22222222222],
[2, 35.0, 58000.0],
[1, 41.111111111111114, 53000.0],
[0, 49.0, 79000.0],
[2, 50.0, 88000.0],
[0, 37.0, 77000.0]], dtype=object)
说明:
在上面的代码中,我们导入了sklearn库的LabelEncoder类。此类已成功将变量编码为数字。
但是在我们的例子中,有三个国家/地区变量,从上面的输出中可以看到,这些变量被编码为0、1和2。通过这些值,机器学习模型可以假设这些变量之间存在一定的相关性。会产生错误输出的变量。因此,要消除此问题,我们将使用伪编码。
虚拟变量:
虚拟变量是那些值为0或1的变量。1值表示该变量在特定列中的存在,其余变量变为0。使用伪编码时,我们将拥有与类别数相等的列数。
在我们的数据集中,我们有3个类别,因此它将产生具有0和1值的三列。对于虚拟编码,我们将使用预处理库的OneHotEncoder类。
#for Country Variable
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
label_encoder_x= LabelEncoder()
x[:, 0]= label_encoder_x.fit_transform(x[:, 0])
#Encoding for dummy variables
onehot_encoder= OneHotEncoder(categorical_features= [0])
x= onehot_encoder.fit_transform(x).toarray()
输出:
array([[0.00000000e+00, 0.00000000e+00, 1.00000000e+00, 3.80000000e+01,
6.80000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 4.30000000e+01,
4.50000000e+04],
[0.00000000e+00, 1.00000000e+00, 0.00000000e+00, 3.00000000e+01,
5.40000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 4.80000000e+01,
6.50000000e+04],
[0.00000000e+00, 1.00000000e+00, 0.00000000e+00, 4.00000000e+01,
6.52222222e+04],
[0.00000000e+00, 0.00000000e+00, 1.00000000e+00, 3.50000000e+01,
5.80000000e+04],
[0.00000000e+00, 1.00000000e+00, 0.00000000e+00, 4.11111111e+01,
5.30000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 4.90000000e+01,
7.90000000e+04],
[0.00000000e+00, 0.00000000e+00, 1.00000000e+00, 5.00000000e+01,
8.80000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 3.70000000e+01,
7.70000000e+04]])
从上面的输出中可以看到,所有变量都被编码为数字0和1,并分为三列。
通过单击x选项,可以在变量资源管理器部分中更清楚地看到它:
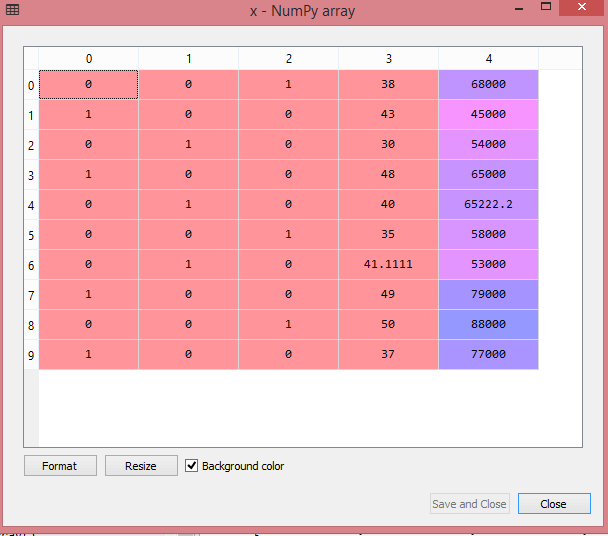
对于购买的变量:
labelencoder_y= LabelEncoder()
y= labelencoder_y.fit_transform(y)
