R 编程中的数据争论——使用 Tibbles
R 是一种强大的语言,分析师、数据科学家和业务用户使用它来执行各种任务,例如统计分析、可视化和开发多个领域的统计软件。
数据整理是将原始数据重新映像为更结构化格式的过程,这将有助于从数据中获得更好的洞察力并做出更好的决策。
什么是小标题?
Tibbles 是tidyverse的核心数据结构,用于方便以整洁的格式显示和分析信息。 Tibbles 是一种新形式的数据框,其中数据框是用于在 R 中存储数据集的最常见的数据结构。
Tibbles 相对于数据帧的优势
- 所有 Tidyverse 包都支持 Tibbles。
- Tibbles 以比数据框更清晰的格式打印。
- 数据框通常将字符转换为因子,分析人员通常必须覆盖该设置,而字符串不会尝试自动进行此转换。
创建 Tibbles 的不同方法
- as_tibble():
第一个函数是 tibble函数。此函数用于从现有数据框创建 tibble。Syntax:
as_tibble(x, validate = NULL, …)x is either a data frame, matrix, or list.
- 小标题():
第二种方法是使用tibble()函数,该函数用于从头开始创建 tibble。Syntax:
tibble(s…, rows = NULL)s represents a set of name-value pairs.
- 进口():
最后,您可以使用 tidyverse 的数据导入包从数据库或 CSV 文件等外部数据源创建 Tibbles。Syntax: import(pkgname …)
- 图书馆():
library()函数用于加载包的命名空间。Syntax:
library(package, help, pos = 2, lib.loc = NULL)
Note: To find more about the functions in R, type ? followed by function name. Eg: ?tibble.让我们看一些如何使用 Rstudio IDE 使用上述功能的示例。我们将使用草本植物中的内置数据集 (CO2) 二氧化碳吸收来创建一个小标题。
