PySpark 窗口函数
PySpark Window函数对行的组、帧或集合执行排名、行号等统计操作,并分别返回每一行的结果。执行数据转换也越来越流行。我们将了解窗口函数的概念、语法,以及最后如何将它们与 PySpark SQL 和 PySpark DataFrame API 一起使用。
Window函数主要有以下三种类型:
- 分析函数
- 排名函数
- 聚合函数
要先对一组行执行窗口函数操作,我们需要使用 window.partition()函数对数据行进行分区,即定义该组,对于行号和排名函数,我们需要使用 ORDER BY 对分区数据进行额外排序条款。
Syntax for Window.partition:
Window.partitionBy(“column_name”).orderBy(“column_name”)
Syntax for Window function:
DataFrame.withColumn(“new_col_name”, Window_function().over(Window_partition))
让我们通过例子一一理解和实现所有这些功能。
分析功能
分析函数是在对数据或由 SELECT 子句或 ORDER BY 子句分区的有限行集进行操作后返回结果的函数。它以与输入行数相同的行数返回结果。例如,lead()、lag()、cume_dist()。
创建用于演示的数据框:
在我们开始使用这些函数之前,首先我们需要创建一个 DataFrame。我们将创建一个包含员工详细信息的 DataFrame,例如 Employee_Name、Age、Department、Salary。创建 DataFrame 后,我们将在此 DataFrame df 上应用每个分析函数。
Python3
# importing pyspark
from pyspark.sql.window import Window
import pyspark
# importing sparksessio
from pyspark.sql import SparkSession
# creating a sparksession object
# and providing appName
spark = SparkSession.builder.appName("pyspark_window").getOrCreate()
# sample data for dataframe
sampleData = (("Ram", 28, "Sales", 3000),
("Meena", 33, "Sales", 4600),
("Robin", 40, "Sales", 4100),
("Kunal", 25, "Finance", 3000),
("Ram", 28, "Sales", 3000),
("Srishti", 46, "Management", 3300),
("Jeny", 26, "Finance", 3900),
("Hitesh", 30, "Marketing", 3000),
("Kailash", 29, "Marketing", 2000),
("Sharad", 39, "Sales", 4100)
)
# column names for dataframe
columns = ["Employee_Name", "Age",
"Department", "Salary"]
# creating the dataframe df
df = spark.createDataFrame(data=sampleData,
schema=columns)
# importing Window from pyspark.sql.window
# creating a window
# partition of dataframe
windowPartition = Window.partitionBy("Department").orderBy("Age")
# print schema
df.printSchema()
# show df
df.show()Python3
# importing cume_dist()
# from pyspark.sql.functions
from pyspark.sql.functions import cume_dist
# applying window function with
# the help of DataFrame.withColumn
df.withColumn("cume_dist",
cume_dist().over(windowPartition)).show()Python3
# importing lag() from pyspark.sql.functions
from pyspark.sql.functions import lag
df.withColumn("Lag", lag("Salary", 2).over(windowPartition)) \
.show()Python3
# importing lead() from pyspark.sql.functions
from pyspark.sql.functions import lead
df.withColumn("Lead", lead("salary", 2).over(windowPartition)) \
.show()Python3
# importing pyspark
from pyspark.sql.window import Window
import pyspark
# importing sparksessio
from pyspark.sql import SparkSession
# creating a sparksession object and providing appName
spark = SparkSession.builder.appName("pyspark_window").getOrCreate()
# sample data for dataframe
sampleData = ((101, "Ram", "Biology", 80),
(103, "Meena", "Social Science", 78),
(104, "Robin", "Sanskrit", 58),
(102, "Kunal", "Phisycs", 89),
(101, "Ram", "Biology", 80),
(106, "Srishti", "Maths", 70),
(108, "Jeny", "Physics", 75),
(107, "Hitesh", "Maths", 88),