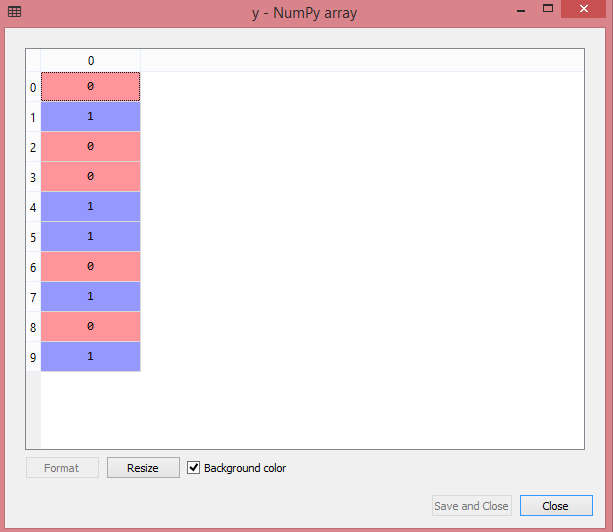
对于第二个分类变量,我们将仅使用LableEncoder类的labelencoder对象。这里我们不使用OneHotEncoder类,因为所购买的变量只有两个类别yes或no,它们会自动编码为0和1。
输出:
Out[17]: array([0, 1, 0, 0, 1, 1, 0, 1, 0, 1])
它也可以被视为:
6)将数据集分为训练集和测试集
在机器学习数据预处理中,我们将数据集分为训练集和测试集。这是数据预处理的关键步骤之一,因为这样做可以提高机器学习模型的性能。
假设,如果我们通过一个数据集对我们的机器学习模型进行了训练,然后通过一个完全不同的数据集对其进行了测试。然后,这将使我们的模型难以理解模型之间的相关性。
如果我们很好地训练我们的模型并且其训练精度也很高,但是我们为其提供了新的数据集,那么它将降低性能。因此,我们始终尝试建立一个机器学习模型,该模型在训练集和测试数据集上都能表现良好。在这里,我们可以将这些数据集定义为:

训练集:训练机器学习模型的数据集的子集,我们已经知道输出。
测试集:测试机器学习模型的数据集的子集,并且通过使用测试集,模型可以预测输出。
为了分割数据集,我们将使用以下代码行:
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test= train_test_split(x, y, test_size= 0.2, random_state=0)
说明:
- 在上面的代码中,第一行用于将数据集的数组拆分为随机训练和测试子集。
- 在第二行中,我们为输出使用了四个变量,分别是
- x_train:训练数据的功能
- x_test:测试数据的功能
- y_train:训练数据的因变量
- y_test:用于测试数据的自变量
- 在train_test_split() 函数 ,我们传递了四个参数,其中前两个参数用于数据数组,而test_size用于指定测试集的大小。 test_size可能是.5,.3或.2,它表示训练和测试集的划分比率。
- 最后一个参数random_state用于为随机数生成器设置种子,以便始终获得相同的结果,而最常用的值为42。
输出:
通过执行上述代码,我们将获得4个不同的变量,可以在变量资源管理器部分中看到它们。
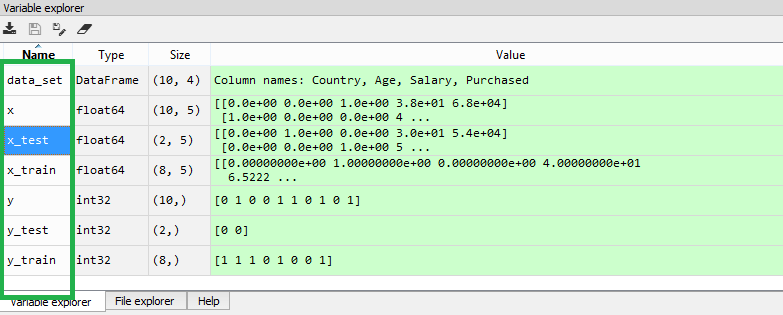
如上图所示,x和y变量分为4个具有相应值的不同变量。
7)功能缩放
特征缩放是机器学习中数据预处理的最后一步。这是一种在特定范围内标准化数据集自变量的技术。在特征缩放中,我们将变量置于相同的范围和比例中,以使任何变量都不能控制其他变量。
考虑以下数据集:

如我们所见,“年龄”和“工资”列的值不在同一比例上。机器学习模型基于欧几里得距离,如果我们不缩放变量,那么它将在我们的机器学习模型中引起一些问题。
欧几里得距离为:
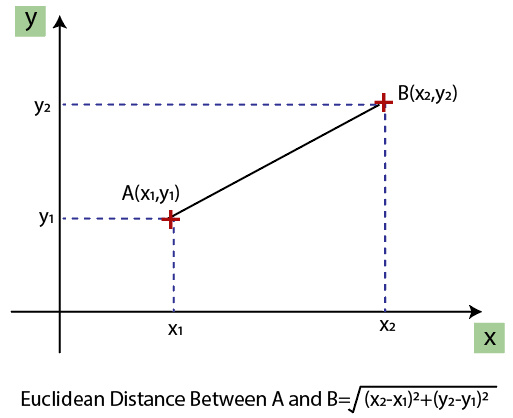
如果我们根据年龄和薪水计算任何两个值,那么薪水值将主导年龄值,并且将产生错误的结果。因此,要消除此问题,我们需要对机器学习进行特征缩放。
在机器学习中有两种执行特征缩放的方法:
标准化
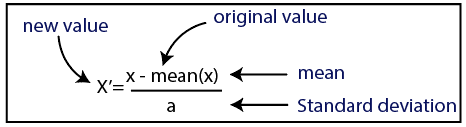
正常化

在这里,我们将对数据集使用标准化方法。
对于特征缩放,我们将sklearn.preprocessing库的StandardScaler类导入为:
from sklearn.preprocessing import StandardScaler
现在,我们将为独立变量或特征创建StandardScaler类的对象。然后,我们将拟合并变换训练数据集。
st_x= StandardScaler()
x_train= st_x.fit_transform(x_train)
对于测试数据集,我们将直接应用transform() 函数而不是fit_transform(),因为它已经在训练集中完成。