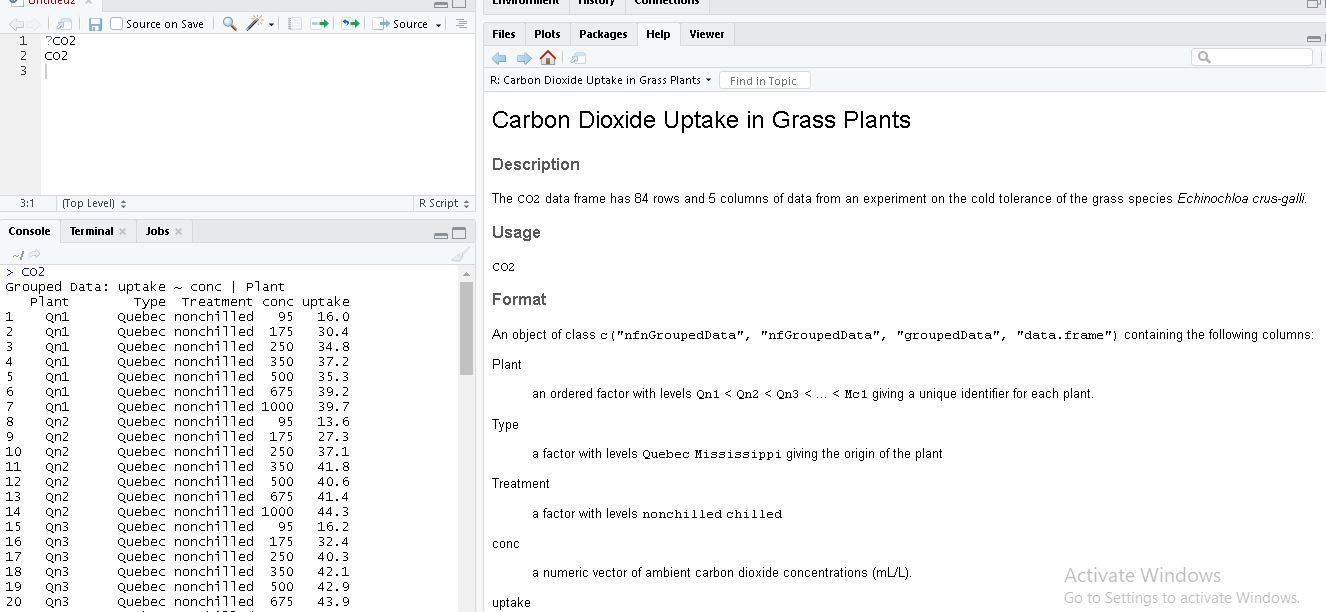
该数据集由几个变量组成,例如植物、类型、处理、浓度和吸收。处理这类信息很困难,所以让我们将这些信息转换为 tibble。让我们使用 as_tibble()函数从 CO2 数据集创建一个名为 sample_tibble 的 tibble。
as_tibble() 示例
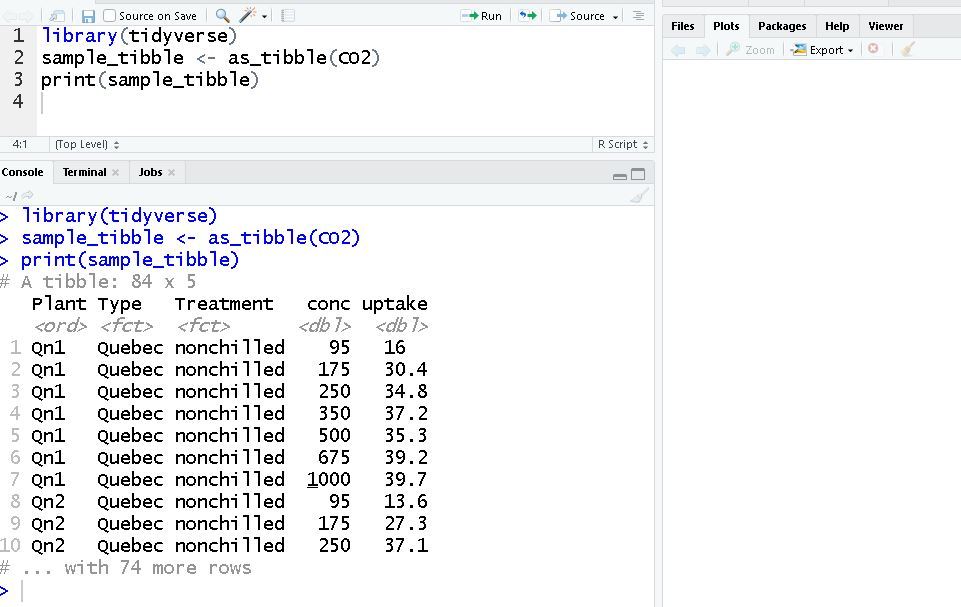
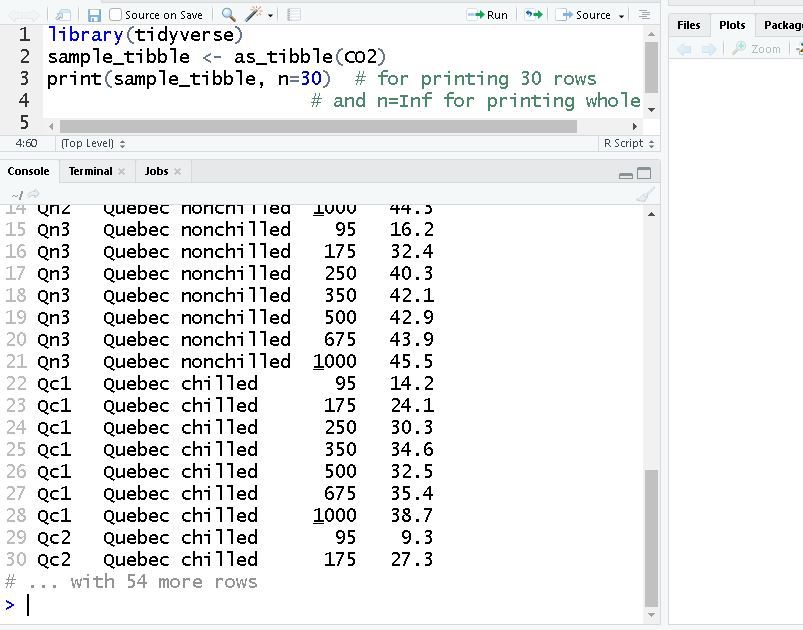
在这里,我们使用as_tibble()函数将数据帧 (CO2) 转换为 tibble。它要求您在 Rstudio 中安装 tidyverse 包。
library(tidyverse) # loading tidyverse package
sample_tibble <- as_tibble(CO2) # creating a tibble named sample_tibble
print(sample_tibble)
输出:
tibble() 示例
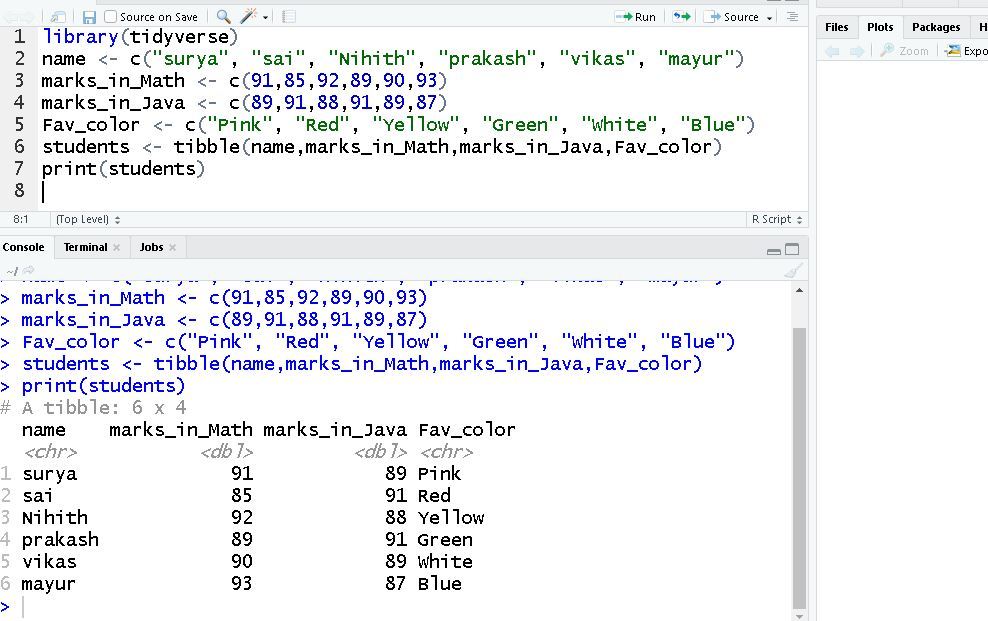
第二种方法是使用tibble()函数从头开始创建一个 tibble,因此我们将创建一些向量,例如 name、marks_in_Math、marks_in_Java、Fav_color 等,并将它们传递给tibble()函数,该函数将它们转换为 tibble。
library(tidyverse)
name <- c("surya", "sai", "Nihith", "prakash", "vikas", "mayur")
marks_in_Math <- c(91, 85, 92, 89, 90, 93)
marks_in_Java <- c(89, 91, 88, 91, 89, 87)
Fav_color <- c("Pink", "Red", "Yellow", "Green", "White", "Blue")
students <- tibble(name, marks_in_Math, marks_in_Java, Fav_color)
print(students)
输出:
子集小标题
数据分析师经常从小标题中提取单个变量以进一步用于他们的分析,这称为子集。当我们尝试对 tibble 进行子集化时,我们从 Tibble 中以向量形式提取单个变量。我们可以通过使用一些特殊的运算符来做到这一点。
- $ 运算符
- [[]] 操作员
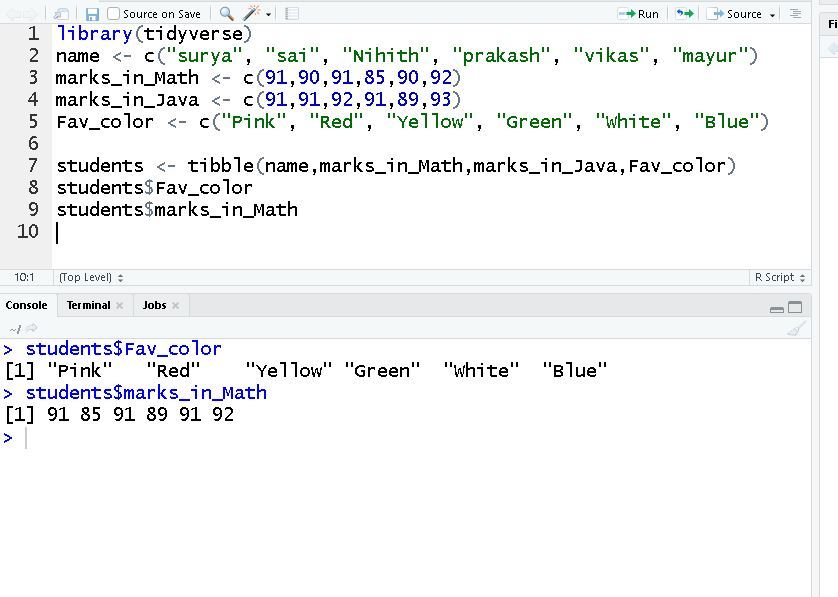
$ 运算符
我们可以从 Tibble 中提取变量的第一种方法是使用美元 ($) 符号运算符。为此,我们将使用tibble()函数从头开始创建一个 tibble。
library(tidyverse)
name <- c("surya", "sai", "Nihith", "prakash", "vikas", "mayur")
marks_in_Math <- c(91, 90, 91, 85, 90, 92)
marks_in_Java <- c(91, 91, 92, 91, 89, 93)
Fav_color <- c("Pink", "Red", "Yellow", "Green", "White", "Blue")
students <- tibble(name, marks_in_Math, marks_in_Java, Fav_color)
students$Fav_color
students$marks_in_Math
输出:
[[]] 操作员
从 Tibble 访问单个变量的第二种方法是使用方括号 ([[]])。我们将使用之前创建的相同 tibble。
library(tidyverse)
name <- c("surya", "sai", "Nihith", "prakash", "vikas", "mayur")
marks_in_Math <- c(91, 90, 91, 85, 90, 92)
marks_in_Java <- c(91, 91, 92, 91, 89, 93)
Fav_color <- c("Pink", "Red", "Yellow", "Green", "White", "Blue")
students <- tibble(name, marks_in_Math, marks_in_Java, Fav_color)
students$Fav_color
students[["name"]]
students[["marks_in_Math"]]
输出: 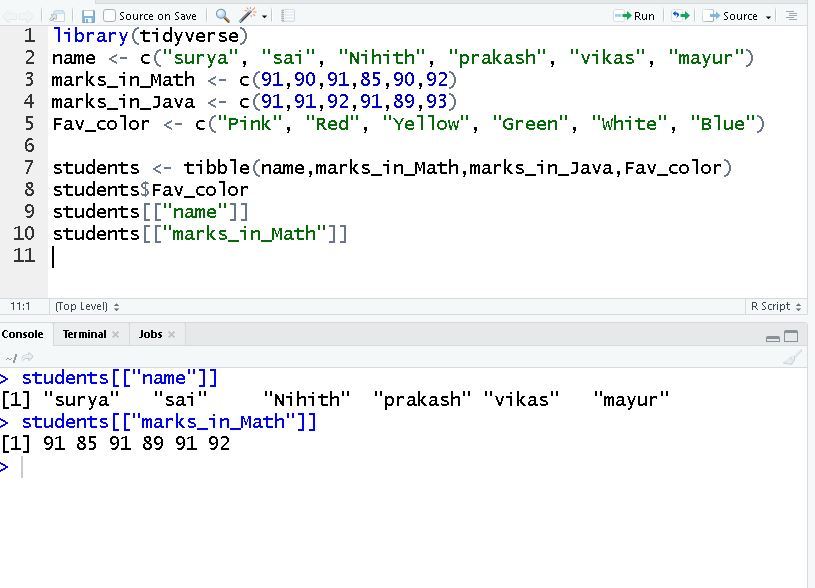
过滤小标题
过滤提供了一种方法来帮助减少 tibble 中的行数。在执行过滤时,我们可以指定用于减少数据集中行数的条件或特定标准。
过滤器()函数:
Syntax: filter(data, conditions)
数据表示 Tibble 名称,条件用于指定返回逻辑值的表达式。我们将使用在上面示例中创建的学生的 Tibble。
library(tidyverse)
name <- c("surya", "sai", "Nihith", "prakash", "vikas", "mayur")
marks_in_Math <- c(91, 90, 91, 85, 90, 92)
marks_in_Java <- c(91, 91, 92, 91, 89, 93)
Fav_color <- c("Pink", "Red", "Yellow", "Green", "White", "Blue")
students <- tibble(name, marks_in_Math, marks_in_Java, Fav_color)
filter_students =90)
print(filter_students)
输出: 