📌 相关文章
- 无监督机器学习
- 无监督机器学习(1)
- 机器学习-监督
- 机器学习-无监督
- 机器学习-监督(1)
- 监督学习(1)
- 监督学习
- 无监督学习(1)
- 监督学习和无监督学习
- 无监督学习
- 监督学习和无监督学习(1)
- 有监督和无监督学习(1)
- 有监督和无监督学习
- 监督学习与无监督学习之间的区别
- 监督学习与无监督学习之间的区别(1)
- 监督学习与无监督学习之间的区别
- 监督学习与无监督学习之间的区别(1)
- R 编程中的有监督和无监督学习
- R 编程中的有监督和无监督学习(1)
- 回归和分类 |监督机器学习(1)
- 回归和分类 |监督机器学习
- 无监督机器学习——网络安全的未来(1)
- 无监督机器学习——网络安全的未来
- C++中的机器学习(1)
- C++中的机器学习
- 机器学习中的 P 值
- 机器学习中的 P 值(1)
- 机器学习 (1)
- 毫升 |半监督学习(1)
📜 监督机器学习
📅 最后修改于: 2020-09-27 00:55:48 🧑 作者: Mango
监督机器学习
监督学习是机器学习的一种类型,其中,机器使用良好的“标记”训练数据来训练机器,并根据这些数据预测机器的输出。带标签的数据意味着某些输入数据已被正确的输出标记。
在监督学习中,提供给机器的训练数据充当指导者,指导机器正确预测输出。它采用与学生在老师的监督下学习相同的概念。
监督学习是向机器学习模型提供输入数据以及正确的输出数据的过程。监督学习算法的目的是找到一个映射函数,以将输入变量(x)与输出变量(y)映射。
在现实世界中,监督学习可用于风险评估,图像分类,欺诈检测,垃圾邮件过滤等。
监督学习如何工作?
在监督学习中,使用标记的数据集训练模型,其中模型学习每种数据类型。训练过程完成后,将基于测试数据(训练集的子集)对模型进行测试,然后预测输出。
通过以下示例和图表可以轻松地理解监督学习的工作方式:
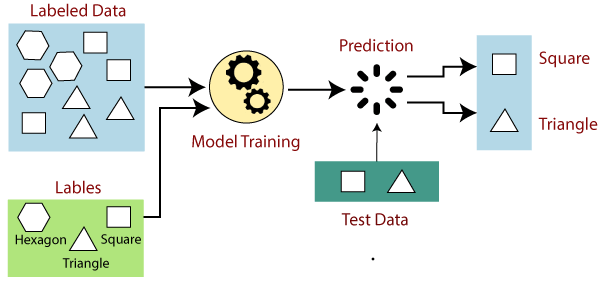
假设我们有一个不同类型的形状的数据集,包括正方形,矩形,三角形和多边形。现在的第一步是我们需要训练每种形状的模型。
- 如果给定的形状具有四个边,并且所有边都相等,则将其标记为Square 。
- 如果给定的形状具有三个边,则将其标记为三角形 。
- 如果给定的形状具有六个相等的边,则将其标记为六边形 。
现在,经过训练,我们使用测试集测试模型,模型的任务是识别形状。
该机器已经接受过各种形状的培训,找到新形状后,会根据多个侧面对形状进行分类,并预测输出结果。
监督学习涉及的步骤:
- 首先确定训练数据集的类型
- 收集/收集带标签的训练数据。
- 将训练数据集分为训练数据集,测试数据集和验证数据集 。
- 确定训练数据集的输入特征,应该具有足够的知识,以便模型可以准确地预测输出。
- 确定适合模型的算法,例如支持向量机,决策树等。
- 在训练数据集上执行算法。有时我们需要验证集作为控制参数,它们是训练数据集的子集。
- 通过提供测试集来评估模型的准确性。如果模型预测正确的输出,则表明我们的模型是准确的。
监督机器学习算法的类型:
监督学习可以进一步分为两种类型的问题:
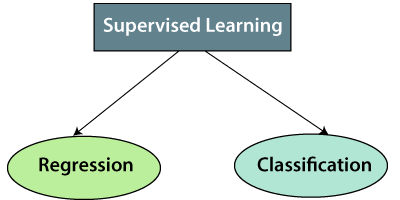
1.回归
如果输入变量和输出变量之间存在关系,则使用回归算法。它用于预测连续变量,例如天气预报,市场趋势等。下面是一些受监督学习的流行回归算法:
- 线性回归
- 回归树
- 非线性回归
- 贝叶斯线性回归
- 多项式回归
2.分类
当输出变量为分类时,将使用分类算法,这意味着有两个类,例如“是-否”,“男-女”,“真-假”等。
垃圾邮件过滤
- 随机森林
- 决策树
- 逻辑回归
- 支持向量机
注意:我们将在后面的章节中详细讨论这些算法。
监督学习的优势:
- 在监督学习的帮助下,该模型可以根据先前的经验来预测输出。
- 在监督学习中,我们可以对对象的类别有一个确切的了解。
- 监督学习模型可帮助我们解决各种现实问题,例如欺诈检测,垃圾邮件过滤等。
监督学习的缺点:
- 监督学习模型不适合处理复杂的任务。
- 如果测试数据与训练数据集不同,监督学习将无法预测正确的输出。
- 培训需要大量的计算时间。
- 在监督学习中,我们需要有关对象类别的足够知识。