计算 R 中重复的数量
在本文中,我们将看到如何在 R 编程语言中找出重复的数量。
可以通过两种方法完成:
- 使用duplicated()函数。
- 使用算法。
方法一:使用duplicated()
R和dplyr功能在这里,我们将使用复制()函数。
方法:
- 将“library(tidyverse)”包插入到程序中。
- 创建数据框或向量。
- 使用duplicated()函数并检查重复数据。
Syntax: duplicated(x)
Parameters: x: Data frame or a vector
示例 1:在向量中查找重复项。
让我们首先创建一个向量并找到 x 中重复元素的位置。
R
x <- c(1, 1, 4, 5, 4, 6)
duplicated(x)R
x <- c(1, 1, 4, 5, 4, 6)
duplicated(x)
x[duplicated(x)]R
data <- data.frame(
emp_id = c (1,1,2,4,5,6,6),
emp_name = c("Rick","Dan","Michelle",
"Ryan","Gary","x" , "y"))
display(data)R
duplicated(data$emp_id)R
data <- data.frame(
emp_id = c (1, 1, 2, 4, 5, 6, 6),
emp_name = c("Rick", "Dan", "Michelle",
"Ryan", "Gary", "x" , "y"))
duplicated[(data$emp_id), ]R
data <- data.frame(
emp_id = c (1,1,2,4,5,6,6),
emp_name = c("Rick","Dan","Michelle","Ryan","Gary","x" , "y"))
sum(table(data$emp_id)-1)
提取 x 中的重复元素。
电阻
x <- c(1, 1, 4, 5, 4, 6)
duplicated(x)
x[duplicated(x)]

在这里我们可以看到所有重复的元素。
示例 2:在 Dataframe 中查找重复项。
现在让我们创建一个数据框。
电阻
data <- data.frame(
emp_id = c (1,1,2,4,5,6,6),
emp_name = c("Rick","Dan","Michelle",
"Ryan","Gary","x" , "y"))
display(data)
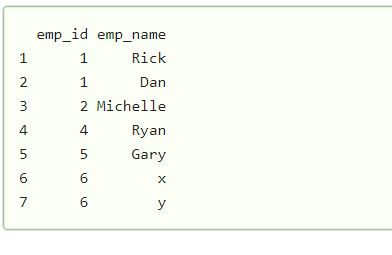
这里我们有一个数据框,有些项目是重复的,所以我们必须在这个数据框中找到重复的元素。
我们将检查哪一列有重复的数据。
电阻
duplicated(data$emp_id)

所以现在在emp_id列中找出有多少重复元素。
电阻
data <- data.frame(
emp_id = c (1, 1, 2, 4, 5, 6, 6),
emp_name = c("Rick", "Dan", "Michelle",
"Ryan", "Gary", "x" , "y"))
duplicated[(data$emp_id), ]

我们可以在emp_id列中看到所有重复的元素。
方法二:使用算法。
让我们假设我们有一个包含重复数据的数据框,我们必须找出该数据框中的重复数。
电阻
data <- data.frame(
emp_id = c (1,1,2,4,5,6,6),
emp_name = c("Rick","Dan","Michelle","Ryan","Gary","x" , "y"))
sum(table(data$emp_id)-1)
输出:

我们可以清楚地看到我们已经计算了数据框中的重复次数。