在 MongoDB 中搜索文本
MongoDB 提供了一种很好的技术,即文本搜索。使用这种技术,我们可以从字符串字段中找到一段文本或一个指定的单词。或者换句话说,MongoDB 允许您执行查询操作以从字符串查找指定的文本。在 MongoDB 中,我们可以使用 text index 和 $text 运算符执行文本搜索。
文字索引: MongoDB 证明了用于从字符串内容中查找指定文本的文本索引。文本索引应该是字符串或字符串元素数组。当您执行文本搜索查询时,请始终记住您的集合必须包含一个文本索引,并且一个集合只能包含一个文本索引,但该单个文本索引涵盖多个字段。我们可以使用 createIndex() 方法创建文本索引。
句法:
db.collectionName.createIndex( { field: “text” } )
$text 运算符:您还可以使用 $text运算符搜索文本索引。此运算符用于对具有文本索引的集合执行文本搜索操作。此运算符使用空格标记每个搜索字符串,并将大多数标点符号视为分隔符,除了 – 和 \”。在对搜索字符串进行标记后,它对标记执行逻辑 OR 操作。如果要对结果文档进行排序,请使用 $meta 查询运算符。
句法:
$text:
{
$search:
$language:
$caseSensitive:
$diacriticSensitive:
}
如何搜索文本?
使用以下步骤,我们可以在 MongoDB 中搜索文本:
第 1 步:首先,我们创建一个集合并向集合中添加一些文档:
在以下示例中,我们正在使用:
Database: gfg
Collection: content
Document: The content collection contains the three documents.
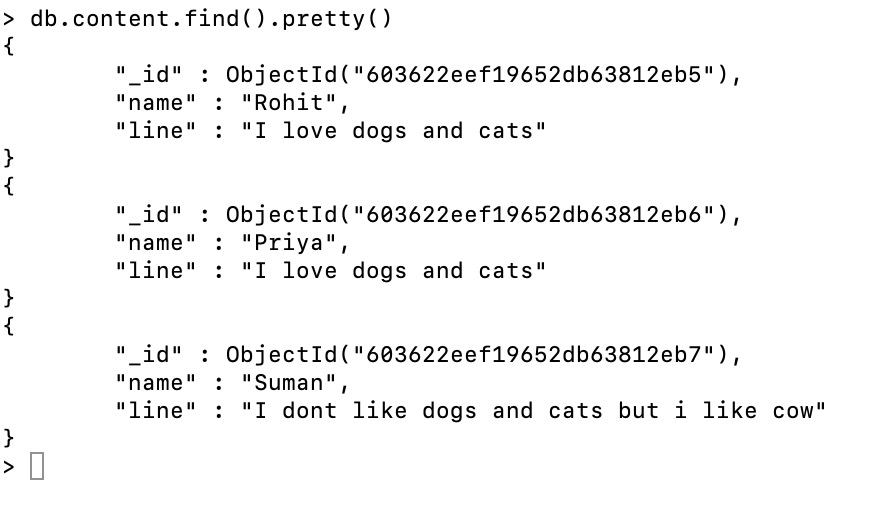
第二步:创建索引:
现在我们在 createIndex() 的帮助下在 name 和 pet 字段上创建一个字符串索引 方法。所以我们可以在 name 和 line 字段上搜索文本:
db.content.createIndex({name:"text",line:"text"})
第 3 步:搜索文本:
现在我们准备搜索文本。例如,我们要搜索所有包含文本 love 的文档。
db.content.find({$text:{$search:"love"}}) 注意:$text是一个查询运算符,它在一个带有文本索引的集合上执行文本搜索。

另一个示例,我们将在其中搜索所有包含 dog 文本的文档:
db.content.find({$text:{$search:"dog"}})
如何搜索词组?
除了搜索单个单词,您还可以通过将短语括在双引号 (“”) 中来搜索短语。通常,词组搜索在指定的关键字之间执行 OR 运算。例如,短语是“I like Mango”,然后阶段搜索查找包含关键字 I、like 或 Mango 的所有文档。如果您想执行精确的短语搜索,则将阶段括在转义的双引号 (\”) 之间。
句法:
对于短语搜索:
db.collectionName.find({$text:{$search:”Phrase”}})
对于精确短语搜索:
db.collectionName.find({$text:{$search:”\”Phrase”\”}})
例子:
在以下示例中,我们正在使用:
Database: gfg
Collection: content
Document: The content collection contains the three documents.
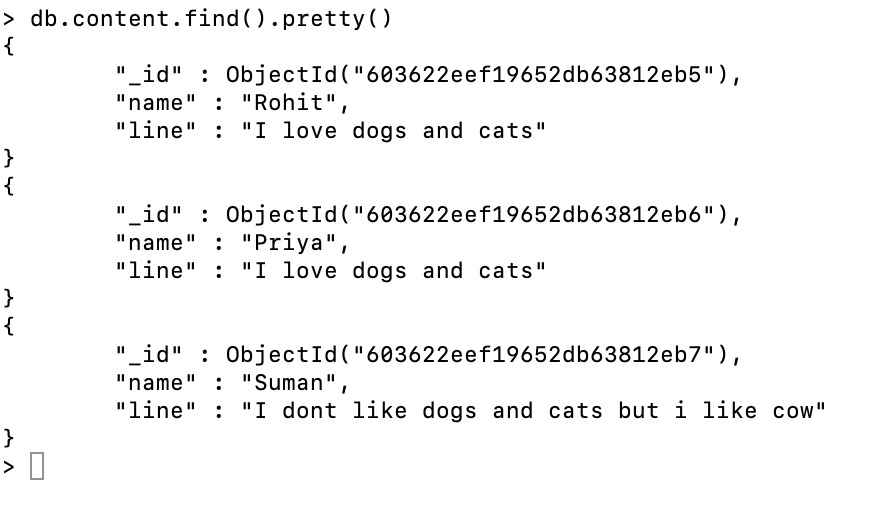
- 找到这句话:
db.content.find({$text:{$search:"I love dogs"}})在这里,我们搜索短语“我爱狗”。因此,在结果中,我们得到所有包含关键字 I、love 或 dog 的文档。

