- 机器学习中的交叉验证(1)
- 机器学习中的交叉验证(1)
- 交叉验证 (1)
- 交叉验证python(1)
- 交叉验证python代码示例
- 机器学习 (1)
- C++中的机器学习(1)
- C++中的机器学习
- 机器学习中的 P 值(1)
- 机器学习中的 P 值
- 交叉验证 - 任何代码示例
- 交叉验证错误 (1)
- 机器学习 python (1)
- R编程中的交叉验证(1)
- R编程中的交叉验证
- R 编程中的 K 折交叉验证(1)
- R 编程中的 K 折交叉验证
- 机器学习 python 代码示例
- 机器学习 - 任何代码示例
- 交叉验证错误 - 无论代码示例
- 什么是机器学习?
- 机器学习-什么是P值
- 机器学习-什么是P值(1)
- 什么是机器学习?(1)
- 在机器学习中什么是“i” (1)
- 学习 python 机器学习 - 任何代码示例
- 机器学习-什么是机器学习? -指导点
- 机器学习-什么是机器学习? -指导点(1)
- 分类交叉验证 - Python (1)
📅 最后修改于: 2020-09-29 03:24:49 🧑 作者: Mango
机器学习中的交叉验证
交叉验证是一种通过在输入数据的子集上训练模型效率并对输入数据的先前未见子集进行测试来验证模型效率的技术。我们也可以说这是一种检查统计模型如何概括为独立数据集的技术。
在机器学习中,始终需要测试模型的Solidity。这意味着仅基于训练数据集;我们无法将模型拟合到训练数据集上。为此,我们保留数据集的特定样本,该样本不属于训练数据集。之后,我们在部署之前在该样本上测试我们的模型,并且此完整过程要经过交叉验证。这与一般的火车测试分裂有所不同。
因此,交叉验证的基本步骤是:
- 保留数据集的一个子集作为验证集。
- 使用训练数据集为模型提供训练。
- 现在,使用验证集评估模型性能。如果模型在验证集上表现良好,请执行下一步,否则检查问题。
交叉验证所用的方法
有一些用于交叉验证的常用方法。这些方法如下:
- 验证集方法
- 留出交叉验证
- 留出一个交叉验证
- K折交叉验证
- 分层k折交叉验证
验证集方法
我们使用验证集方法将输入数据集划分为训练集和测试或验证集。两个子集都被赋予了数据集的50%。
但是它的一大缺点是我们仅使用50%的数据集来训练我们的模型,因此该模型可能会错过捕获数据集的重要信息的机会。它还倾向于给出欠拟合的模型。
留出交叉验证
在这种方法中,训练数据不包含p个数据集。这意味着,如果原始输入数据集中总共有n个数据点,则将np个数据点用作训练数据集,并将p个数据点用作验证集。对所有样本重复此完整过程,并计算平均误差以了解模型的有效性。
这种技术有一个缺点。也就是说,对于大p可能在计算上很困难。
留出一个交叉验证
该方法类似于leave-p-out交叉验证,但是要代替p,我们需要从训练中取出1个数据集。这意味着,在这种方法中,对于每个学习集,仅保留一个数据点,而其余数据集用于训练模型。对每个数据点重复此过程。因此,对于n个样本,我们得到n个不同的训练集和n个测试集。它具有以下功能:
- 在这种方法中,由于使用了所有数据点,因此偏差最小。
- 该过程执行n次;因此执行时间长。
- 当我们迭代检查一个数据点时,这种方法导致测试模型有效性的差异很大。
K折交叉验证
K折交叉验证方法将输入数据集分为大小相等的K组样本。这些样品称为褶皱。对于每个学习集,预测函数使用k-1倍,其余部分用于测试集。这种方法是一种非常流行的CV方法,因为它易于理解,并且与其他方法相比,输出的偏差较小。
k折交叉验证的步骤是:
- 将输入数据集分为K组
- 对于每个组:
- 取一组作为备用或测试数据集。
- 使用剩余的组作为训练数据集
- 将模型拟合到训练集上,并使用测试集评估模型的性能。
让我们以5倍交叉验证为例。因此,数据集分为5折。在第一个迭代中,保留第一折以测试模型,其余部分用于训练模型。在第二次迭代中,第二折用于测试模型,其余部分用于训练模型。此过程将继续进行,直到每个折痕都不用于测试折痕为止。
考虑下图:
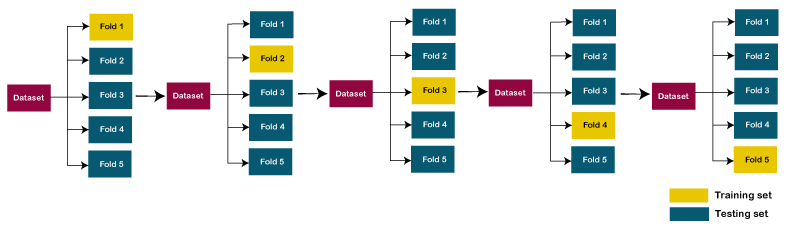
分层k折交叉验证
该技术类似于k倍交叉验证,但有一些小的变化。这种方法适用于分层概念,它是重新排列数据以确保每个折点或每组都能很好地代表完整数据集的过程。解决偏差和方差是最好的方法之一。
可以通过一个房价示例来理解,使得某些房屋的价格可能比其他房屋的价格高得多。为了解决这种情况,分层的k倍交叉验证技术很有用。
保持方法
此方法是所有方法中最简单的交叉验证技术。在这种方法中,我们需要删除训练数据的一个子集,并通过在数据集的其余部分上对其进行训练来使用它来获得预测结果。
在此过程中发生的错误告诉我们的模型在未知数据集下的表现如何。尽管此方法执行起来很简单,但仍然面临方差大的问题,有时还会产生误导性的结果。
交叉验证在机器学习中训练/测试拆分的比较
- 训练/测试拆分:输入数据分为两个部分,分别是训练集和测试集,其比例为70:30、80:20等。它提供了很高的方差,这是最大的缺点之一。
- 训练数据:训练数据用于训练模型,并且因变量是已知的。
- 测试数据:测试数据用于根据已经在训练数据上进行训练的模型做出预测。它具有与训练数据相同的功能,但不包括一部分。
- 交叉验证数据集:用于克服训练/测试拆分的缺点,方法是将数据集分为训练/测试拆分的组,然后对结果求平均值。如果我们要优化已在训练数据集上训练的模型以获得最佳性能,则可以使用它。与训练/测试拆分相比,它效率更高,因为每个观察都用于训练和测试。
交叉验证的局限性
交叉验证技术存在一些限制,如下所示:
- 在理想条件下,它可提供最佳输出。但是对于不一致的数据,可能会产生严重的结果。因此,这是交叉验证的一大弊端,因为在机器学习中无法确定数据类型。
- 在预测建模中,数据会在一段时间内演变,因此,数据可能会面临训练集和验证集之间的差异。例如,如果我们创建了一个预测股票市场价值的模型,并且对前5年的股票价值进行了数据训练,但是未来5年的实际未来价值可能会大不相同,因此很难期望正确的在这种情况下的输出。
交叉验证的应用
- 该技术可用于比较不同预测建模方法的性能。
- 它在医学研究领域具有很大的范围。
- 它也可以用于荟萃分析,因为它已经被医学统计学领域的数据科学家所使用。