使用 TF-IDF 向量化和余弦相似度的基于情节摘要的电影推荐器
可以使用基于内容的过滤和协同过滤方法以多种方式向用户推荐电影。基于内容的过滤方法主要关注项目相似性,即电影中的相似性,而协同过滤则关注在观看电影时绘制相似选择的不同用户之间的关系。
根据用户过去看过的电影情节,可以向用户推荐情节相似的电影。这种方法属于基于内容的过滤,因为推荐仅基于用户过去的活动。
使用的数据集:从维基百科抓取并包含电影情节摘要的 kaggle 数据集。
代码:读取数据集:
# Give the location of the dataset
path_dataset =""
import pandas as pd
data = pd.read_csv(path_dataset)
data.head()
输出: 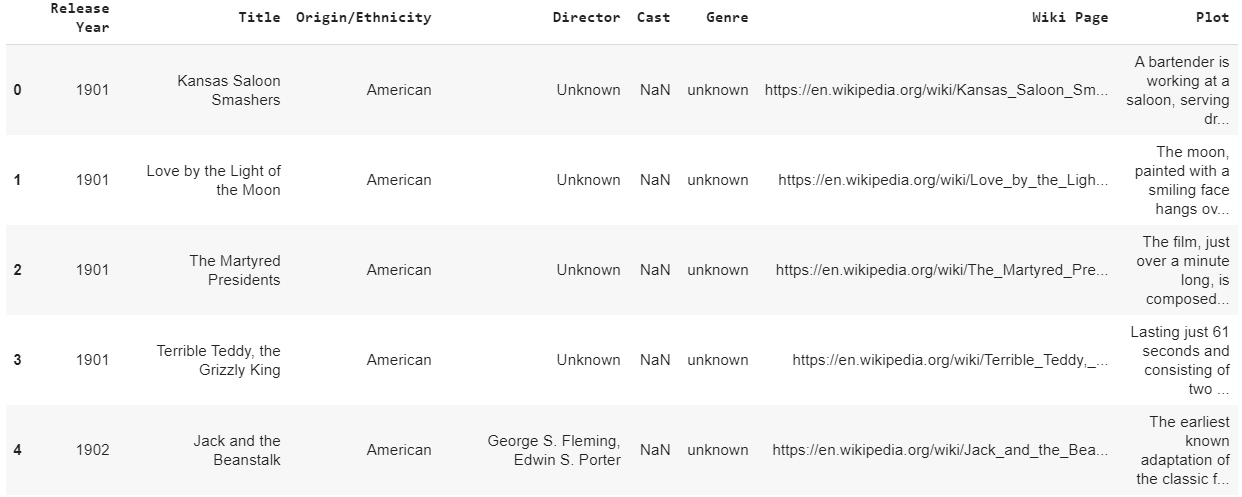
数据集中有不同数量的属于不同语言/来源的电影。
代码:
len(data)
import numpy as np
np.unique(data['Origin / Ethnicity']
len(data.loc[data['Origin / Ethnicity']=='American'])
len(data.loc[data['Origin / Ethnicity']=='British'])
输出:
34886 #Length of the dataset (Total number of rows/movies)
#Movies of various origins present in the dataset.
array(['American', 'Assamese', 'Australian', 'Bangladeshi', 'Bengali',
'Bollywood', 'British', 'Canadian', 'Chinese', 'Egyptian',
'Filipino', 'Hong Kong', 'Japanese', 'Kannada', 'Malayalam',
'Malaysian', 'Maldivian', 'Marathi', 'Punjabi', 'Russian',
'South_Korean', 'Tamil', 'Telugu', 'Turkish'], dtype=object)
17377 #Number of movies of American origin
3670 #Number of movies of British origin
在数据集中的不同列中,只有所需的列是电影名称和电影情节。考虑到上述数据集的一个子集,我们只使用美国和英国电影。子集数据集由 21047 部电影组成。
代码:
# Concatenating American and British movies
df1 = pd.DataFrame(data.loc[data['Origin / Ethnicity']=='American'])
df2 = pd.DataFrame(data.loc[data['Origin / Ethnicity']=='British'])
data = pd.concat([df1, df2], ignore_index = True)
len(data)
finaldata = data[["Title", "Plot"]] # Required columns - Title and movie plot
finaldata = finaldata.set_index('Title') # Setting the movie title as index
finaldata.head(10)
finaldata["Plot"][0]
输出:
21047 #新数据集中的行数 #新数据集中的前10行 #第一部电影的情节调酒师在沙龙工作,为顾客提供饮料。在他给一个典型的爱尔兰男人的桶装满啤酒后,Carrie Nation 和她的追随者冲了进来。他们袭击了那个爱尔兰人,把他的帽子拉到他的眼睛上,然后把啤酒倒在他的头上。然后,这群人开始破坏酒吧,砸坏固定装置、镜子,并破坏收银机。然后,在一群警察出现并命令所有人离开之前,酒保将苏打水喷在 Nation 的脸上。 [1]
#第一部电影的情节调酒师在沙龙工作,为顾客提供饮料。在他给一个典型的爱尔兰男人的桶装满啤酒后,Carrie Nation 和她的追随者冲了进来。他们袭击了那个爱尔兰人,把他的帽子拉到他的眼睛上,然后把啤酒倒在他的头上。然后,这群人开始破坏酒吧,砸坏固定装置、镜子,并破坏收银机。然后,在一群警察出现并命令所有人离开之前,酒保将苏打水喷在 Nation 的脸上。 [1]
代码:应用自然语言处理技术对电影情节进行预处理:
import nltk
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')
nltk.download('wordnet')
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
from nltk.corpus import stopwords
nltk.download('stopwords')
stop_words = set(stopwords.words('english'))
VERB_CODES = {'VB', 'VBD', 'VBG', 'VBN', 'VBP', 'VBZ'}
数据预处理步骤:
- 将情节摘要转换为标记,使用 NLTK 单词标记器。
- 使用 NLTK POS 标记器,提取令牌的 POS 标记。
- 词形还原被认为比词干更好,因为词形还原对单词进行形态分析。
- 词形还原是通过 NLTK Word-net lemmatizer 删除标记的屈折词尾来完成的。
- 常用词被删除以增加标记的重要性。从 NLTK 库中,英语停用词被下载并从电影情节中删除。
- 很少有一般的缩略词被原始词代替。
代码:
def preprocess_sentences(text):
text = text.lower()
temp_sent =[]
words = nltk.word_tokenize(text)
tags = nltk.pos_tag(words)
for i, word in enumerate(words):
if tags[i][1] in VERB_CODES:
lemmatized = lemmatizer.lemmatize(word, 'v')
else:
lemmatized = lemmatizer.lemmatize(word)