- 找到确切的短语:
db.content.find({$text:{$search:"\"I love dogs\""}})在这里,我们通过将相位包裹在转义双引号 (\”) 之间来搜索确切的短语,即“\”我爱狗\””。因此,在结果中,我们只得到那些包含指定确切短语的文档。

如何从搜索中排除一个术语?
词条排除是指当您执行搜索操作时,不希望显示包含指定词条的文档时,您可以通过在搜索关键字前加上减号(-)来排除该词条。使用减号(-)可以排除所有包含排除项的文档。例如,您希望显示包含关键字“Car”但不包含“Cycle”关键字的所有文档,因此您可以使用以下查询:
dn.collectionName.find({$text:{$search:"Car -Cycle"}})例如:
在以下示例中,我们正在使用:
Database: gfg
Collection: content
Document: The content collection contains the three documents.
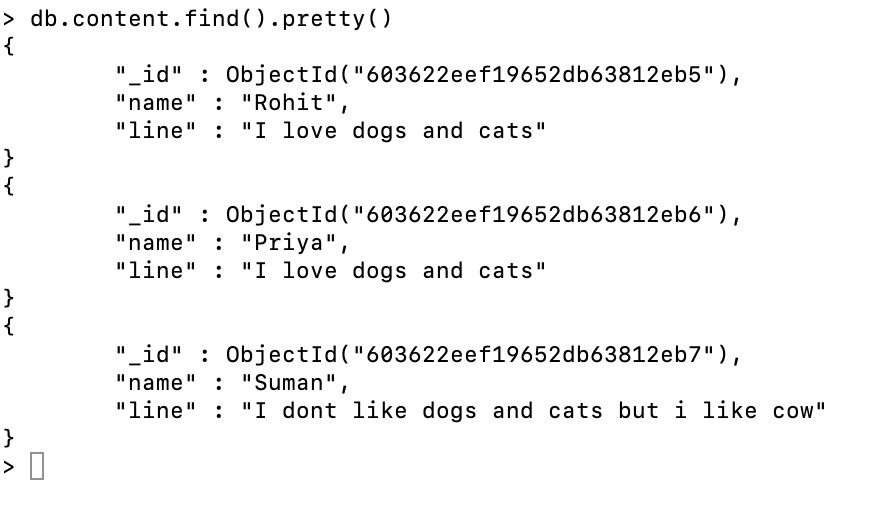
db.content.find({$text:{$search:"dog -cow"}})在这里,我们只显示那些包含 dog 而不是 cow 的文档。

使用聚合管道搜索文本
我们可以在$match阶段的$text查询运算符的帮助下使用聚合管道搜索文本。但是使用$text运算符有一些限制:
- 管道中的第一个阶段必须是包含$text运算符的$match阶段。
- 只有一次在舞台上才会出现文本运算符。
- 文本运算符的表达式不能出现在$or或$not 的表达式中。
- 默认情况下,文本搜索不会按照匹配分数的顺序返回匹配的文档。如果要按降序排序,请在 $sort 阶段使用 $meta 聚合表达式。
注意:文本分数是由 $text运算符分配给在索引字段中保存搜索词的每个文档的分数。该分数反映了文档对给定文本搜索查询的重要性。
例子:
在以下示例中,我们正在使用:
Database: gfg
Collection: people
Document: The people collection contains the five documents.

- 统计宠物值为猫的文档个数:
db.people.aggregate([{$match:{$text:{$search:"Cat"}}},
{$group:{_id:null,total:{$sum:1}}}])
- 统计宠物值为狗的文档个数:
db.people.aggregate([{$match:{$text:{$search:"Dog"}}},
{$group:{_id:null,total:{$sum:1}}}])
- 使用文本分数返回排序结果:
db.people.aggregate([{$match:{$text:{$search:"Dog"}}},
{$sort:{score:{$meta:"textScore"}}},
{$project:{_id:0,name:1}}])在这里,我们使用 textScore 以排序的形式返回结果(包含指定文本的所有文档,即“Dog”)。
