海运 |分布图
Seaborn 是一个基于 Matplotlib 的Python数据可视化库。它提供了一个用于绘制有吸引力和信息丰富的统计图形的高级界面。本文处理 seaborn 中用于检查单变量和双变量分布的分布图。在本文中,我们将讨论 4 种类型的分布图,即:
- 连接图
- 分布图
- 配对图
- 地毯图
除了提供不同类型的可视化图外,seaborn 还包含一些内置的数据集。我们将在本文中使用提示数据集。 “小费”数据集包含有关可能在餐厅用餐的人的信息,以及他们是否留下小费、年龄、性别等信息。让我们来看看它。
代码 :
# import thr necessary libraries
import seaborn as sns
import matplotlib.pyplot as plt % matplotlib inline
# to ignore the warnings
from warnings import filterwarnings
# load the dataset
df = sns.load_dataset('tips')
# the first five entries of the dataset
df.head()

现在,让我们继续剧情。
分布图
它基本上用于单变量观察集并通过直方图将其可视化,即只有一个观察值,因此我们选择数据集的一个特定列。
句法:
distplot(a[, bins, hist, kde, rug, fit, ...])例子:
# set the background style of the plot
sns.set_style('whitegrid')
sns.distplot(df['total_bill'], kde = False, color ='red', bins = 30)
输出: 
解释:
- KDE 代表Kernel Density Estimation ,这是 seaborn 中的另一种情节。
- bins 用于设置绘图中所需的 bin 数量,它实际上取决于您的数据集。
- color 用于指定绘图的颜色
现在看看这个,我们可以说给出的大部分账单都在 10 到 20 之间。
连接图
它用于绘制具有双变量和单变量图的两个变量的图。它基本上结合了两个不同的情节。
句法:
jointplot(x, y[, data, kind, stat_func, ...]) 例子:
sns.jointplot(x ='total_bill', y ='tip', data = df)
输出: 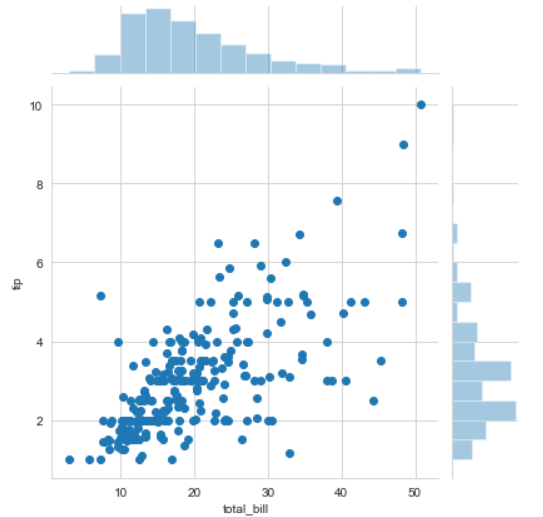
sns.jointplot(x ='total_bill', y ='tip', data = df, kind ='kde')
# KDE shows the density where the points match up the most
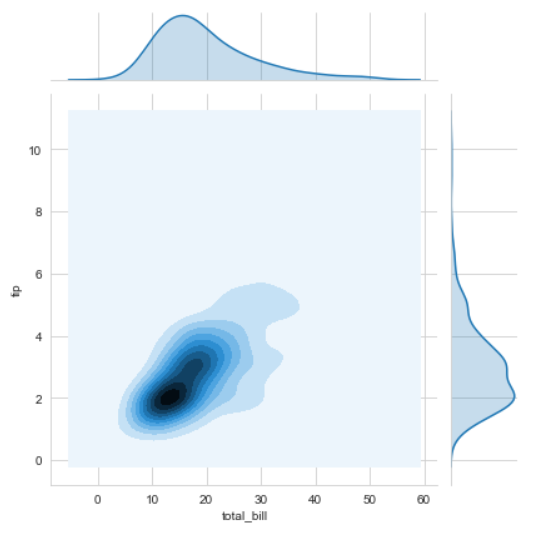
解释:
- kind 是一个变量,它可以帮助我们解决您希望如何可视化数据的事实。它有助于查看 joinplot 内部发生的情况。默认值为 scatter,可以是 hex、reg(regression) 或 kde。
- x 和 y 是两个字符串,它们是列名,列包含的数据通过指定 data 参数来使用。
- 在这里,我们可以看到 y 轴上的小费和 x 轴上的总账单,以及两者之间的线性关系,这表明总账单随着小费的增加而增加。
配对图
它表示整个数据帧中的成对关系,并支持一个称为色调的附加参数,用于分类分离。它所做的基本上是在每个可能的数字列之间创建一个联合图,如果数据框真的很大,则需要一段时间。
句法:
pairplot(data[, hue, hue_order, palette, …])例子:
sns.pairplot(df, hue ="sex", palette ='coolwarm')输出:

解释:- 如果数据集,hue 设置条目之间的分类分隔。
- 调色板用于设计绘图。
地毯图
它将数组中的数据点绘制为轴上的棒状图。就像 distplot 一样,它需要一列。它不是绘制直方图,而是在整个绘图中创建破折号。如果将其与 joinplot 进行比较,您会发现jointplot 的作用是计算破折号并将其显示为箱。
句法:
rugplot(a[, height, axis, ax])例子:
sns.rugplot(df['total_bill'])输出:
