分解随机合成器
Transformer 模型在各种不同的 NLP 任务中取得了巨大的成功。这导致变压器在很大程度上取代了许多最先进架构中以前的自回归循环神经网络架构。在这个转换器的核心,该架构使用了一种称为 Query-Key 点积注意力的方法。这种transformer架构的成功主要归功于self-attention机制。
分解随机密集合成器是一种注意力模型,在 Google Research 的论文“合成器:重新思考 Transformer 模型的自注意力”中提出。这背后的动机是通过提出点积自注意力的替代方案来降低架构操作的时间复杂度。
随机合成器
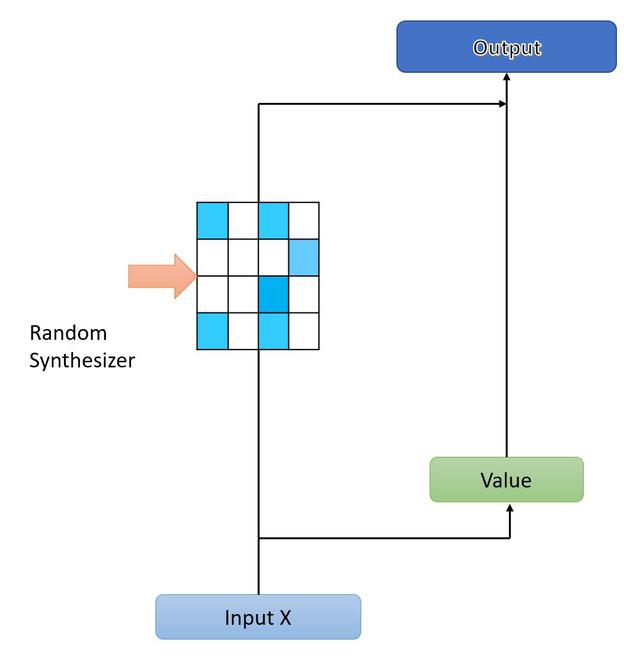
随机合成器
Dense Synthesizer 版本通过对 X 的每个输入的条件并将输入投影到 l 维度来学习综合注意力。这意味着 Dense Synthesizer 独立地以每个主题为条件,与我们同时处理所有标记的原始 Transformer 架构形成鲜明对比。作者提出了另一种合成器,其中注意力权重被初始化为随机值,而不是根据任何输入进行调节。这些随机注意力权重可以是可训练的,也可以是固定的。
让我们把 R 作为一个随机初始化的矩阵。随机合成器可以定义为:

其中 R ∈ R l*l ,每个头将网络中的参数数量增加 l 2 。
随机合成器背后的基本思想是消除成对标记交互或任何其他信息对给定标记的依赖,而是学习在不同样本中全局有效的特定任务对齐。
分解随机合成器
随机合成器向网络添加了l*l 个参数,这使得当l的值变大时,训练密集合成器变得更加困难。尽管删除了键和查询矩阵,但该模型可能难以训练。因此,作者提出了这些合成器的分解版本。
在该方法中,作者将R分解为低秩矩阵 R1 和 R2,使得 R 1 , R 2 ∈ R l*k 。
从上面的等式可以很容易地计算出,对于每个头,参数成本从l 2减少到 2lk ,其中k<
合成器的混合物
我们可以以附加的方式组合所有提出的合成注意力变体。这个表达式是:

其中S是参数化函数, a是参数使得 \sum a =1 是可训练的权重。
在混合随机分解随机和标准密集合成的情况下,表达式变为:

时间复杂度:
Self-attention 的时间复杂度为 \theta = 2d^{2} 而对于 Random Synthesizer,时间复杂度变为 \theta(  和分解随机合成器,时间复杂度为
和分解随机合成器,时间复杂度为 .其中l是指序列长度,d 是模型的维度,k 是分解。
参考
- 合成器:重新思考变压器模型的自注意力