YOLO : You Only Look Once – 实时目标检测
YOLO 由 Joseph Redmond等人提出。 2015 年提出来解决当时物体识别模型面临的问题,Fast R-CNN 是当时最先进的模型之一,但它也有自己的挑战,比如这个网络无法实时使用,因为预测图像需要 2-3 秒,因此无法实时使用。
建筑学:
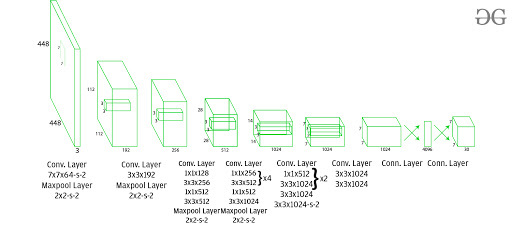
该架构将图像作为输入,并通过保持纵横比相同并执行填充将其大小调整为448*448 。然后这个图像被传递到 CNN 网络中。该模型有24 个卷积层、4 个最大池化层和 2 个全连接层。为了减少层数(通道),我们使用1*1卷积,然后是3*3卷积。请注意,YOLOv1 的最后一层预测一个立方输出。这是通过从最终的全连接层生成(1, 1470)并将其重塑为大小(7, 7, 30)来完成的。
该架构在整个架构中使用 Leaky ReLU 作为其激活函数,除了它使用线性激活函数的层。 Leaky ReLU 的定义可以在这里找到。批量归一化也有助于规范化模型。通过批量标准化,我们可以从模型中移除 dropout 而不会过度拟合。
训练:
该模型在ImageNet-1000数据集上进行训练。该模型经过一周的训练,在 ImageNet 2012 验证中达到了 88%的 top-5 准确率,与当时最先进的模型 GoogLeNet(2014 年 ILSVRC 获胜者)相当。 Fast YOLO 使用更少的层(9 个而不是 24 个)和更少的过滤器。除此之外,快速 YOLO 的所有参数都与 YOLO 相似。YOLO 使用易于优化的平方和误差损失函数。但是,此函数对分类和定位任务给予同等的重视。 YOLO中定义的损失函数如下:

在哪里,  表示对象是否存在于单元格i中。
表示对象是否存在于单元格i中。  表示
表示边界框负责预测单元格i中的对象。
 和
和 是平衡损失函数所需的正则化参数。
是平衡损失函数所需的正则化参数。
在这个模型中,我们取和
 上述损失方程的前两部分表示定位均方误差,而其他三部分表示分类误差。在定位误差中,第一项计算与地面实况边界框的偏差。第二项计算边界框的高度和宽度之差的平方根。在第二项中,我们取宽度和高度的平方根,因为我们的损失函数应该能够根据边界框的大小来考虑偏差。对于小边界框,与大边界框相比,小偏差应该更重要。
上述损失方程的前两部分表示定位均方误差,而其他三部分表示分类误差。在定位误差中,第一项计算与地面实况边界框的偏差。第二项计算边界框的高度和宽度之差的平方根。在第二项中,我们取宽度和高度的平方根,因为我们的损失函数应该能够根据边界框的大小来考虑偏差。对于小边界框,与大边界框相比,小偏差应该更重要。
分类损失中有三个术语,第一个术语计算每个单元格中每个边界框的预测置信度得分与地面实况之间的平方和误差。类似地,第二项计算不包含任何边界框的单元格的均方和,并使用正则化参数使这个损失变小。第三项计算属于这些网格单元的类的平方和误差。
检测:
这种架构将图像划分为S*S大小的网格。如果对象的边界框的中心在那个网格中,那么这个网格负责检测那个对象。每个网格都使用其置信度分数来预测边界框。每个置信度分数都显示了预测的边界包含对象的准确程度以及它预测边界框坐标 wrt 的准确程度。地面实况预测。

YOLO 图片(分为 S*S 网格)
在测试时,我们将条件类概率和单个框置信度预测相乘。我们将置信度分数定义如下:

请注意,当网格中不存在对象时,置信度分数应为0 。如果图像中存在对象,则置信度分数应等于地面实况和预测框之间的 IoU。每个边界框由 5 个预测组成: (x, y, w, h)和置信度得分。 (x, y)坐标表示相对于网格单元边界的框的中心。 h, w坐标表示边界框相对于(x, y)的高度、宽度。置信度分数表示边界框中对象的存在。

YOLO 单格 Bounding box-Box
这导致像这样组合来自每个网格的边界框。

YOLO边界框组合
每个网格还预测 C 条件类概率,P r (Class i | Object)。
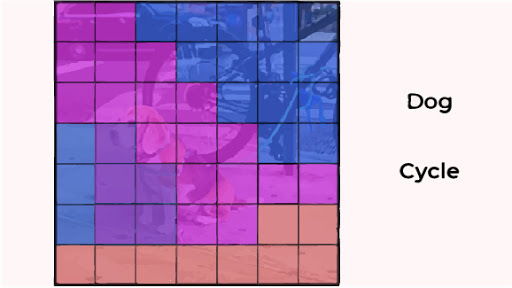
YOLO条件概率图
该概率基于网格单元中对象的存在是有条件的。不管每个网格单元有多少个框,都只能预测一组类别概率。这些预测被编码在大小为 S * S * (5*B +C) 的 3D 张量中。
现在,我们将条件类概率和单个框置信度预测相乘,
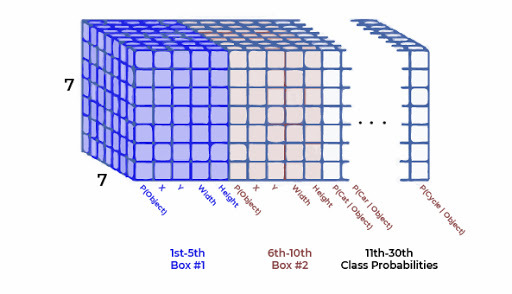
YOLO 输出特征图

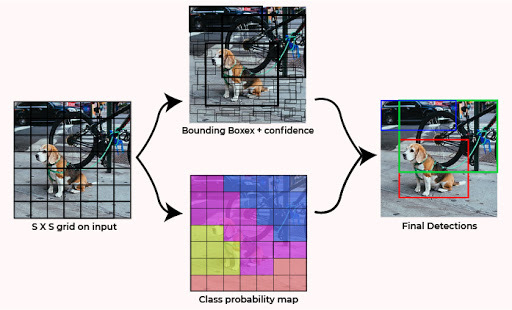
YOLO测试结果
这为我们提供了每个框的特定类别置信度分数。这些分数既编码了该类出现在框中的概率,也编码了预测的框与对象的匹配程度。然后我们应用非最大抑制来预测生成输入的最终结果
YOLO 在测试时非常快,因为它仅使用单个 CNN 架构来预测结果,并且以将分类视为回归问题的方式定义类。
结果:
在 VOC 2007 和 2012 上训练时,简单 YOLO 的 mAP 为63.4% ,结果生成速度快近3 倍的 Fast YOLO 的 mAP 为 52%。这低于获得的最佳 Fast R-CNN 模型(71% mAP)和 R-CNN 获得的(66% mAP) 。但是,它在准确度上击败了其他实时检测器,例如(DPMv5 33% mAP) 。
YOLO 的好处:
- 以45 fps (较大的网络)到150 fps (较小的网络)的速率处理帧,这比实时更好。
- 网络能够更好地概括图像。
YOLO的缺点:
- 与 Faster R_CNN 相比,召回率相对较低且定位错误较多。
- 难以检测靠近的物体,因为每个网格只能提出 2 个边界框。
- 努力检测小物体。