使用 Melt 和 Unmelt 重塑 Pandas 数据帧
Pandas 是一个用Python语言编写的开源、BSD 许可的库。 Pandas 提供高性能、快速、易于使用的数据结构和数据分析工具,用于处理数值数据和时间序列。 Pandas 建立在 Numpy 库之上,使用Python、Cython 和 C 等语言编写。2008 年,Wes McKinney 开发了 Pandas 库。在 Pandas 中,我们可以从各种文件格式(如 JSON、SQL、Microsoft Excel 等)导入数据。数据帧功能用于加载和操作数据。
有时我们需要重塑 Pandas 数据框以更好地进行分析。重塑在数据分析中起着至关重要的作用。 Pandas 提供了像melt和unmelt这样的函数来重塑。
Pandas.melt()
melt()用于将宽数据帧转换为更长的形式。当需要将特定列视为标识符时,可以使用此函数。
Syntax: pandas.melt(frame, id_vars=None, value_vars=None, var_name=None, value_name=’value’, col_level=None)
示例 1:
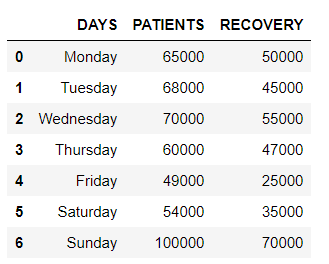
使用有关“天”、“患者”和“恢复”的数据初始化数据框。
Python3
# importing pandas library
import pandas as pd
# creating and initializing a list
values = [['Monday', 65000, 50000],
['Tuesday', 68000, 45000],
['Wednesday', 70000, 55000],
['Thursday', 60000, 47000],
['Friday', 49000, 25000],
['Saturday', 54000, 35000],
['Sunday', 100000, 70000]]
# creating a pandas dataframe
df = pd.DataFrame(values, columns=['DAYS', 'PATIENTS', 'RECOVERY'])
# displaying the data frame
dfPython3
# melting with DAYS as column identifier
reshaped_df = df.melt(id_vars=['DAYS'])
# displaying the reshaped data frame
reshaped_dfPython3
# importing pandas library
import pandas as pd
# creating and initializing a dataframe
values = [['Monday', 65000, 50000, 1500],
['Tuesday', 68000, 45000, 7250],
['Wednesday', 70000, 55000, 1400],
['Thursday', 60000, 47000, 4200],
['Friday', 49000, 25000, 3000],
['Saturday', 54000, 35000, 2000],
['Sunday', 100000, 70000, 4550]]
# creating a pandas dataframe
df = pd.DataFrame(values,
columns=['DAYS', 'PATIENTS', 'RECOVERY', 'DEATHS'])
# displaying the data frame
dfPython3
# reshaping data frame
# using pandas.melt()
reshaped_df = df.melt(id_vars=['PATIENTS'])
# displaying the reshaped data frame
reshaped_dfPython3
# importing pandas library
import pandas as pd
# creating and initializing a list
values = [[101, 'Rohan', 455, 'Football'],
[111, 'Elvish', 250, 'Chess'],
[192, 'Deepak', 495, 'Cricket'],
[201, 'Sai', 400, 'Ludo'],
[105, 'Radha', 350, 'Badminton'],
[118, 'Vansh', 450, 'Badminton']]
# creating a pandas dataframe
df = pd.DataFrame(values,
