Dunn 索引和 DB 索引 – 集群有效性索引 |设置 1
不同的性能指标用于评估不同的机器学习算法。在分类问题的情况下,我们有多种性能指标来评估我们的模型有多好。对于聚类分析,类似的问题是如何评估结果聚类的“好坏”?
为什么我们需要集群有效性指数?
- 比较聚类算法。
- 比较两组集群。
- 比较两个集群,即哪个集群在紧凑性和连通性方面更好。
- 判断数据中是否因噪声而存在随机结构。
通常,集群有效性度量分为 3 类,它们是 -
- 内部聚类验证:聚类结果是根据聚类本身的数据(内部信息)评估的,不参考外部信息。
- 外部聚类验证:聚类结果是根据一些外部已知的结果来评估的,例如外部提供的类标签。
- 相对聚类验证:聚类结果是通过改变同一算法的不同参数来评估的(例如,改变聚类的数量)。
除了术语集群有效性指数,我们还需要知道两个集群 a、b 之间的集群间距离d(a, b)和集群 a 的集群内索引D(a) 。
两个集群 a 和 b 之间的集群间距离d(a, b)可以是 -
- 单联动距离:分别属于a和b的两个对象之间的最近距离。
- 完全联动距离:分别属于a和b的两个最远的物体之间的距离。
- 平均联动距离:分别属于a和b的所有对象之间的平均距离。
- 质心联动距离:两个簇a和b的质心之间的距离。
簇 a的簇内距离D(a)可以是 -
- 完整直径链接距离:属于簇 a 的两个最远对象之间的距离。
- 平均直径链接距离:属于聚类 a 的所有对象之间的平均距离。
- 质心直径联动距离:所有对象与聚类质心的平均距离的两倍。
现在,让我们讨论 2 个内部集群有效性索引,即Dunn 索引和DB 索引。
邓恩指数:
Dunn 指数 (DI)(由 JC Dunn 于 1974 年引入)是一种评估聚类算法的指标,是一种内部评估方案,其结果基于聚类数据本身。与所有其他此类指数一样,此 Dunn 指数的目的是识别紧凑的集群集,集群成员之间的差异很小,并且分离良好,其中不同集群的均值相距足够远,与在集群方差内。
Dunn 指数值越高,聚类效果越好。取Dunn指数最大的簇数作为最优簇数k。它也有一些缺点。随着聚类数量和数据维数的增加,计算成本也随之增加。
c 个簇的 Dunn 指数定义为:

在哪里,

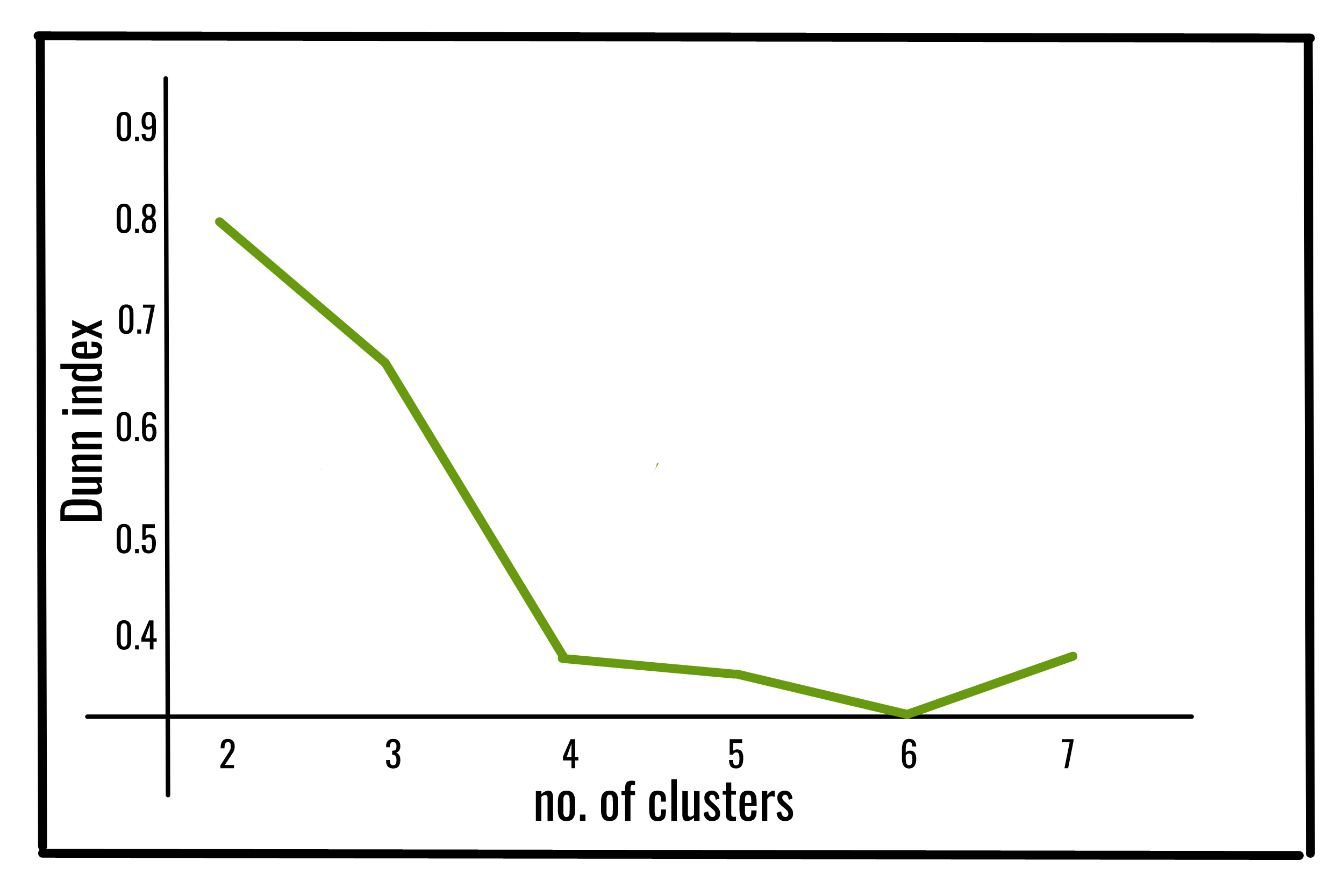
下面是使用jqmcvi库对上述 Dunn 索引的Python实现:
Python3
import pandas as pd
