链表与数组
数组将元素存储在连续的内存位置,从而为存储的元素提供易于计算的地址,这允许更快地访问特定索引处的元素。链表的存储结构不那么严格,元素通常不存储在连续的位置,因此它们需要与提供下一个元素的引用的附加标签一起存储。数据存储方案的这种差异决定了哪种数据结构更适合给定情况。
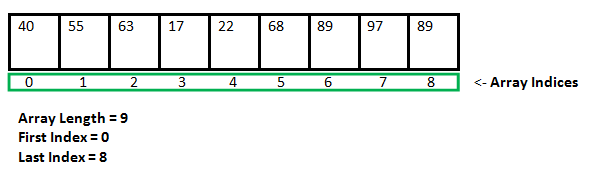
数组的数据存储方案
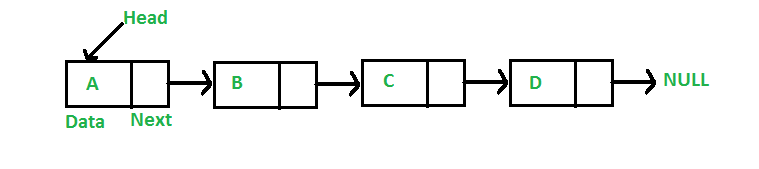
链表的数据存储方案
主要区别如下:
- 大小:由于数据只能存储在数组中的连续内存块中,由于存在覆盖其他数据的风险,因此无法在运行时更改其大小。然而,在链表中,每个节点都指向下一个节点,这样数据就可以存在于分散的(不连续的)地址中;这允许可以在运行时更改的动态大小。
- 内存分配:用于编译时的数组和运行时的链表。但是,动态分配的数组也在运行时分配内存。
- 内存效率:对于相同数量的元素,链表使用更多的内存作为对下一个节点的引用也与数据一起存储。但是,链表的大小灵活性可能会使它们总体上使用更少的内存;当大小不确定或数据元素的大小变化很大时,这很有用;在使用数组时,必须分配相当于大小上限的内存(即使不是全部都被使用),而链表可以根据数据量逐步增加它们的大小。
- 执行时间:数组中的任何元素都可以通过其索引直接访问;然而,在链表的情况下,必须遍历所有先前的元素才能到达任何元素。此外,数组中更好的缓存位置(由于连续内存分配)可以显着提高性能。因此,某些操作(例如修改某个元素)在数组中速度更快,而其他一些操作(例如在数据中插入/删除元素)在链表中速度更快。
以下是支持链表的要点。
(1)数组的大小是固定的:所以我们必须提前知道元素数量的上限。另外,一般来说,分配的内存与使用量无关,都等于上限,在实际使用中,很少达到上限。
(2) 在元素数组中插入一个新元素是昂贵的,因为必须为新元素创建一个房间,并且必须移动现有元素才能创建房间。
例如,假设我们在一个数组 id[] 中维护一个排序的 ID 列表。
id[] = [1000, 1010, 1050, 2000, 2040, .....]。
而如果我们要插入一个新的ID 1005,那么为了保持排序顺序,我们必须将1000之后的所有元素(不包括1000)移动。
除非使用某些特殊技术,否则删除数组的代价也很高。例如,要删除 id[] 中的 1010,必须移动 1010 之后的所有内容。
所以链表相比数组有以下两个优点
1) 动态尺寸
2) 易于插入/删除
链表有以下缺点:
1) 不允许随机访问。我们必须从第一个节点开始按顺序访问元素。所以我们不能对链表进行二分查找。
2) 列表的每个元素都需要额外的指针存储空间。
3) 数组具有更好的缓存局部性,可以在性能上产生相当大的差异。
参考:
http://cslibrary.stanford.edu/103/LinkedListBasics.pdf
如果您希望与专家一起参加现场课程,请参阅DSA 现场工作专业课程和学生竞争性编程现场课程。