在 NLP 模型中使用 Glove 预训练词嵌入
在本文中,我们将看到在使用Python的 NLP 模型中使用 Glove 进行预训练的词嵌入。
词嵌入
在 NLP 模型中,我们处理人类可读和可理解的文本。但是机器不理解文本,它只理解数字。因此,词嵌入是将每个词转换为等效浮点向量的技术。根据模型和数据集的用例,存在各种技术。其中一些技术是 One Hot Encoding、TF-IDF、Word2Vec 和 FastText。
例子:
'the': [-0.123, 0.353, 0.652, -0.232]
'the' is very often used word in texts of any kind.
its equivalent 4-dimension dense vector has been given.手套数据
它代表全局向量。这是由斯坦福大学创建的。 Glove 为大约每 60 亿个英语文学单词以及许多其他通用字符(如逗号、大括号和分号)预定义了密集向量。
手套有 4 种可供选择:
Four varieties are: 50d, 100d, 200d and 300d.
这里d代表维度。 100d 表示,在这个文件中,每个单词都有一个大小为 100 的等效向量。手套文件是字典形式的简单文本文件。单词是键,密集向量是键的值。
创建词汇词典
词汇表是训练数据集中存在的所有唯一单词的集合。第一个数据集被标记为单词,然后计算每个单词的所有频率。然后按频率降序对单词进行排序。高频词放在词典的开头。
Dataset= {The peon is ringing the bell}
Vocabulary= {'The':2, 'peon':1, 'is':1, 'ringing':1}词嵌入算法:
- 预处理文本数据。
- 创建了字典。
- 遍历特定维度的glove文件,将每个单词与字典中的所有单词进行比较,
- 如果发生匹配,则从手套复制等效向量并粘贴到对应索引处的 embedding_matrix 中。
下面是实现:
Python3
# code for Glove word embedding
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
import numpy as np
x = {'text', 'the', 'leader', 'prime',
'natural', 'language'}
# create the dict.
tokenizer = Tokenizer()
tokenizer.fit_on_texts(x)
# number of unique words in dict.
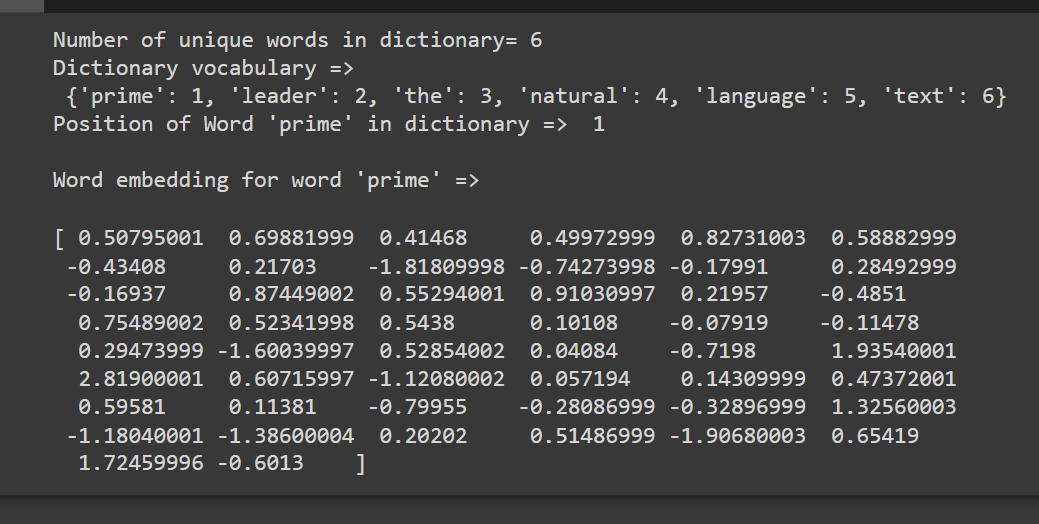
print("Number of unique words in dictionary=",
len(tokenizer.word_index))
print("Dictionary is = ", tokenizer.word_index)
# download glove and unzip it in Notebook.
#!wget http://nlp.stanford.edu/data/glove.6B.zip
#!unzip glove*.zip
# vocab: 'the': 1, mapping of words with
# integers in seq. 1,2,3..
# embedding: 1->dense vector
def embedding_for_vocab(filepath, word_index,
embedding_dim):
vocab_size = len(word_index) + 1
# Adding again 1 because of reserved 0 index
embedding_matrix_vocab = np.zeros((vocab_size,
embedding_dim))
with open(filepath, encoding="utf8") as f:
for line in f:
word, *vector = line.split()
if word in word_index:
idx = word_index[word]
embedding_matrix_vocab[idx] = np.array(
vector, dtype=np.float32)[:embedding_dim]
return embedding_matrix_vocab
# matrix for vocab: word_index
embedding_dim = 50
embedding_matrix_vocab = embedding_for_vocab(
'../glove.6B.50d.txt', tokenizer.word_index,
embedding_dim)
print("Dense vector for first word is => ",
embedding_matrix_vocab[1])输出: