GoSpider – 用 Go 编写的快速网络蜘蛛
网络爬虫是使用程序或自动化脚本(称为爬虫或蜘蛛或蜘蛛机器人)为网页上的数据编制索引的过程。该爬虫收集了大量信息,这些信息通常对 Web 应用程序渗透测试和漏洞赏金很有帮助。 GoSpider 也是最快的网络爬虫,它是用 Golang 语言设计的。 GoSpider 工具是开源的,免费使用。GoSpider 还支持多个目标域同时扫描,并允许将结果保存在本地存储中。
注意:由于 GoSpider 是一个基于 Golang 语言的工具,所以你的系统上需要有一个 Golang 环境。因此,请检查此链接以在您的系统中安装 Golang。 – 在 Linux 中安装 Go Lang
GoSpider 工具的特点
- GoSpider 工具是最快的网络爬虫工具。
- GoSpider 工具支持解析 robots.txt 文件。
- GoSpider 工具具有从 JavaScript 文件生成和验证链接的功能。
- GoSpider 工具支持 Burp Suite Input for Scan。
- GoSpider 工具可帮助同时扫描多个目标域。
- GoSpider 工具可以从响应源中检测子域。
在 Kali Linux 操作系统上安装 GoSpider 工具
第一步:如果您的系统中已经下载了Golang,请通过检查Golang的版本来验证安装,使用以下命令。
go version
第二步:从 Github 获取 GoSpider 仓库或克隆 GoSpider 工具,使用以下命令。
sudo GO111MODULE=on go get -u github.com/jaeles-project/gospider

第三步:将工具路径复制到/usr/bin目录下,以便从任何地方访问工具,使用以下命令
sudo cp /go/bin/gospider /usr/local/go/bin/
步骤 4:使用以下命令检查 GoSpider 工具的版本。
gospider --version
步骤5:查看帮助菜单页面以更好地了解GoSpider工具,使用以下命令。
gospider -h
在 Kali Linux 上使用 GoSpider 工具
示例 1:单站点运行
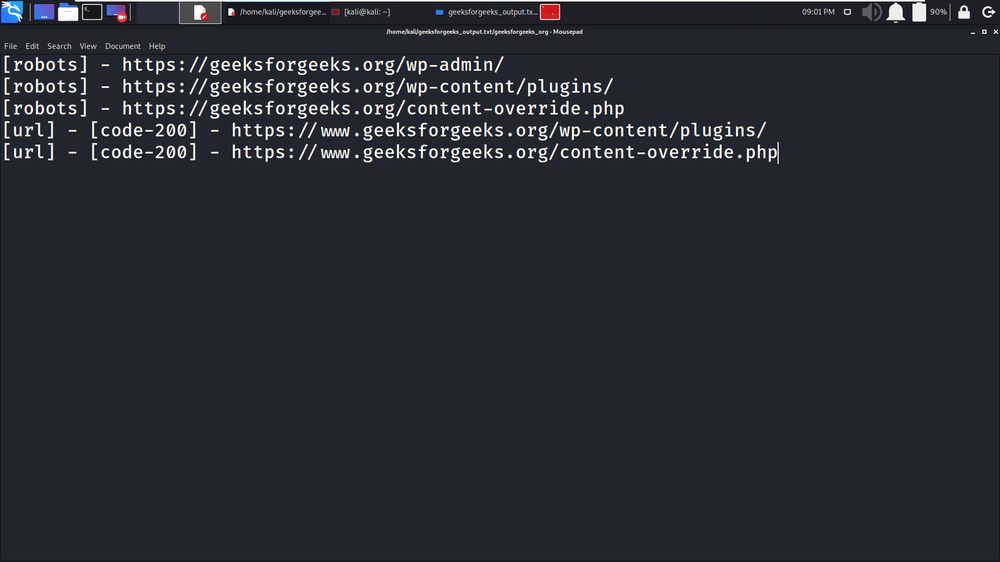
gospider -s “https://geeksforgeeks.org” -o geeksforgeeks_output.txt -c 10 -d 1
1. 在本例中,我们将从单个目标域 (geeksforgeeks.org) 中抓取链接。 -s 标签用于指定目标域。

2.在下面的截图中,抓取过程的结果存储在文本文件中,可用于进一步扫描,
示例 2:使用站点列表运行
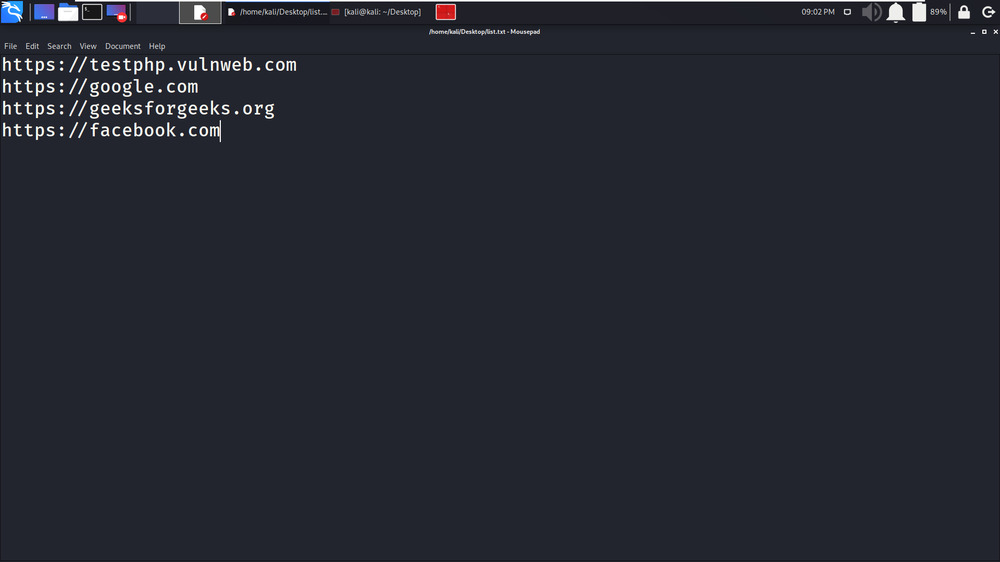
gospider -s list.txt -o output -c 10 -d 11. 在这个例子中,我们将在多个目标域上执行爬行。在下面的屏幕截图中,显示了一个包含多个目标域的文本文件。
2.在下面的截图中,您可以看到在多个目标上的爬取过程的结果显示在终端上。

3. 在下面的屏幕截图中,您可以看到为第一个屏幕截图中指定的域创建了一个单独的文本文件。

4.在下面的屏幕截图中,您可以看到爬网的结果保存在与其域关联的文件中。 (geeksforgeeks.org 结果保存在 geeksforgeeks.org_results, txt 中)。

示例 3:同时运行 10 个站点,每个站点 5 个机器人
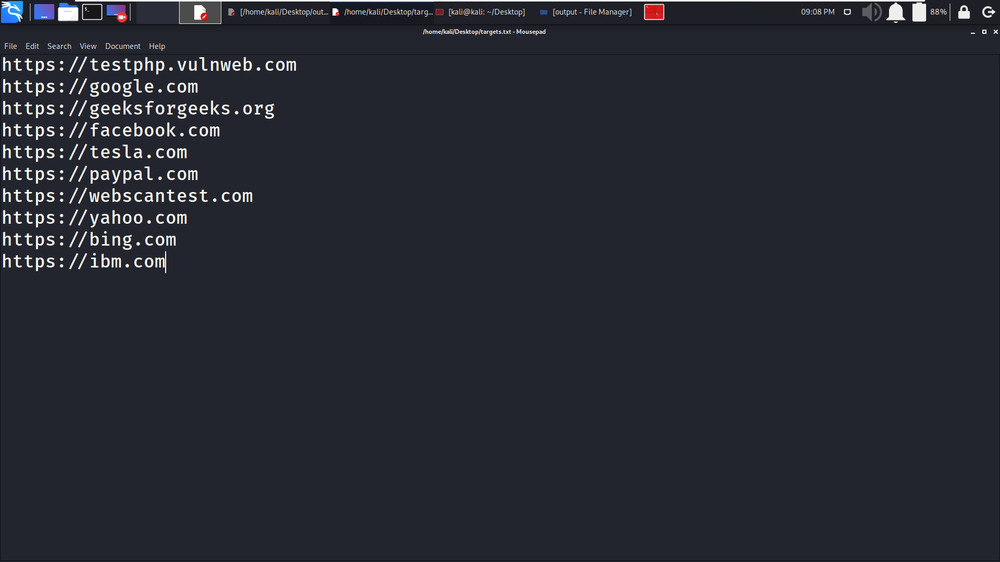
gospider -S targets.txt -o output1 -c 10 -d 1 -t 201. 在本例中,我们将同时抓取 10 个不同的网站或目标域。在下面的屏幕截图中,目标域保存在 targets.txt 文件中。
2.在下面的屏幕截图中,我们提供了命令并启动了抓取过程

3. 在下面的截图中,您可以看到 GoSpider 正在同时抓取各个目标域。在下面的截图中,tesla.com、geeksforgeeks.org、yahoo.com 等域名同时被抓取。

4. 虽然抓取是同时进行的,但每个目标域的结果都保存在与其名称相关联的单独文本文件中。在下面的屏幕截图中,10 个目标域结果连同它们的名称保存在 10 个不同的文本文件中。

5. 在下面的截图中,我们打开了包含所有抓取数据的 google.com_results.txt 文件。
示例 4:同时从第 3 方(Archive.org、CommonCrawl.org、VirusTotal.com、AlienVault.com)获取 URL
gospider -s "https://geeksforgeeks.org/" -o output -c 10 -d 1 --other-source1. 在这个例子中,我们试图从外部 3rd 方获取链接。

2. 在下面的屏幕截图中,结果保存在与目标域名关联的文本文件中。

示例 5:还从第 3 方(Archive.org、CommonCrawl.org、VirusTotal.com、AlienVault.com)获取 URL 并包含子域
gospider -s “https://google.com/” -o output2 -c 10 -d 1 –other-source –include-subs
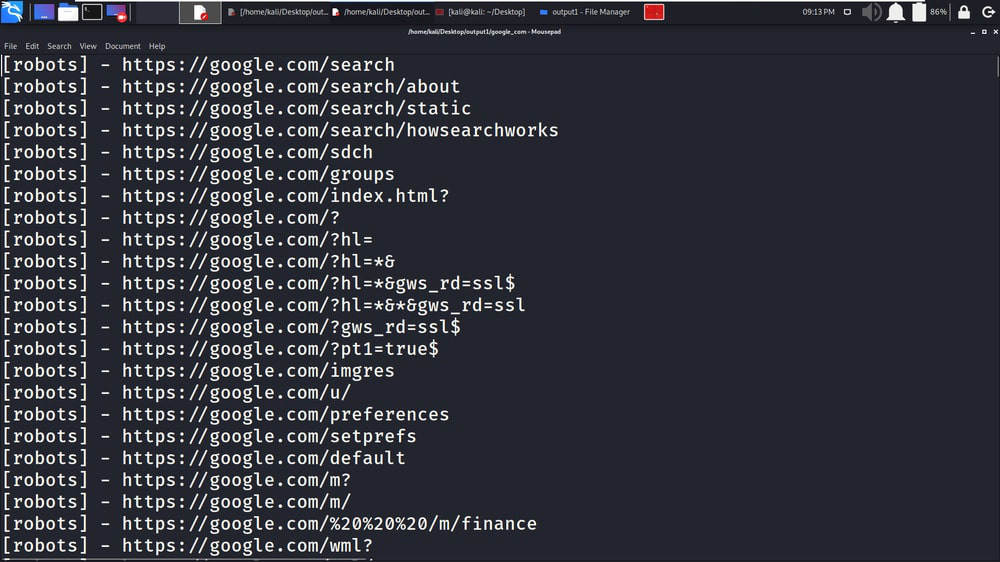
1. 在本例中,我们将从与提供的主域相关联的子域中抓取数据。在下面的屏幕截图中,我们正在抓取 google.com,因为它具有巨大的范围。

2.在下面的屏幕截图中,您可以看到子域也包含在抓取过程中。
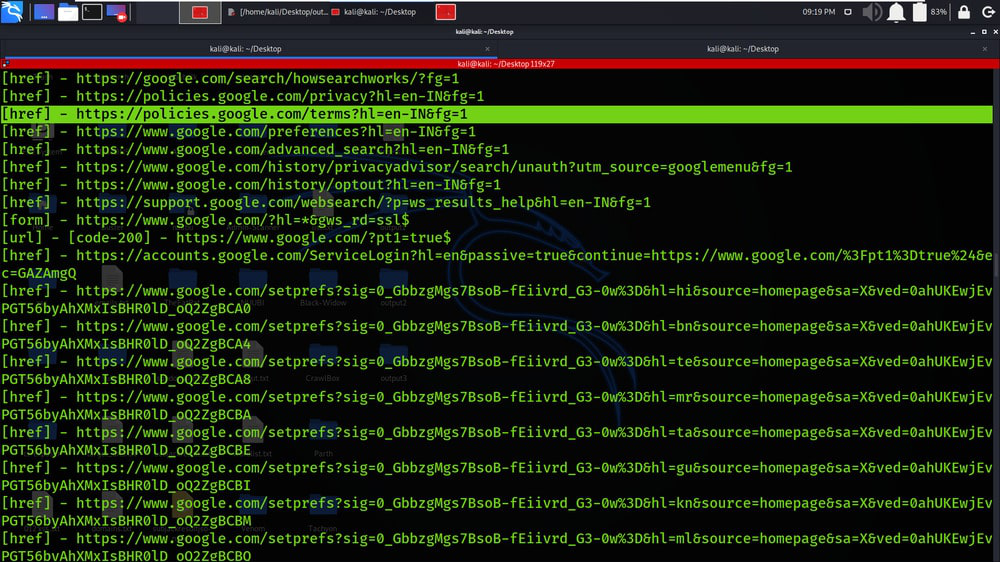
示例 6:使用自定义标头/cookie
gospider -s “https://geeksforgeeks.org/” -o output3 -c 10 -d 1 –other-source -H “Accept: */*” -H “Test: test” –cookie “testA=a; testB=b”
1. 在本示例中,我们以 cookie 的形式提供附加信息。我们已经使用 –cookie 标签来提供 cookie 的值。

示例 7 :黑名单 URL/文件扩展名。
gospider -s “https://geeksforgeeks.org” -o output -c 10 -d 1 –blacklist “.(woff|pdf)”
1. 在本示例中,我们将过滤或添加一些扩展名和 URL 到黑名单。在检索结果时,所有这些列入黑名单的数据都将被排除或忽略。