x_test= st_x.transform(x_test)
输出:
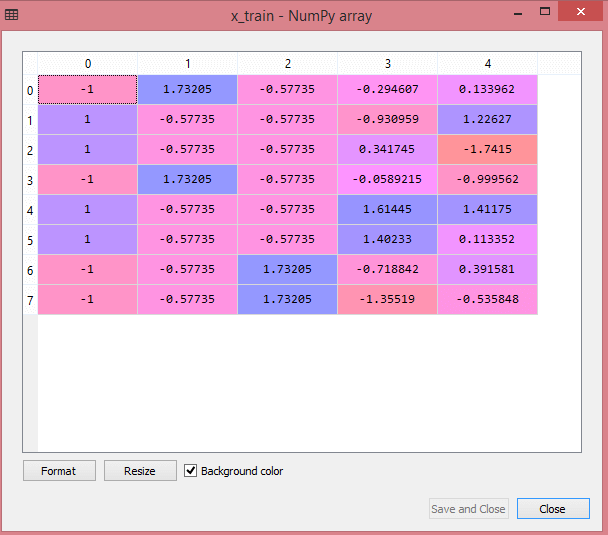
通过执行以上代码行,我们将获得x_train和x_test的缩放值:
x_train:
x_test:
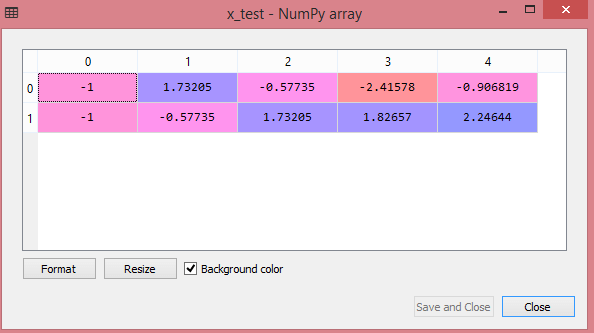
正如我们在上面的输出中看到的,所有变量都在值-1到1之间缩放。
注意:这里,我们没有缩放因变量,因为只有两个值0和1。但是,如果这些变量的值范围更大,那么我们也需要缩放这些变量。
结合所有步骤:
现在,最后,我们可以将所有步骤结合在一起,以使我们的完整代码更易于理解。
# importing libraries
import numpy as nm
import matplotlib.pyplot as mtp
import pandas as pd
#importing datasets
data_set= pd.read_csv('Dataset.csv')
#Extracting Independent Variable
x= data_set.iloc[:, :-1].values
#Extracting Dependent variable
y= data_set.iloc[:, 3].values
#handling missing data(Replacing missing data with the mean value)
from sklearn.preprocessing import Imputer
imputer= Imputer(missing_values ='NaN', strategy='mean', axis = 0)
#Fitting imputer object to the independent varibles x.
imputer= imputer.fit(x[:, 1:3])
#Replacing missing data with the calculated mean value
x[:, 1:3]= imputer.transform(x[:, 1:3])
#for Country Variable
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
label_encoder_x= LabelEncoder()
x[:, 0]= label_encoder_x.fit_transform(x[:, 0])
#Encoding for dummy variables
onehot_encoder= OneHotEncoder(categorical_features= [0])
x= onehot_encoder.fit_transform(x).toarray()
#encoding for purchased variable
labelencoder_y= LabelEncoder()
y= labelencoder_y.fit_transform(y)
# Splitting the dataset into training and test set.
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test= train_test_split(x, y, test_size= 0.2, random_state=0)
#Feature Scaling of datasets
from sklearn.preprocessing import StandardScaler
st_x= StandardScaler()
x_train= st_x.fit_transform(x_train)
x_test= st_x.transform(x_test)
在上面的代码中,我们将所有数据预处理步骤都包括在内。但是有些步骤或代码行并不是所有机器学习模型都必需的。因此,我们可以将它们从代码中排除,以使其可在所有模型中重用。