如何修复:Pandas 中的 KeyError
在本文中,我们将讨论如何修复 Pandas 中的 KeyError。当我们尝试访问 DataFrame 中不存在的某些列/行标签时,会发生 Pandas KeyError 。通常,当您拼错列/行名称或在列/行名称之前或之后包含不需要的空格时,会发生此错误。
所用数据集的链接在这里
例子
Python3
# importing pandas as pd
import pandas as pd
# using .read_csv method to import dataset
df = pd.read_csv('data.csv')Python3
# intentionally passing wrong spelling of
# the key present in dataset
df['country']Python3
# printing all columns of the dataframe
print(df.columns.tolist())Python3
# printing the column 'Country'
df['Country']Python3
# Again using incorrect spelling of the
# column name 'Country' but this time
# we will use df.get method with default
# value "no_country"
df.get('country', default="no_country")Python3
# printing column 'Country'
df.get('Country', default="no_country")输出:
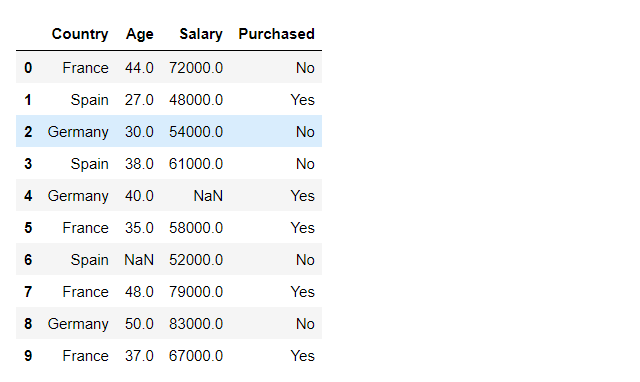
重现 keyError :
Python3
# intentionally passing wrong spelling of
# the key present in dataset
df['country']
输出:
KeyError: 'country'由于没有名称为 country 的列,我们得到一个 KeyError。
如何修复 KeyError?
我们可以通过更正密钥的拼写来简单地修复错误。如果我们不确定拼写,我们可以简单地打印所有列名的列表并进行交叉检查。
Python3
# printing all columns of the dataframe
print(df.columns.tolist())
输出:
['Country', 'Age', 'Salary', 'Purchased']使用列的正确拼写
Python3
# printing the column 'Country'
df['Country']
输出:
0 France
1 Spain
2 Germany
3 Spain
4 Germany
5 France
6 Spain
7 France
8 Germany
9 France
Name: Country, dtype: object如果我们想避免在传递无效键时编译器引发错误,我们可以使用 df.get('your column') 来打印列值。如果密钥无效,则不会引发错误。
Syntax : DataFrame.get( ‘column_name’ , default = default_value_if_column_is_not_present)
Python3
# Again using incorrect spelling of the
# column name 'Country' but this time
# we will use df.get method with default
# value "no_country"
df.get('country', default="no_country")
输出:
'no_country'但是当我们使用正确的拼写时,我们将得到列的值而不是默认值。
Python3
# printing column 'Country'
df.get('Country', default="no_country")
输出:
0 France
1 Spain
2 Germany
3 Spain
4 Germany
5 France
6 Spain
7 France
8 Germany
9 France
Name: Country, dtype: object