亚当优化器的直觉
先决条件:梯度下降中的优化技术
亚当优化器
自适应矩估计是一种用于梯度下降优化技术的算法。当处理涉及大量数据或参数的大问题时,该方法非常有效。它需要更少的内存并且效率很高。直观地说,它是“带有动量的梯度下降”算法和“RMSP”算法的组合。
亚当如何工作?
Adam 优化器涉及两种梯度下降方法的组合:
势头:
该算法用于通过考虑梯度的“指数加权平均值”来加速梯度下降算法。使用平均值使算法以更快的速度收敛到最小值。

在哪里,
![m_{t}=\beta m_{t-1}+(1-\beta)\left[\frac{\delta L}{\delta w_{t}}\right]](https://mangodoc.oss-cn-beijing.aliyuncs.com/geek8geeks/Intuition_of_Adam_Optimizer_1.jpg "由 QuickLaTeX.com 渲染")
mt = aggregate of gradients at time t [current] (initially, mt = 0)
mt-1 = aggregate of gradients at time t-1 [previous]
Wt = weights at time t
Wt+1 = weights at time t+1
αt = learning rate at time t
∂L = derivative of Loss Function
∂Wt = derivative of weights at time t
β = Moving average parameter (const, 0.9)均方根传播 (RMSP):
均方根 prop 或 RMSprop 是一种尝试改进 AdaGrad 的自适应学习算法。它不像在 AdaGrad 中那样采用梯度平方的累积总和,而是采用“指数移动平均”。
![w_{t+1}=w_{t}-\frac{\alpha_{t}}{\left(v_{t}+\varepsilon\right)^{1 / 2}} *\left[\frac{\delta L}{\delta w_{t}}\right]](https://mangodoc.oss-cn-beijing.aliyuncs.com/geek8geeks/Intuition_of_Adam_Optimizer_2.jpg "由 QuickLaTeX.com 渲染")
在哪里,
![v_{t}=\beta v_{t-1}+(1-\beta) *\left[\frac{\delta L}{\delta w_{t}}\right]^{2}](https://mangodoc.oss-cn-beijing.aliyuncs.com/geek8geeks/Intuition_of_Adam_Optimizer_3.jpg "由 QuickLaTeX.com 渲染")
Wt = weights at time t
Wt+1 = weights at time t+1
αt = learning rate at time t
∂L = derivative of Loss Function
∂Wt = derivative of weights at time t
Vt = sum of square of past gradients. [i.e sum(∂L/∂Wt-1)] (initially, Vt = 0)
β = Moving average parameter (const, 0.9)
ϵ = A small positive constant (10-8)
NOTE: Time (t) could be interpreted as an Iteration (i).
Adam Optimizer 继承了上述两种方法的优点或优点,并在此基础上提供了更优化的梯度下降。
在这里,我们以这样一种方式控制梯度下降的速率,即当它达到全局最小值时出现最小振荡,同时采取足够大的步长(步长)以便沿途通过局部最小值障碍。因此,结合上述方法的特点可以有效地达到全局最小值。
Adam 优化器的数学方面
将上述两种方法中使用的公式,我们得到
![m_{t}=\beta_{1} m_{t-1}+\left(1-\beta_{1}\right)\left[\frac{\delta L}{\delta w_{t}}\right] v_{t}=\beta_{2} v_{t-1}+\left(1-\beta_{2}\right)\left[\frac{\delta L}{\delta w_{t}}\right]^{2}](https://mangodoc.oss-cn-beijing.aliyuncs.com/geek8geeks/Intuition_of_Adam_Optimizer_5.jpg "由 QuickLaTeX.com 渲染")
Parameters Used :
1. ϵ = a small +ve constant to avoid 'division by 0' error when (vt -> 0). (10-8)
2. β1 & β2 = decay rates of average of gradients in the above two methods. (β1 = 0.9 & β2 = 0.999)
3. α — Step size parameter / learning rate (0.001)
由于 m t和 v t都初始化为 0(基于上述方法),可以观察到它们倾向于“偏向 0”,因为 β 1和 β 2 ≈ 1。这个优化器通过以下方式解决了这个问题计算“偏差校正” m t和 v t 。这样做也是为了在达到全局最小值的同时控制权重,以防止在接近全局最小值时发生高振荡。使用的公式是:

直观地说,我们在每次迭代后都在适应梯度下降,以便它在整个过程中保持受控和无偏,因此得名 Adam。
现在,而不是我们的正常体重参数m T和V T,我们采取的偏差修正的重量参数(m_hat)T和(v_hat)吨。将它们放入我们的一般方程中,我们得到

表现:
基于以前模型的优势,Adam 优化器提供了比以前使用的模型高得多的性能,并且在提供优化的梯度下降方面大大优于它们。下图清楚地描绘了 Adam Optimizer 如何在训练成本(低)和性能(高)方面以相当大的优势优于其他优化器。
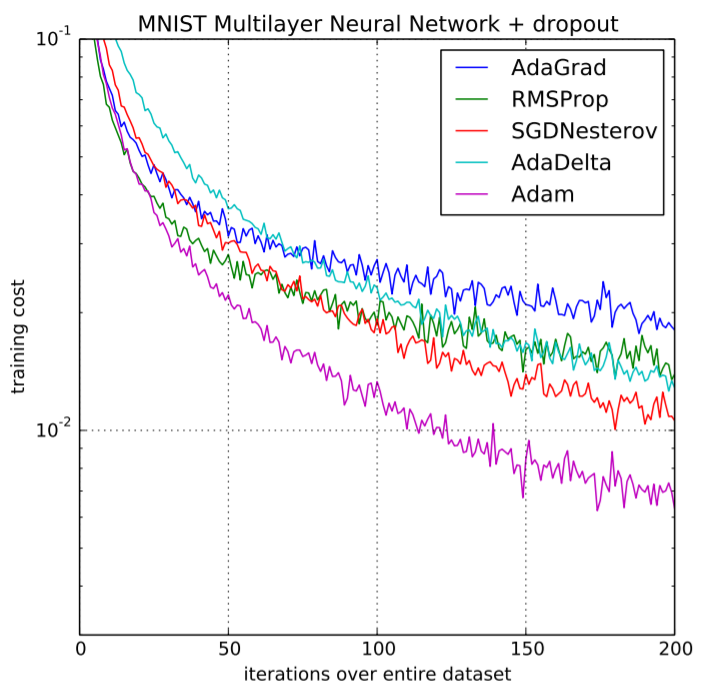
训练成本的性能比较