(109, "Kailash", "Maths", 90),
(105, "Sharad", "Social Science", 84)
)
# column names for dataframe
columns = ["Roll_No", "Student_Name", "Subject", "Marks"]
# creating the dataframe df
df2 = spark.createDataFrame(data=sampleData,
schema=columns)
# importing window from pyspark.sql.window
# creating a window partition of dataframe
windowPartition = Window.partitionBy("Subject").orderBy("Marks")
# print schema
df2.printSchema()
# show df
df2.show()Python3
# importing row_number() from pyspark.sql.functions
from pyspark.sql.functions import row_number
# applying the row_number() function
df2.withColumn("row_number",
row_number().over(windowPartition)).show()Python3
# importing rank() from pyspark.sql.functions
from pyspark.sql.functions import rank
# applying the rank() function
df2.withColumn("rank", rank().over(windowPartition)) \
.show()Python3
# importing percent_rank() from pyspark.sql.functions
from pyspark.sql.functions import percent_rank
# applying the percent_rank() function
df2.withColumn("percent_rank",
percent_rank().over(windowPartition)).show()Python3
# importing dense_rank() from pyspark.sql.functions
from pyspark.sql.functions import dense_rank
# applying the dense_rank() function
df2.withColumn("dense_rank",
dense_rank().over(windowPartition)).show()Python3
# importing pyspark
import pyspark
# importing sparksessio
from pyspark.sql import SparkSession
# creating a sparksession
# object and providing appName
spark = SparkSession.builder.appName("pyspark_window").getOrCreate()
# sample data for dataframe
sampleData = (("Ram", "Sales", 3000),
("Meena", "Sales", 4600),
("Robin", "Sales", 4100),
("Kunal", "Finance", 3000),
("Ram", "Sales", 3000),
("Srishti", "Management", 3300),
("Jeny", "Finance", 3900),
("Hitesh", "Marketing", 3000),
("Kailash", "Marketing", 2000),
("Sharad", "Sales", 4100)
)
# column names for dataframe
columns = ["Employee_Name", "Department", "Salary"]
# creating the dataframe df
df3 = spark.createDataFrame(data=sampleData,
schema=columns)
# print schema
df3.printSchema()
# show df
df3.show()Python3
# importing window from pyspark.sql.window
from pyspark.sql.window import Window
# importing aggregate functions
# from pyspark.sql.functions
from pyspark.sql.functions import col,avg,sum,min,max,row_number
# creating a window partition of dataframe
windowPartitionAgg = Window.partitionBy("Department")
# applying window aggregate function
# to df3 with the help of withColumn
# this is average()
df3.withColumn("Avg",
avg(col("salary")).over(windowPartitionAgg))
#this is sum()
.withColumn("Sum",
sum(col("salary")).over(windowPartitionAgg))
#this is min()
.withColumn("Min",
min(col("salary")).over(windowPartitionAgg))
#this is max()
.withColumn("Max",
max(col("salary")).over(windowPartitionAgg)).show()输出:
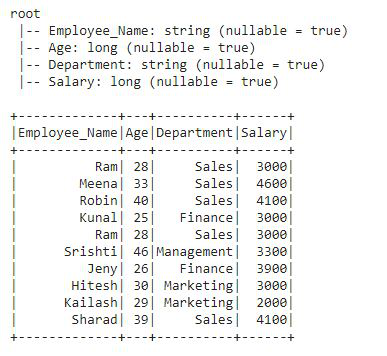
这是我们将应用所有分析函数的 DataFrame。
示例 1:使用 cume_dist()
cume_dist() 窗口函数用于获取窗口分区内的累积分布。它类似于 SQL 中的 CUME_DIST。让我们看一个例子:
蟒蛇3
# importing cume_dist()
# from pyspark.sql.functions
from pyspark.sql.functions import cume_dist
# applying window function with
# the help of DataFrame.withColumn
df.withColumn("cume_dist",
cume_dist().over(windowPartition)).show()
输出:
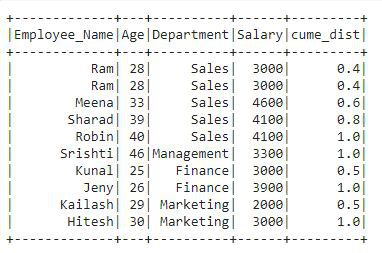
在输出中,我们可以看到一个新列被添加到名为“cume_dist”的 df 中,该列包含按年龄列排序的部门列的累积分布。
示例 2:使用 lag()
甲滞后()函数是用于访问先前行的数据作为每在函数所定义的偏移值。这个函数类似于 SQL 中的 LAG。
蟒蛇3
# importing lag() from pyspark.sql.functions
from pyspark.sql.functions import lag
df.withColumn("Lag", lag("Salary", 2).over(windowPartition)) \
.show()
输出:
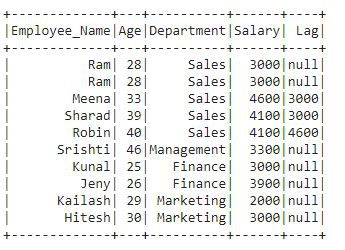
在输出中,我们可以看到滞后列被添加到包含滞后值的 df 中。在前 2 行中有一个空值,因为我们在 lag()函数定义了偏移量 2 后跟列 Salary。下一行包含前一行的值。
示例 3:使用 Lead()
的引线()函数是用于访问下一个行的数据按在函数所定义的偏移值。该函数类似于 SQL 中的 LEAD,与 SQL 中的 lag()函数或 LAG 正好相反。
蟒蛇3
# importing lead() from pyspark.sql.functions
from pyspark.sql.functions import lead
df.withColumn("Lead", lead("salary", 2).over(windowPartition)) \
.show()
输出:
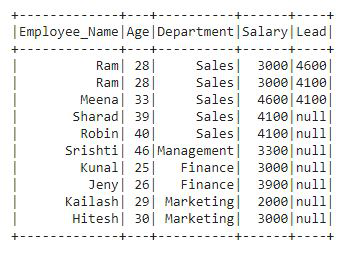
排名函数
该函数返回分区或组中每一行的给定值的统计排名。此函数的目标是为结果列中的行提供连续编号,由 Window.partition 中为 OVER 子句中指定的每个分区选择的顺序设置。例如 row_number()、rank()、dense_rank() 等。
创建用于演示的数据框:
在我们开始使用这些函数之前,首先我们需要创建一个 DataFrame。我们将创建一个包含学生详细信息的 DataFrame,如 Roll_No、Student_Name、Subject、Marks。创建 DataFrame 后,我们将在此 DataFrame df2 上应用每个排名函数。
蟒蛇3
# importing pyspark
from pyspark.sql.window import Window
import pyspark
# importing sparksessio
from pyspark.sql import SparkSession
# creating a sparksession object and providing appName
spark = SparkSession.builder.appName("pyspark_window").getOrCreate()
# sample data for dataframe
sampleData = ((101, "Ram", "Biology", 80),
(103, "Meena", "Social Science", 78),
(104, "Robin", "Sanskrit", 58),
(102, "Kunal", "Phisycs", 89),
(101, "Ram", "Biology", 80),
(106, "Srishti", "Maths", 70),
(108, "Jeny", "Physics", 75),
(107, "Hitesh", "Maths", 88),
(109, "Kailash", "Maths", 90),
(105, "Sharad", "Social Science", 84)
)
# column names for dataframe
columns = ["Roll_No", "Student_Name", "Subject", "Marks"]
# creating the dataframe df
df2 = spark.createDataFrame(data=sampleData,
schema=columns)
# importing window from pyspark.sql.window
# creating a window partition of dataframe
windowPartition = Window.partitionBy("Subject").orderBy("Marks")
# print schema
df2.printSchema()
# show df
df2.show()
输出:
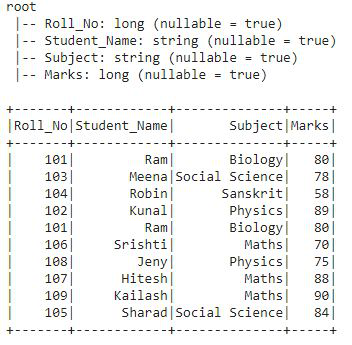
这是我们将在其上应用所有窗口排名函数的 DataFrame df2。
示例 1:使用 row_number()。
row_number()函数用于为表中的每一行提供一个序列号。让我们看看这个例子:
蟒蛇3
# importing row_number() from pyspark.sql.functions
from pyspark.sql.functions import row_number
# applying the row_number() function
df2.withColumn("row_number",
row_number().over(windowPartition)).show()
输出:
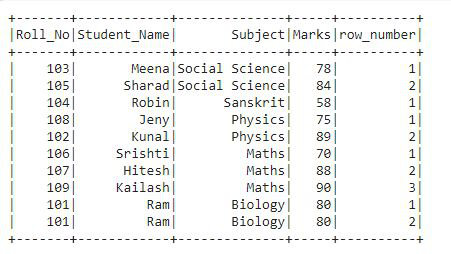
在这个输出中,我们可以看到我们有基于指定分区的每一行的行号,即行号后面是主题和标记列。
示例 2:使用 rank()
rank函数用于对窗口分区中指定的行进行排名。如果有联系,此函数会在排名中留下差距。让我们看看这个例子:
蟒蛇3
# importing rank() from pyspark.sql.functions
from pyspark.sql.functions import rank
# applying the rank() function
df2.withColumn("rank", rank().over(windowPartition)) \
.show()
输出:
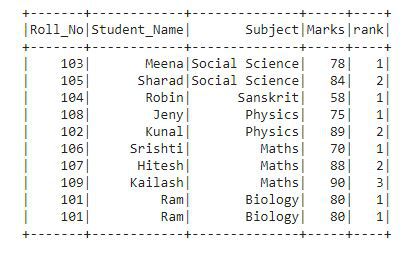
在输出中,排名根据窗口分区中指定的主题和标记列提供给每一行。
示例 3:使用 percent_rank()
此函数类似于 rank()函数。它还为行提供排名,但采用百分位格式。让我们看看这个例子:
蟒蛇3
# importing percent_rank() from pyspark.sql.functions
from pyspark.sql.functions import percent_rank
# applying the percent_rank() function
df2.withColumn("percent_rank",
percent_rank().over(windowPartition)).show()
输出:
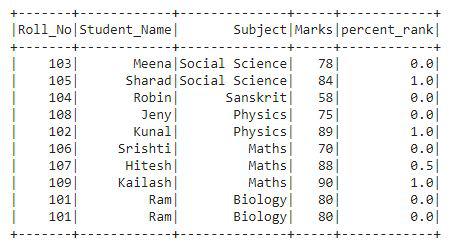
我们可以看到,在输出中,rank 列包含百分位形式的值,即十进制格式。
示例 4:使用dense_rank()
该函数用于以行号的形式获取每一行的排名。这类似于 rank()函数,只有一个不同之处在于 rank函数在有关系时会在排名中留下差距。让我们看看这个例子:
蟒蛇3
# importing dense_rank() from pyspark.sql.functions
from pyspark.sql.functions import dense_rank
# applying the dense_rank() function
df2.withColumn("dense_rank",
dense_rank().over(windowPartition)).show()
输出:
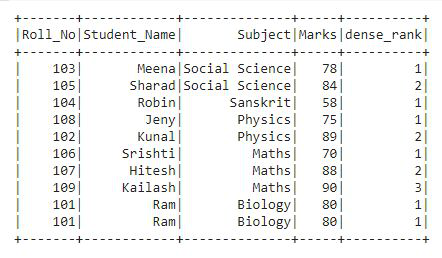
在输出中,我们可以看到排名以行号的形式给出。
聚合函数
一个聚集函数或聚集的函数是,其中多个行的值被组合,以形成一个单一的摘要值的函数。它们操作的行组的定义是通过使用 SQL GROUP BY 子句完成的。例如平均值、总和、最小值、最大值等。
创建用于演示的数据框:
在开始使用这些函数之前,我们将创建一个新的 DataFrame,其中包含员工详细信息,如 Employee_Name、Department 和 Salary。创建 DataFrame 后,我们将在此 DataFrame 上应用每个聚合函数。
蟒蛇3
# importing pyspark
import pyspark
# importing sparksessio
from pyspark.sql import SparkSession
# creating a sparksession
# object and providing appName
spark = SparkSession.builder.appName("pyspark_window").getOrCreate()
# sample data for dataframe
sampleData = (("Ram", "Sales", 3000),
("Meena", "Sales", 4600),
("Robin", "Sales", 4100),
("Kunal", "Finance", 3000),
("Ram", "Sales", 3000),
("Srishti", "Management", 3300),
("Jeny", "Finance", 3900),
("Hitesh", "Marketing", 3000),
("Kailash", "Marketing", 2000),
("Sharad", "Sales", 4100)
)
# column names for dataframe
columns = ["Employee_Name", "Department", "Salary"]
# creating the dataframe df
df3 = spark.createDataFrame(data=sampleData,
schema=columns)
# print schema
df3.printSchema()
# show df
df3.show()
输出:
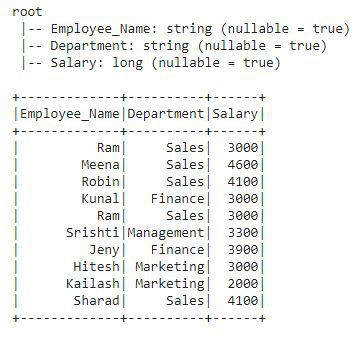
这是我们将应用所有聚合函数的 DataFrame df3。
示例:让我们看看如何通过此示例应用聚合函数
蟒蛇3
# importing window from pyspark.sql.window
from pyspark.sql.window import Window
# importing aggregate functions
# from pyspark.sql.functions
from pyspark.sql.functions import col,avg,sum,min,max,row_number
# creating a window partition of dataframe
windowPartitionAgg = Window.partitionBy("Department")
# applying window aggregate function
# to df3 with the help of withColumn
# this is average()
df3.withColumn("Avg",
avg(col("salary")).over(windowPartitionAgg))
#this is sum()
.withColumn("Sum",
sum(col("salary")).over(windowPartitionAgg))
#this is min()
.withColumn("Min",
min(col("salary")).over(windowPartitionAgg))
#this is max()
.withColumn("Max",
max(col("salary")).over(windowPartitionAgg)).show()
输出:
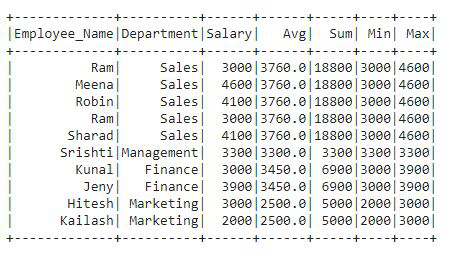
在输出 df 中,我们可以看到向 df 添加了四个新列。在代码中,我们将四个聚合函数都一一应用了。我们在 df3 中添加了四个输出列,其中包含每行的值。这四列包含工资列的平均值、总和、最小值和最大值。