校准曲线
通常,对于任何分类问题,我们都会预测最有可能成为真实类标签的类值。然而,有时,我们想要预测一个数据实例属于每个类标签的概率。例如,假设我们正在构建一个对水果进行分类的模型,并且我们有三个类别标签:苹果、橙子和香蕉(每种水果都是其中之一)。对于任何水果,我们想要水果是苹果、橙子或香蕉的概率。
这对于评估分类模型非常有用。它可以帮助我们了解模型在预测类别标签时的“确定性”程度,并可以帮助我们解释分类模型的决定性。通常,具有预测每个类标签的线性概率的分类器称为校准的。问题是,并非所有分类模型都经过校准。
有些模型对类别概率的估计可能很差,有些甚至不支持概率预测。
校准曲线:
校准曲线用于评估分类器的校准程度,即预测每个类别标签的概率如何不同。 x 轴表示每个 bin 中的平均预测概率。 y 轴是阳性率(阳性预测的比例)。理想校准模型的曲线是从 (0, 0) 线性移动的直线直线。
在 Python3 中绘制校准曲线:
对于此示例,我们将使用二进制数据集。我们将使用流行的糖尿病数据集。您可以在此处了解有关此数据集的更多信息。
代码:实现支持向量机的校准曲线并将其与完美校准模型的曲线进行比较。
Python3
# Importing required modules
from sklearn.datasets import load_breast_cancer
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.calibration import calibration_curve
import matplotlib.pyplot as plt
# Loading dataset
dataset = load_breast_cancer()
X = dataset.data
y = dataset.target
# Splitting dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size = 0.1, random_state = 13)
# Creating and fitting model
model = SVC()
model.fit(X_train, y_train)
# Predict Probabilities
prob = model.decision_function(X_test)
# Creating Calibration Curve
x, y = calibration_curve(y_test, prob, n_bins = 10, normalize = True)
# Plot calibration curve
# Plot perfectly calibrated
plt.plot([0, 1], [0, 1], linestyle = '--', label = 'Ideally Calibrated')
# Plot model's calibration curve
plt.plot(y, x, marker = '.', label = 'Support Vector Classifier')
leg = plt.legend(loc = 'upper left')
plt.xlabel('Average Predicted Probability in each bin')
plt.ylabel('Ratio of positives')
plt.show()输出:
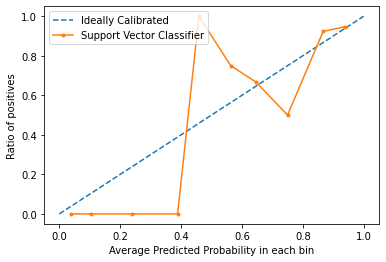
从图中我们可以清楚地看到,支持向量分类器也没有很好地校准。模型曲线越接近完美的校准模型曲线(虚线),校准越好。
结论:
既然您知道了机器学习方面的校准以及如何绘制校准曲线,下次当您的分类器给出不可预测的结果并且您找不到原因时,请尝试绘制校准曲线并检查模型是否校准良好.