from sklearn import datasets
from jqmcvi import base
# loading the dataset
X = datasets.load_iris()
df = pd.DataFrame(X.data)
# K-Means
from sklearn import cluster
k_means = cluster.KMeans(n_clusters=3)
k_means.fit(df) #K-means training
y_pred = k_means.predict(df)
# We store the K-means results in a dataframe
pred = pd.DataFrame(y_pred)
pred.columns = ['Type']
# we merge this dataframe with df
prediction = pd.concat([df, pred], axis = 1)
# We store the clusters
clus0 = prediction.loc[prediction.Species == 0]
clus1 = prediction.loc[prediction.Species == 1]
clus2 = prediction.loc[prediction.Species == 2]
cluster_list = [clus0.values, clus1.values, clus2.values]
print(base.dunn(cluster_list))Python3
from sklearn import datasets
from sklearn.cluster import KMeans
from sklearn.metrics import davies_bouldin_score
from sklearn.datasets.samples_generator import make_blobs
# loading the dataset
X, y_true = make_blobs(n_samples=300, centers=4,
cluster_std=0.50, random_state=0)
# K-Means
kmeans = KMeans(n_clusters=4, random_state=1).fit(X)
# we store the cluster labels
labels = kmeans.labels_
print(davies_bouldin_score(X, labels))输出:
0.67328051数据库索引:
Davies-Bouldin 指数 (DBI)(由 David L. Davies 和 Donald W. Bouldin 于 1979 年引入)是一种评估聚类算法的指标,是一种内部评估方案,用于验证聚类的执行情况使用数据集固有的数量和特征。
数据库索引值越低,聚类效果越好。它也有一个缺点。这种方法报告的一个好的值并不意味着最好的信息检索。
k 个簇的 DB 索引定义为:

在哪里,

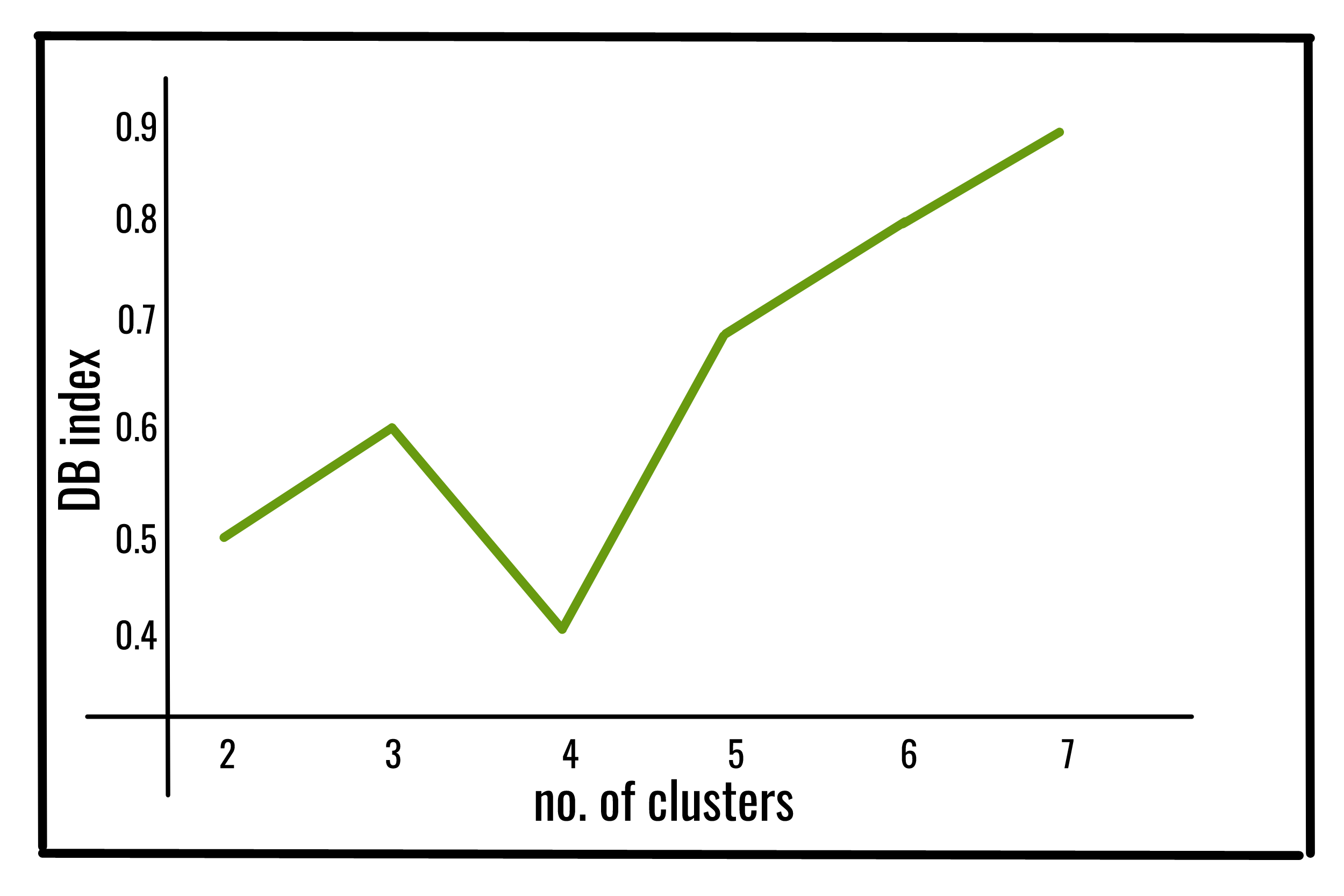
下面是使用 sklearn 库对上述数据库索引的Python实现:
Python3
from sklearn import datasets
from sklearn.cluster import KMeans
from sklearn.metrics import davies_bouldin_score
from sklearn.datasets.samples_generator import make_blobs
# loading the dataset
X, y_true = make_blobs(n_samples=300, centers=4,
cluster_std=0.50, random_state=0)
# K-Means
kmeans = KMeans(n_clusters=4, random_state=1).fit(X)
# we store the cluster labels
labels = kmeans.labels_
print(davies_bouldin_score(X, labels))
输出:
0.36628770
参考:
http://cs.joensuu.fi/sipu/pub/qinpei-thesis.pdf
https://en.wikipedia.org/wiki/Davies%E2%80%93Bouldin_index
https://en.wikipedia.org/wiki/Dunn_index
https://pyshark.com/davies-bouldin-index-for-k-means-clustering-evaluation-in-python/