规范化 Pandas 中的列
在本文中,我们将学习如何在 Pandas 中规范化一列。让我们先讨论一些概念:
- Pandas: Pandas 是一个建立在 NumPy 库之上的开源库。它是一个Python包,提供用于处理数值数据和统计的各种数据结构和操作。它主要用于更轻松地导入和分析数据。 Pandas 速度快,对用户来说是高性能和高效的。
- 数据规范化:数据规范化也可能是机器学习中的一种典型做法,它包括将数字列转换为标准比例。在机器学习中,某些特征值与其他特征值多次不同。具有较高值的特征将主导学习过程。
需要的步骤
在这里,我们将应用一些技术来规范化列值,并在示例的帮助下讨论这些。为此,让我们了解使用 Pandas 进行规范化所需的步骤。
- 导入库(熊猫)
- 导入/加载/创建数据。
- 使用该技术对列进行归一化。
例子:
在这里,我们通过一些随机值创建数据并对列应用一些规范化技术。
Python3
# importing packages
import pandas as pd
# create data
df = pd.DataFrame({'Column 1':[200,-4,90,13.9,5,
-90,20,300.7,30,-200,400],
'Column 2':[20,30,23,45,19,38,
25,45,34,37,12]})
# view data
display(df)Python3
df['Column 1'].plot(kind = 'bar')Python3
# copy the data
df_max_scaled = df.copy()
# apply normalization techniques on Column 1
column = 'Column 1'
df_max_scaled[column] = df_max_scaled[column] /df_max_scaled[column].abs().max()
# view normalized data
display(df_max_scaled)Python3
# copy the data
df_min_max_scaled = df.copy()
# apply normalization techniques by Column 1
column = 'Column 1'
df_min_max_scaled[column] = (df_min_max_scaled[column] - df_min_max_scaled[column].min()) / (df_min_max_scaled[column].max() - df_min_max_scaled[column].min())
# view normalized data
display(df_min_max_scaled)Python3
df_min_max_scaled['Column 1'].plot(kind = 'bar')Python3
# copy the data
df_z_scaled = df.copy()
# apply normalization technique to Column 1
column = 'Column 1'
df_z_scaled[column] = (df_z_scaled[column] - df_z_scaled[column].mean()) / df_z_scaled[column].std()
# view normalized data
display(df_z_scaled)Python3
df_z_scaled['Column 1'].plot(kind = 'bar')Python3
from sklearn.preprocessing import MinMaxScaler
import numpy as np
# copy the data
df_sklearn = df.copy()
# apply normalization techniques
column = 'Column 1'
df_sklearn[column] = MinMaxScaler().fit_transform(np.array(df_sklearn[column]).reshape(-1,1))
# view normalized data
display(df_sklearn)Python3
df_sklearn['Column 1'].plot(kind = 'bar')输出:
数据集由两列组成,其中第 1 列未标准化,但第 2 列已标准化。所以我们在第 1 列中应用归一化技术。