if lemmatized not in stop_words and lemmatized.isalpha():
temp_sent.append(lemmatized)
finalsent = ' '.join(temp_sent)
finalsent = finalsent.replace("n't", " not")
finalsent = finalsent.replace("'m", " am")
finalsent = finalsent.replace("'s", " is")
finalsent = finalsent.replace("'re", " are")
finalsent = finalsent.replace("'ll", " will")
finalsent = finalsent.replace("'ve", " have")
finalsent = finalsent.replace("'d", " would")
return finalsent
finaldata["plot_processed"]= finaldata["Plot"].apply(preprocess_sentences)
finaldata.head()
预处理后的数据: 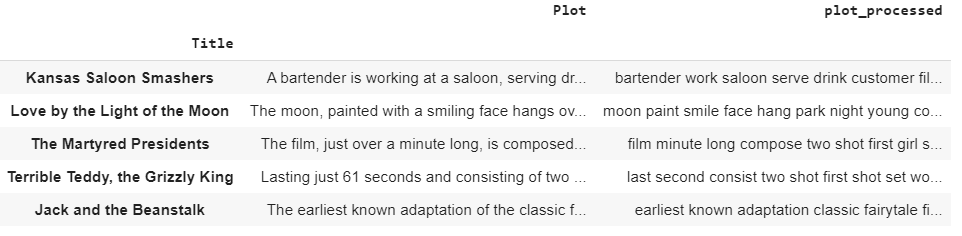
TF-IDF(词频-逆文档频率)矢量化:
- 词频(TF):一个词在文档中出现的次数除以文档中的总词数。每个文档都有自己的词频。
- 逆数据频率 (IDF):文档数除以包含该词的文档数的对数。逆数据频率决定了语料库中所有文档的稀有词的权重。
Scikit-Learn 在名为feature_extraction.text的模块中提供了一个名为TfidfVectorizer的转换器,用于使用 TF-IDF 分数进行矢量化。
余弦相似度:
电影情节被转换为几何空间中的向量。因此,两个向量之间的角度表示这两个向量的接近程度。余弦相似度通过测量两个向量之间夹角的余弦来计算相似度。
代码:
from sklearn.feature_extraction.text import TfidfVectorizer
# Vectorizing pre-processed movie plots using TF-IDF
tfidfvec = TfidfVectorizer()
tfidf_movieid = tfidfvec.fit_transform((finaldata["plot_processed"]))
# Finding cosine similarity between vectors
from sklearn.metrics.pairwise import cosine_similarity
cos_sim = cosine_similarity(tfidf_movieid, tfidf_movieid)
代码:构建推荐函数,提供前 10 部类似电影:
# Storing indices of the data
indices = pd.Series(finaldata.index)
def recommendations(title, cosine_sim = cos_sim):
recommended_movies = []
index = indices[indices == title].index[0]
similarity_scores = pd.Series(cosine_sim[index]).sort_values(ascending = False)
top_10_movies = list(similarity_scores.iloc[1:11].index)
for i in top_10_movies:
recommended_movies.append(list(finaldata.index)[i])
return recommended_movies
代码:使用上述函数获取基于情节的建议:
recommendations("Harry Potter and the Chamber of Secrets")
输出:
Recommendations for the movie "Harry Potter and the Chamber of Secrets"
["Harry Potter and the Sorcerer's Stone",
"Harry Potter and the Philosopher's Stone",
'Harry Potter and the Deathly Hallows: Part I',
'Harry Potter and the Deathly Hallows: Part 1',
'Harry Potter and the Half-Blood Prince',
'Harry Potter and the Deathly Hallows: Part II',
'Harry Potter and the Deathly Hallows: Part 2',
'Harry Potter and the Order of the Phoenix',
'Harry Potter and the Goblet of Fire',
'Harry Potter and the Prisoner of Azkaban']
代码:
recommendations("Ice Age")
输出:
Recommendations for the movie "Ice Age"
['Ice Age: The Meltdown',
'Ice Age: Dawn of the Dinosaurs',
'The Wrong Man',
'Ice Age: Continental Drift',
'The Buttercup Chain',
'Ice Age: Collision Course',
'Runaway Train',
'Corrina, Corrina',
'Sid and Nancy',
'Zorro, the Gay Blade']
代码:
recommendations("Blackmail")
输出:
Recommendations for the movie "Blackmail"
['Checkpoint',
'Odds Against Tomorrow',
'The Beast with Five Fingers',
'Fruitvale Station',
'The Exile',
'The Black Swan',
'Small Town Gay Bar',
'Eye of the Cat',
'Blown Away',
'Brenda Starr, Reporter']