MongoDB——复制和分片
在 MongoDB 数据库扩展的上下文中,它具有一些称为复制和分片的功能。复制可以简单地理解为数据集的复制,而分片是将数据集划分为离散的部分。通过分片,您将收藏分为不同的部分。复制数据库意味着您制作数据集的成像器。就交付的功能而言。
复制
复制是跨多个服务器复制数据的方法。例如,我们有一个应用程序,它读取数据并将数据写入数据库,并说此服务器 A 有一个名称和余额,它将被复制/复制到两个不同位置的另外两个服务器。
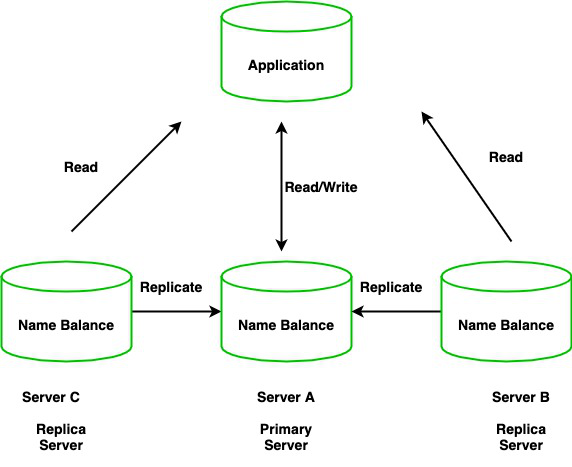
通过这样做,将获得冗余并通过不同数据库服务器上的多个数据副本提高数据可用性。因此,它将提高读取缩放的性能。维护相同数据副本的服务器集称为副本服务器或 MongoDB 实例。
复制主要特点:
- 副本集是维护相同数据集副本的 N 个不同节点的集群。
- 主服务器接收所有的写操作并记录所有的数据变化,即oplog。
- 然后,次要成员在异步过程中复制并应用这些更改。
- 所有的辅助节点都与主节点相连。有一个来自主节点的心跳信号。如果主服务器出现故障,合格的辅助服务器将持有新的主服务器。
为什么要复制?
- 数据容灾高可用
- 无需停机维护(例如备份索引重建和压缩)
- 读取缩放(要读取的额外副本)
复制是如何形成的?
为了在 MongoDB 中执行复制,我们需要首先创建副本集并授予脚本文件的权限。 –replSet 的基本语法是 -
mongod --port "PORT" --dbpath "YOUR_DB_DATA_PATH" --replSet "REPLICA_SET_INSTANCE_NAME"要么
create a ".sh" file create_replicaset.sh and init_mongoreplica.js例子:


然后运行以下脚本:
./create_replicaset.sh- 将创建目录,然后运行 mongo。
- 在 Mongo 终端中,使用命令 rs.initiate() 来启动一个新的副本集。
分片
分片是一种跨多台机器分配数据的方法。 MongoDB 使用分片来帮助部署非常大的数据集和大吞吐量的操作。通过分片,你可以组合更多的设备来承载数据扩展和读写操作的需要。
为什么分片?
- 具有大数据集或高吞吐量请求的数据库系统可能会怀疑单个服务器的能力。
- 例如,高查询流会耗尽服务器的 CPU 限制。
- 工作集大小大于系统的 RAM,以强调磁盘驱动器的 I/O 容量。
分片是如何工作的?
分片确定了水平扩展破坏系统数据集并存储在多个服务器上的问题,根据需要添加新服务器以增加容量。

现在,我们有多个称为 Shard 的服务器,而不是一个信号作为主要信号。我们有不同的路由服务器将数据路由到分片服务器。例如:假设我们有数据 1、数据 2 和数据 3,这将发送到路由服务器,路由服务器将路由数据(即,不同的数据将发送到特定的 Shard)每个 Shard 都包含一些数据。在这里,配置服务器将保存元数据,并将配置路由服务器以将特定数据集成到分片,但是配置服务器是 MongoDB 实例,如果它发生故障,那么整个服务器将发生故障,因此它再次具有副本配置数据库。
分片的优点:
- 分片将更多服务器添加到数据字段中,自动调整跨各种服务器的数据负载。
- 每个分片管理的操作数量减少了。
- 它还通过将写入负载拆分到多个实例来增加写入容量。
- 由于为分片和配置部署了副本服务器,它提供了高可用性。
- 通过添加多个分片,总容量将增加。
为了在 MongoDB 中创建分片集群,我们需要配置分片、配置服务器和查询路由器。