📌 相关文章
- Kafka流处理的关键概念
- Kafka流处理的关键概念(1)
- Kafka安全(1)
- Kafka安全
- 在Linux上安装Kafka
- 在Linux上安装Kafka(1)
- Kafka主题(1)
- Kafka主题
- kafka nodejs 示例 (1)
- c++ 处理 - C++ (1)
- 处理 (1)
- Kafka使用Java编程(1)
- Kafka使用Java编程
- 安装Apache Kafka
- 安装Apache Kafka(1)
- Kafka实时示例(1)
- Kafka实时示例
- kafka 删除主题 (1)
- Kafka Connect(1)
- Kafka Connect
- 创建Kafka主题(1)
- kafka 创建主题 (1)
- 创建Kafka主题
- kafka 列表主题 (1)
- Apache Kafka应用程序
- Apache Kafka-应用程序(1)
- Apache Kafka-应用程序
- Apache Kafka应用程序(1)
- Kafka监控
📜 Kafka流处理(1)
📅 最后修改于: 2023-12-03 15:32:27.383000 🧑 作者: Mango
Kafka流处理
Apache Kafka是一个分布式的流处理平台,可以处理实时数据流,并具有高性能,高可靠性和可伸缩性。 它是一个高度可定制和可扩展的系统,具有多种应用场景,例如实时数据流传输,事件处理,系统日志和指标。
架构
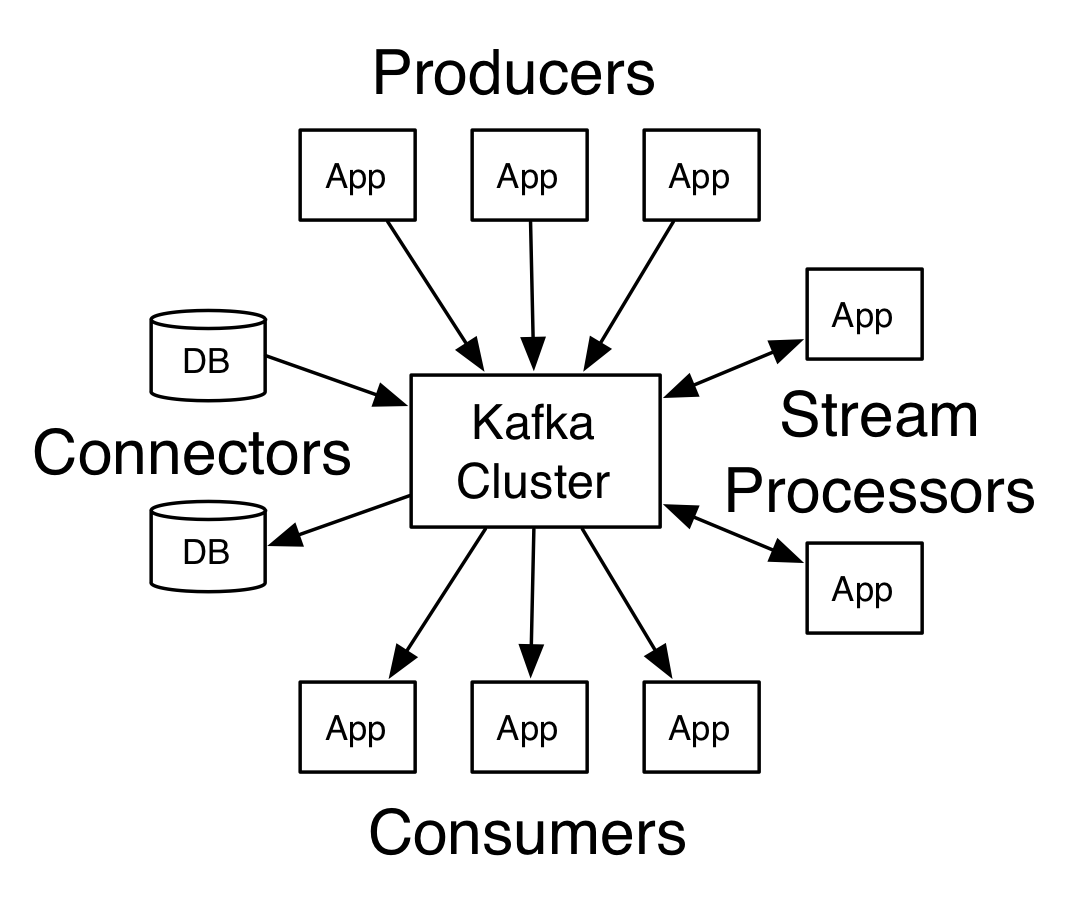
Kafka的体系结构由以下组件组成:
- Broker:Kafka的核心组件,代表Kafka集群中的一个节点。一个Kafka集群可以包含一个或多个Broker。每个Broker负责管理零个或多个Topic的分区。
- Topic:一个逻辑容器,用于在Kafka集群中分类存储消息。Kafka Topic只是一个有序的消息日志流。
- Partition:为Topic提供了水平扩展。 每个Topic可以进一步分成多个Partition,每个Partition是一个具有唯一ID的有序消息集合。
- Producer:生产者向一个Topic发布消息。一个生产者可以将消息发布到多个Topic中。
- Consumer:消费者可以订阅一个或多个Topic,并读取其分区中的消息。
- Consumer Group:由一组消费者组成的逻辑实体,共同协调从一个或多个Topic中读取消息。组中的每个消费者都负责处理Topic的一个或多个分区的数据流。
- Offset:是kafka中每个Partition中消息的唯一标识。消费者需要跟踪其读取消息的位置,为此Kafka使用Offset保存消费者在Partition中读取消息的位置。
流处理
Kafka Streams API提供了一种简单而优雅的方式,用于对Kafka Topic中的数据进行流处理。开发者只需编写Java代码即可轻松地实现流处理。
流处理的好处
- 实时性:流处理将数据实时地处理并在处理后立即返回结果。流处理可以在数据到达时对其进行处理,而不是等待数据累积一段时间再批量处理。
- 窗口计算:窗口计算使我们可以指定将前一小时的数据作为单独的块处理,而不是只处理每个数据记录。
- 有状态的处理:Kafka流处理允许我们使用状态,及时存储处理过程中生成的变量,以便可以在将来的处理阶段中进行使用。
- 支持容错:Kafka流处理具有容错功能。如果某个处理步骤失败,Kafka可以自动回复及重新执行该步骤。
流处理API
流处理API提供了以下构建块:
- Stream:将Topic中的数据流转换为处理流。流可以从一个或多个Topic中读取,然后对这些流应用一系列处理器,以从流中提取有趣的值。
- Processor:流处理器是一种处理流中数据的组件。它们将数据流入,在其中进行处理,并输出数据到输出流中。
- Transformer:转换器类似于流处理器,但有一个重要的区别:转换器可以修改输入数据的名称,以支持流的扩展和转换。
- Table:是Kafka Streams中的一种数据结构,用于处理无限量的数据流。可以将数据流存储在一个具有相同键的表中,并在需求时查询该表。
- Windowing:窗口是指在窗口时间段内来自数据流的一组有限数据。窗口可以根据事件时间或处理时间对数据进行分组。
Kafka通过以下步骤进行数据流处理:
- 创建流或表,将其连接到一个或多个Topic。
- 应用一个或多个流式处理器。
- 处理流,并将处理结果发送到输出流中。
示例代码
下面的示例代码演示如何使用Kafka Streams API读取并处理Kafka Topic中的数据,并最终将结果写回到Kafka Topic中。
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "my-stream-processing-app");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> textLines = builder.stream("input-topic");
KTable<String, Long> wordCounts = textLines
.flatMapValues(line -> Arrays.asList(line.toLowerCase().split("\\W+")))
.groupBy((key, word) -> word)
.count();
wordCounts.toStream().to("output-topic", Produced.with(Serdes.String(), Serdes.Long()));
KafkaStreams streams = new KafkaStreams(builder.build(), props);
streams.start();
以上代码将从"input-topic"中读取文本数据行,并将行拆分为单独的单词。每个单词将被映射到一个KTable中,按其键聚合并使用count操作计数。最终结果将被写回到另一个Kafka Topic“output-topic”中。处理过程是实时的,即当新数据到达时,计算将自动更新。
总结
Kafka流处理是一种可靠的、可扩展的、分布式的流处理平台,具有高性能、高可用性和实时数据处理能力。其API提供了一套构建块,使开发者能够轻松构建基于Kafka Topic的实时流处理应用程序。