- DBMS 中的规范化过程
- DBMS中的规范化过程
- DBMS 中的规范化过程(1)
- DBMS 中的规范化过程(1)
- DBMS 中的规范化过程
- DBMS中的规范化过程(1)
- 组规范化 (1)
- 组规范化 - 无论代码示例
- 规范化 - R 编程语言(1)
- 规范化 Pandas 中的列
- 规范化列表 python (1)
- 规范化 0 到 1 之间的值 python (1)
- 规范化数据python(1)
- 数据库中的非规范化
- 数据库中的非规范化(1)
- 如何规范化 R 中的数据?(1)
- 如何规范化 R 中的数据?
- 规范化 Excel (1)
- 规范化 - R 编程语言代码示例
- pandas 规范化列 - Python (1)
- 规范化列 pandas - Python (1)
- 规范化列表 python 代码示例
- 规范化 0 到 1 之间的值 python 代码示例
- 规范化数据python代码示例
- 数据规范化python代码示例
- 什么是 sql 中的非规范化(1)
- 规范化列 pandas - Python 代码示例
- pandas 规范化列 - Python 代码示例
- 什么是数据规范化?(1)
📅 最后修改于: 2021-01-11 06:18:20 🧑 作者: Mango
功能依赖
功能依赖关系(FD)是关系中两个属性之间的一组约束。功能依赖性说,如果两个元组的属性A1,A2,…,An具有相同的值,那么这两个元组的属性B1,B2,…,Bn必须具有相同的值。
功能相关性由箭头符号(→)表示,即X→Y,其中X在功能上确定Y。左侧属性确定右侧的属性值。
阿姆斯特朗公理
如果F是一组功能依赖关系,则F的闭包(表示为F + )是F逻辑上隐含的所有功能依赖关系的集合。阿姆斯特朗公理是一组规则,当重复应用这些规则时,它们会生成功能依赖关系的关闭。
-
自反规则-如果alpha是一组属性,且beta是is_subset_of alpha,则alpha保持beta。
-
增强规则-如果a→b成立且y是属性集,则ay→by也成立。那就是在依赖关系中添加属性,不会改变基本的依赖关系。
-
可及性规则-与代数中的可及性规则相同,如果a→b成立且b→c成立,那么a→c也成立。 a→b称为确定b的函数。
琐碎的功能依赖
-
琐碎的-如果满足功能依赖(FD)X→Y,其中Y是X的子集,则称为琐碎的FD。琐碎的FD总是成立。
-
非平凡-如果FD X→Y成立,其中Y不是X的子集,则称为非平凡FD。
-
完全不平凡-如果FD X→Y成立,其中x与Y =Φ相交,则称其为完全不平凡FD。
正常化
如果数据库设计不完美,则可能包含异常,这对于任何数据库管理员来说都是一个噩梦。管理具有异常的数据库几乎是不可能的。
-
更新异常-如果数据项分散并且未正确相互链接,则可能导致奇怪的情况。例如,当我们尝试更新一个副本分散在多个地方的数据项时,一些实例得到正确更新,而另一些则保留旧值。这样的实例使数据库处于不一致状态。
-
删除异常-我们试图删除一条记录,但是由于不了解而导致部分记录未被删除,数据也保存在其他地方。
-
插入异常-我们试图将数据插入根本不存在的记录中。
规范化是一种消除所有这些异常并使数据库进入一致状态的方法。
第一范式
在关系(表)本身的定义中定义了第一范式。该规则定义关系中的所有属性必须具有原子域。原子域中的值是不可分割的单位。
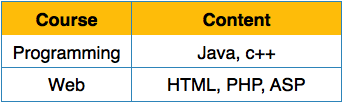
我们如下重新排列关系(表),以将其转换为第一范式。
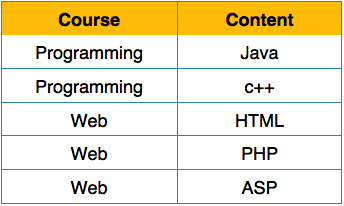
每个属性必须仅包含来自其预定义域的单个值。
第二范式
在学习第二种范式之前,我们需要了解以下内容-
-
素数属性-作为候选关键字一部分的属性称为素数属性。
-
非素数属性-不是素数键的一部分的属性被称为非素数属性。
如果我们遵循第二范式,则每个非主属性都应在功能上完全依赖主键属性。也就是说,如果X→A成立,则不应有X的任何适当子集Y,对于Y→A也成立。
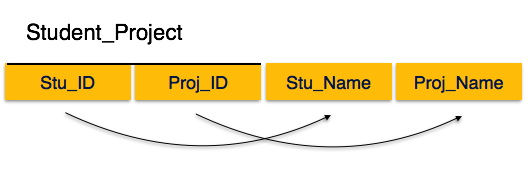
我们在Student_Project关系中看到主键属性是Stu_ID和Proj_ID。根据规则,非键属性(即Stu_Name和Proj_Name)必须都依赖于两者,而不是分别依赖于任何主键属性。但是我们发现Stu_Name可以由Stu_ID标识,而Proj_Name可以由Proj_ID标识。这称为部分依赖,在第二范式中是不允许的。
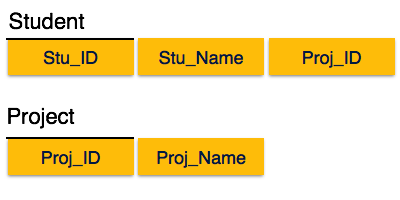
如上图所示,我们将关系分为两部分。因此,不存在部分依赖性。
第三范式
为了使关系处于第三范式,它必须处于第二范式,并且必须满足以下条件:
- 没有任何非主键属性都不能暂时依赖主键属性。
- 对于任何非平凡的函数依赖关系,X→A,然后-
- X是超键或,
- A是主要属性。

我们发现在上面的Student_detail关系中,Stu_ID是键,也是唯一的主键属性。我们发现,可以通过Stu_ID以及Zip本身来标识City。 Zip既不是超级键,也不是City是主要属性。另外,Stu_ID→邮政编码→城市,因此存在传递依赖项。
为了使该关系成为第三范式,我们将该关系分为两个关系,如下所示:
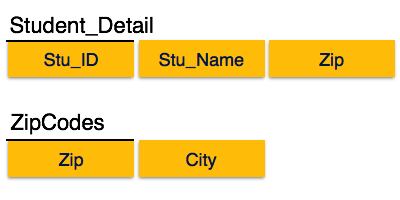
博伊斯·科德范式
Boyce-Codd范式(BCNF)是严格意义上第三范式的扩展。 BCNF指出-
- 对于任何非平凡的功能依赖性,X→A,X必须是一个超键。
在上图中,Stu_ID是关系Student_Detail中的超级键,而Zip是关系ZipCodes中的超级键。所以,
Stu_ID→Stu_Name,邮政编码
和
邮政编码→城市
证实这两个关系都在BCNF中。