Python| Pandas 使用 .loc[] 提取行
Python是一种用于进行数据分析的出色语言,主要是因为以数据为中心的Python包的奇妙生态系统。 Pandas就是其中之一,它使导入和分析数据变得更加容易。
Pandas 提供了一种从数据框中检索行的独特方法。 DataFrame.loc[]方法是一种仅采用索引标签并在调用者数据帧中存在索引标签时返回行或数据帧的方法。
Syntax: pandas.DataFrame.loc[]
Parameters:
Index label: String or list of string of index label of rows
Return type: Data frame or Series depending on parameters
要下载代码中使用的 CSV,请单击此处。
示例 #1:提取单行
在此示例中,将 Name 列作为索引列,然后使用行的索引标签以系列的形式逐一提取两个单行。
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv", index_col ="Name")
# retrieving row by loc method
first = data.loc["Avery Bradley"]
second = data.loc["R.J. Hunter"]
print(first, "\n\n\n", second)
输出:
如输出图像所示,由于两次都只有一个参数,因此返回了两个系列。 
示例 #2:多个参数
在此示例中,将 Name 列作为索引列,然后通过将列表作为参数传递,同时提取两个单行。
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv", index_col ="Name")
# retrieving rows by loc method
rows = data.loc[["Avery Bradley", "R.J. Hunter"]]
# checking data type of rows
print(type(rows))
# display
rows
输出:
如输出图像所示,这次返回值的数据类型是数据帧。这两行都被提取并显示为一个新的数据框。 
示例 #3:提取具有相同索引的多行
在此示例中,将团队名称作为索引列,并将一个团队名称传递给 .loc 方法以检查是否已返回具有相同团队名称的所有值。
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv", index_col ="Team")
# retrieving rows by loc method
rows = data.loc["Utah Jazz"]
# checking data type of rows
print(type(rows))
# display
rows
输出:
如输出图像所示,所有球队名称为“Utah Jazz”的行都以数据框的形式返回。 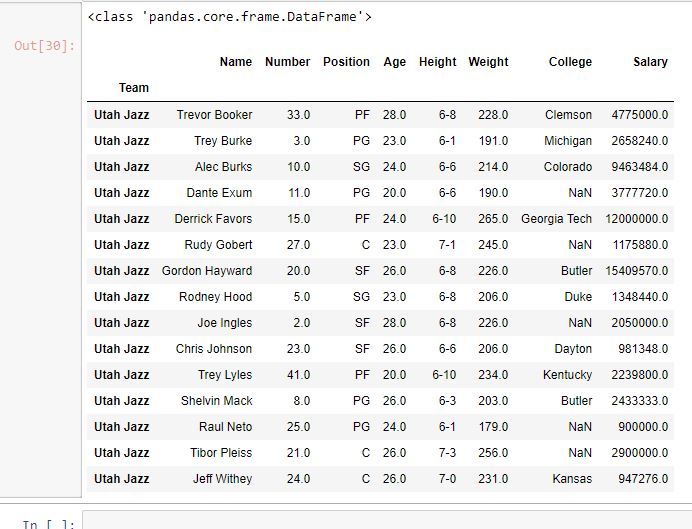
示例 #4:提取两个索引标签之间的行
在此示例中,传递了行的两个索引标签,并返回了位于这两个索引标签之间的所有行(包括两个索引标签)。
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv", index_col ="Name")
# retrieving rows by loc method
rows = data.loc["Avery Bradley":"Isaiah Thomas"]
# checking data type of rows
print(type(rows))
# display
rows
输出:
如输出图像所示,位于传递的两个索引标签之间的所有行都以数据框的形式返回。 