Python|使用 NLTK 按名称进行性别识别
自然语言工具包 (NLTK)是一个用于构建文本分析程序的平台。我们可以观察到男性和女性的名字有一些鲜明的特点。以 a、e 和 i 结尾的名字可能是女性,而以 k、o、r、s 和 t 结尾的名字可能是男性。让我们构建一个分类器来更精确地模拟这些差异。
为了运行下面的Python程序,你必须安装 NLTK。请按照安装步骤操作。
pip install nltk创建分类器的第一步是确定输入的哪些特征是相关的,以及如何对这些特征进行编码。对于此示例,我们将从查看给定名称的最后一个字母开始。以下特征提取器函数构建一个字典,其中包含有关给定名称的相关信息。
例子 :
Input : gender_features('saurabh')
Output : {'last_letter': 'h'}Python3
def gender_features(word):
return {'last_letter': word[-1]}
gender_features('mahavir')
# output : {'last_letter': 'r'}Python3
# importing libraries
import random
from nltk.corpus import names
import nltk
def gender_features(word):
return {'last_letter':word[-1]}
# preparing a list of examples and corresponding class labels.
labeled_names = ([(name, 'male') for name in names.words('male.txt')]+
[(name, 'female') for name in names.words('female.txt')])
random.shuffle(labeled_names)
# we use the feature extractor to process the names data.
featuresets = [(gender_features(n), gender)
for (n, gender)in labeled_names]
# Divide the resulting list of feature
# sets into a training set and a test set.
train_set, test_set = featuresets[500:], featuresets[:500]
# The training set is used to
# train a new "naive Bayes" classifier.
classifier = nltk.NaiveBayesClassifier.train(train_set)
print(classifier.classify(gender_features('mahavir')))
# output should be 'male'
print(nltk.classify.accuracy(classifier, train_set))
# it shows accuracy of our classifier and
# train_set. which must be more than 99 %
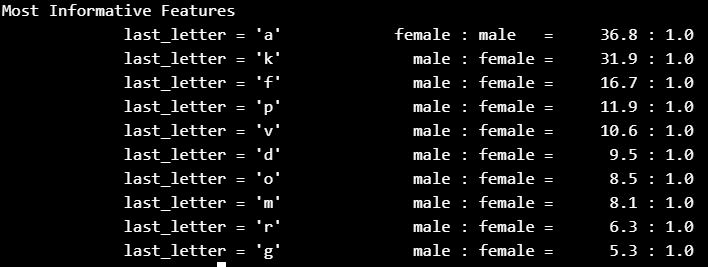
# classifier.show_most_informative_features(10)Python3
classifier.show_most_informative_features(10)
# 10 indicates 10 rows将弹出一个 GUI,然后选择下载所有包的“全部”,然后单击“下载”。这将为您提供所有标记器、分块器、其他算法和所有语料库,这就是安装需要相当长的时间的原因。
nltk.download()分类是为给定输入选择正确类别标签的任务。在基本分类任务中,每个输入都被认为与所有其他输入隔离,并且标签集是预先定义的。分类任务的一些示例是:
- 确定电子邮件是否为垃圾邮件。
- 从“体育”、“技术”和“政治”等主题领域的固定列表中确定新闻文章的主题是什么。
- 决定某个特定出现的银行一词是否用于指代河岸、金融机构、向一侧倾斜的行为或将某物存入金融机构的行为。
基本分类任务有许多有趣的变体。例如,在多类分类中,每个实例可能被分配多个标签;在开放类分类中,标签集没有预先定义;在序列分类中,输入列表被联合分类。
如果分类器是基于包含每个输入的正确标签的训练语料库构建的,则称为监督分类器。监督分类使用的框架如图所示。 
训练集用于训练模型,开发测试集用于进行错误分析。测试集用于我们对系统的最终评估。由于下面讨论的原因,重要的是我们使用单独的开发测试集进行错误分析,而不仅仅是使用测试集。
将语料库数据划分为不同的子集如下图所示: 
从这里获取使用的文本文件的链接 –
- 直接通过文本网址。男.txt,女.txt
- 当
nltk.download()方法成功执行时,male.txt和female.txt文件会自动下载。本地系统中的路径:
nltk 的路径:C:\Users\currentUserName\AppData\Roaming
nltk 中文件的路径:\nltk_data\corpora\names
Python3
# importing libraries
import random
from nltk.corpus import names
import nltk
def gender_features(word):
return {'last_letter':word[-1]}
# preparing a list of examples and corresponding class labels.
labeled_names = ([(name, 'male') for name in names.words('male.txt')]+
[(name, 'female') for name in names.words('female.txt')])
random.shuffle(labeled_names)
# we use the feature extractor to process the names data.
featuresets = [(gender_features(n), gender)
for (n, gender)in labeled_names]
# Divide the resulting list of feature
# sets into a training set and a test set.
train_set, test_set = featuresets[500:], featuresets[:500]
# The training set is used to
# train a new "naive Bayes" classifier.
classifier = nltk.NaiveBayesClassifier.train(train_set)
print(classifier.classify(gender_features('mahavir')))
# output should be 'male'
print(nltk.classify.accuracy(classifier, train_set))
# it shows accuracy of our classifier and
# train_set. which must be more than 99 %
# classifier.show_most_informative_features(10)
从分类器获取信息特征:
Python3
classifier.show_most_informative_features(10)
# 10 indicates 10 rows
输出: