📌 相关文章
- PyTorch 训练
- PyTorch 训练(1)
- 如何在 pytorch 中加载预训练模型 - Python (1)
- 如何在 pytorch 中加载预训练模型 - Python 代码示例
- Keras-预训练模型(1)
- Keras-预训练模型
- PyTorch-线性回归(1)
- PyTorch-线性回归
- PyTorch线性回归(1)
- PyTorch线性回归
- 在 pytorch 中保存模型 (1)
- 模型加载 pytorch - Python (1)
- pytorch 加载模型 - Python (1)
- pytorch 保存模型 - Python (1)
- pytorch 加载模型 - Python 代码示例
- 模型加载 pytorch - Python 代码示例
- 使用 PyTorch 使用验证训练神经网络(1)
- 使用 PyTorch 使用验证训练神经网络
- 使用PyTorch进行线性回归
- 使用PyTorch进行线性回归(1)
- pytorch 保存模型 - Python 代码示例
- PyTorch (1)
- 在 pytorch 中保存模型 - 任何代码示例
- 筛线性 (1)
- 线性图(1)
- 线性图
- 使用预训练模型进行图像分类(1)
- 使用预训练模型进行图像分类
- PyTorch感知器模型|模型设置
📜 线性模型的PyTorch训练
📅 最后修改于: 2020-11-11 00:43:05 🧑 作者: Mango
线性模型训练
给定分配给它的随机参数,我们绘制了线性模型。我们发现它与我们的数据不太吻合。我们要做的。我们需要训练该模型,以便该模型具有最佳的权重和偏差参数并拟合该数据。
有以下步骤来训练模型:
步骤1
我们的第一步是指定损失函数,我们打算将其最小化。 PyTorch提供了一种非常有效的方法来指定丢失的函数。 PyTorch提供MSELoss()函数(称为均方损失),以
criterion=nn.MSELoss()
第2步
现在,我们的下一步是更新参数。为此,我们指定使用梯度下降算法的优化器。我们使用称为随机梯度下降的SGD()函数进行优化。 SGD一次可以减少一个样本的总损失,并且通常可以更快地收敛,因为它将在相同样本大小内频繁更新模型的权重。
optimizer=torch.optim.SGD(model.parameters(),lr=0.01)
在此,lr代表学习率,最初设置为0.01。
第三步
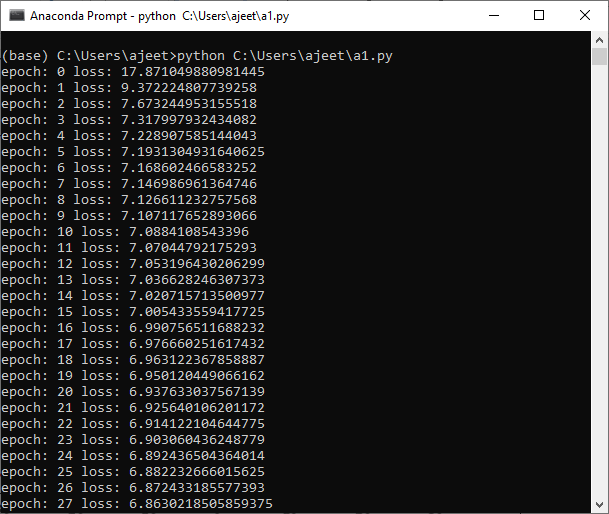
我们将培养我们的模型时代的指定号码(我们计算误差函数和backpropagated这个误差函数的梯度下降到更新的重量)。
epochs=100
现在,对于每个时代,我们都必须最小化模型系统的误差。误差只是模型预测与实际值之间的比较。
Losses=[]
For i in range (epochs):
ypred=model.forward(x) #Prediction of y
loss=criterion(ypred,y) #Find loss
losses.append() # Add loss in list
optimizer.zero_grad() # Set the gradient to zero
loss.backward() #To compute derivatives
optimizer.step() # Update the parameters
第四步
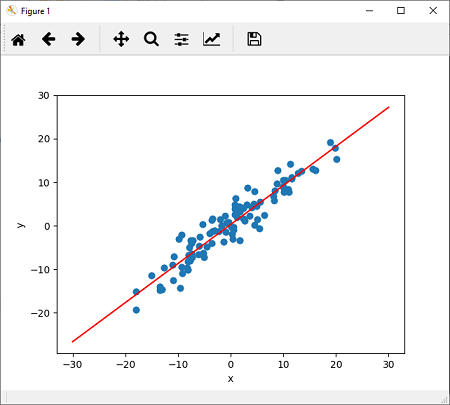
现在,最后,我们只需调用plotfit()方法来绘制新的线性模型。
plotfit('Trained Model')
完整的代码
程序
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import numpy as np
X=torch.randn(100,1)*10
y=X+3*torch.randn(100,1)
plt.plot(X.numpy(),y.numpy(),'o')
plt.ylabel('y')
plt.xlabel('x')
class LR(nn.Module):
def __init__(self,input_size,output_size):
super().__init__()
self.linear=nn.Linear(input_size,output_size)
def forward(self,x):
pred=self.linear(X)
return pred
torch.manual_seed(1) #For consistency of random result
model=LR(1,1)
criterion=nn.MSELoss() #Using Loss Function
optimizer=torch.optim.SGD(model.parameters(),lr=0.01) #Using optimizer which uses GD algorithm
print(model)
[a,b]=model.parameters() #Unpacking of parameters
epochs=100
losses=[]
for i in range(epochs):
ypred=model.forward(X)
loss=criterion(ypred,y)
print("epoch:",i,"loss:",loss.item())
losses.append(loss)
optimizer.zero_grad()
loss.backward()
optimizer.step()
defgrtparameters():
return(a[0][0].item(),b[0].item())
defplotfit(title):
plt.title=title
a1,b1=grtparameters()
x1=np.array([-30,30])
y1=a1*x1+b1
plt.plot(x1,y1,'r')
plt.scatter(X,y)
plt.show()
plotfit('Trained Model')
输出: