R 编程中的树熵
据说 R 编程中的熵是对数据中存在的污染物或模糊性的度量。它是通过决策树拆分数据时的决定性成分。未拆分的样本的熵等于 0,而具有等分部分的样本的熵等于 1。选择合适的树时要考虑的两个主要因素是信息增益(IG)和熵。
公式 :

where, p(x) is the probability
例如,考虑需要计算熵的决策树的学校数据集。
| Library available | Coaching joined | Parent’s education | Student’s performance |
|---|---|---|---|
| yes | yes | uneducated | bad |
| yes | no | uneducated | bad |
| no | no | educated | good |
| no | no | uneducated | bad |
因此,可以清楚地看出,学生的表现受三个因素的影响——可用的图书馆、参加的辅导和父母的教育。可以使用这三个变量的信息来构建决策树以预测学生的表现,因此称为预测变量。具有更多信息的变量被认为是决策树的更好拆分器。
所以要计算父节点的熵——学生的表现,使用上面的熵公式,但需要先计算概率。
学生的表现列中有四个值,其中两个表现好,两个表现差。

因此,父母的总熵可以计算如下

使用熵的信息增益
信息增益是一个参数,用于决定可用于在决策树中的每个节点处拆分数据的最佳变量。因此可以计算每个预测变量的 IG,并且具有最高 IG 的变量赢得了根节点分裂的决定因素竞赛。
公式:
Information Gain(IG) = Entropyparent – (weighted average * Entropychildren)
现在要计算加入的预测变量coaching的IG,首先根据这个变量拆分父节点。
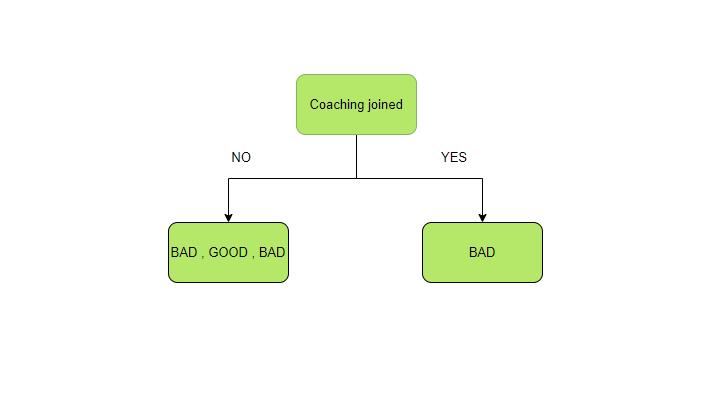
现在有两个部分,首先单独计算它们的熵。
左边部分的熵
有两种类型的输出可用——好的和坏的。在左侧,共有三个结果,两个是坏的,一个是好的。因此, P good和P bad再次计算如下:

右边部分的熵
正确的只有一个组成部分,即性能不佳。因此,概率变为一。熵变为 0,因为输出只能属于一个类别。
用儿童熵计算加权平均值

左子节点有 3 个结果,右子节点有 1 个结果。而熵左节点已计算为 0.9,熵右节点为 0。
现在保留上面公式中的值,我们得到这个例子的加权平均值:

计算 IG
现在将计算出的加权平均值简单地放入 IG 公式中以获得“教练加入”的 IG。
IG(coaching joined) = Entropyparent - (weighted average * Entropychildren)
IG(coaching joined) = 0.811 - 0.675 = 0.136使用相同的步骤和公式计算、比较其他预测变量的 IG,因此选择具有最高 IG 的变量用于在每个节点处拆分数据。