蟒蛇3
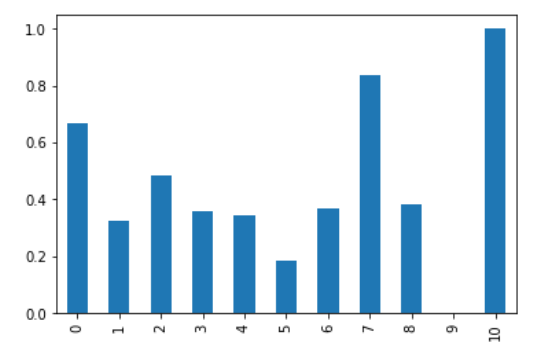
df['Column 1'].plot(kind = 'bar')
输出:
使用最大绝对缩放:
最大绝对缩放通过将每个观测值除以其最大绝对值来重新缩放 -1 和 1 之间的每个特征。我们可以使用 .max() 和 .abs() 方法在 Pandas 中应用最大绝对缩放,如下所示。
蟒蛇3
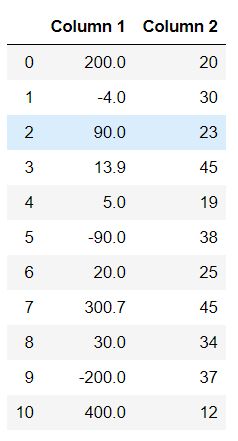
# copy the data
df_max_scaled = df.copy()
# apply normalization techniques on Column 1
column = 'Column 1'
df_max_scaled[column] = df_max_scaled[column] /df_max_scaled[column].abs().max()
# view normalized data
display(df_max_scaled)
输出:

使用最小-最大特征缩放:
min-max 方法(通常称为归一化)通过减去特征的最小值然后除以范围,将特征重新缩放到 [0,1] 的硬且快速的范围。我们可以使用 .min() 和 .max() 方法在 Pandas 中应用最小-最大缩放。
蟒蛇3
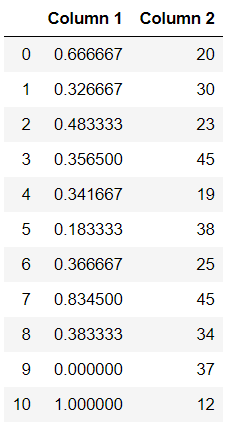
# copy the data
df_min_max_scaled = df.copy()
# apply normalization techniques by Column 1
column = 'Column 1'
df_min_max_scaled[column] = (df_min_max_scaled[column] - df_min_max_scaled[column].min()) / (df_min_max_scaled[column].max() - df_min_max_scaled[column].min())
# view normalized data
display(df_min_max_scaled)
输出 :
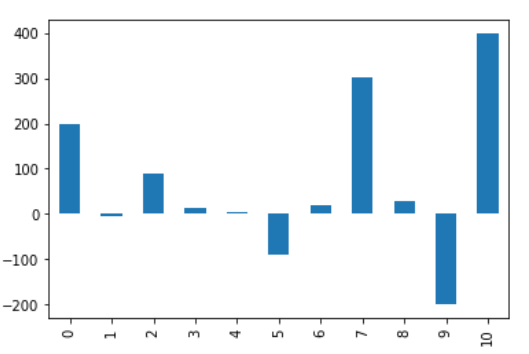
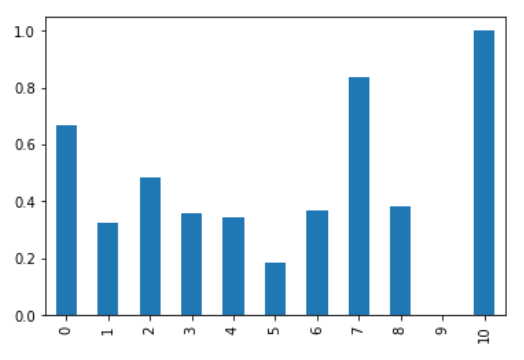
让我们来看看这个情节。
蟒蛇3
df_min_max_scaled['Column 1'].plot(kind = 'bar')
使用 z-score 方法:
z-score 方法(通常称为标准化)将信息转换为均值为 0 且典型偏差为 1 的分布。通过减去相应特征的均值然后除以质量偏差来计算每个标准化值。
蟒蛇3
# copy the data
df_z_scaled = df.copy()
# apply normalization technique to Column 1
column = 'Column 1'
df_z_scaled[column] = (df_z_scaled[column] - df_z_scaled[column].mean()) / df_z_scaled[column].std()
# view normalized data
display(df_z_scaled)
输出 :
让我们来看看这个情节。
蟒蛇3
df_z_scaled['Column 1'].plot(kind = 'bar')

使用 sklearn:
通过将每个特征缩放到给定范围来转换特征。该估计器单独缩放和转换每个特征,使其在训练集上的给定范围内,例如介于零和一之间。在这里,我们将使用 minmax 缩放器。
蟒蛇3
from sklearn.preprocessing import MinMaxScaler
import numpy as np
# copy the data
df_sklearn = df.copy()
# apply normalization techniques
column = 'Column 1'
df_sklearn[column] = MinMaxScaler().fit_transform(np.array(df_sklearn[column]).reshape(-1,1))
# view normalized data
display(df_sklearn)
输出 :
让我们检查一下这个情节:
蟒蛇3
df_sklearn['Column 1'].plot(kind = 'bar')