columns=['ID', 'Name', 'Marks', 'Sports'])
# displaying the data frame
dfPython3
# unmelting
reshaped_df = df.pivot(index='Name', columns='Sports')
# displaying the reshaped data frame
reshaped_dfPython3
reshaped_df = df.pivot('ID', 'Marks', 'Sports')
# displaying the reshaped data frame
reshaped_dfPython3
reshaped_df = df.pivot('ID', 'Marks', 'Sports')
# reseting index
df_new = reshaped_df.reset_index()
# displaying the reshaped data frame
df_new输出:
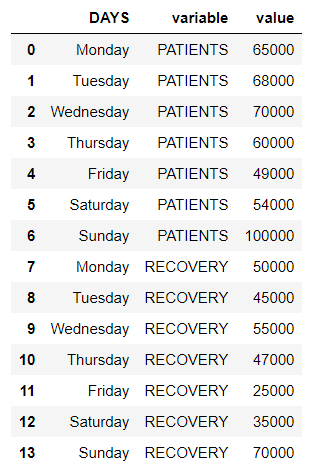
现在,我们使用pandas.melt()围绕“DAYS ”列重塑数据框。
蟒蛇3
# melting with DAYS as column identifier
reshaped_df = df.melt(id_vars=['DAYS'])
# displaying the reshaped data frame
reshaped_df
输出:
示例 2:
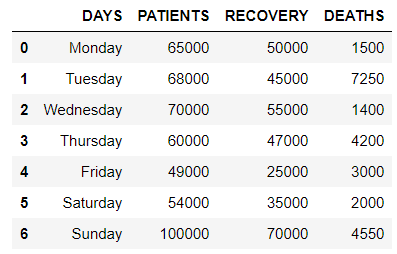
现在,对于上面使用的数据框,引入了一个名为“ Deaths ”的新列。
蟒蛇3
# importing pandas library
import pandas as pd
# creating and initializing a dataframe
values = [['Monday', 65000, 50000, 1500],
['Tuesday', 68000, 45000, 7250],
['Wednesday', 70000, 55000, 1400],
['Thursday', 60000, 47000, 4200],
['Friday', 49000, 25000, 3000],
['Saturday', 54000, 35000, 2000],
['Sunday', 100000, 70000, 4550]]
# creating a pandas dataframe
df = pd.DataFrame(values,
columns=['DAYS', 'PATIENTS', 'RECOVERY', 'DEATHS'])
# displaying the data frame
df
输出:
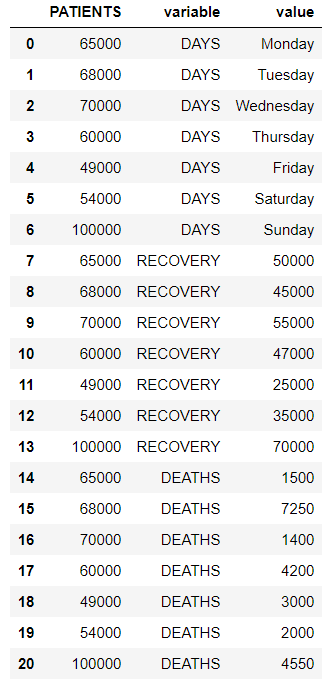
我们在“患者”列周围使用pandas.melt()重塑了数据框。
蟒蛇3
# reshaping data frame
# using pandas.melt()
reshaped_df = df.melt(id_vars=['PATIENTS'])
# displaying the reshaped data frame
reshaped_df
输出:
Pandas.pivot()/ unmelt函数
Pivoting、Unmelting 或 Reverse Melting用于将具有多个值的列转换为它们自己的多个列。
Syntax : DataFrame.pivot(index=None, columns=None, values=None)
示例 1:
创建一个包含 6 名学生的 ID、姓名、分数和体育数据的数据框。
蟒蛇3
# importing pandas library
import pandas as pd
# creating and initializing a list
values = [[101, 'Rohan', 455, 'Football'],
[111, 'Elvish', 250, 'Chess'],
[192, 'Deepak', 495, 'Cricket'],
[201, 'Sai', 400, 'Ludo'],
[105, 'Radha', 350, 'Badminton'],
[118, 'Vansh', 450, 'Badminton']]
# creating a pandas dataframe
df = pd.DataFrame(values,
columns=['ID', 'Name', 'Marks', 'Sports'])
# displaying the data frame
df
输出:

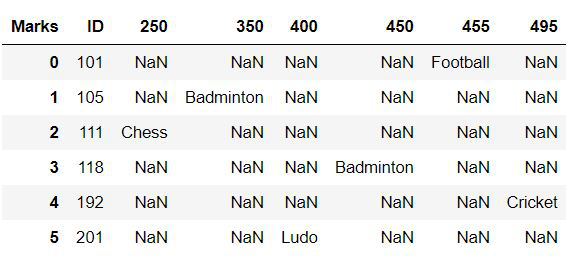
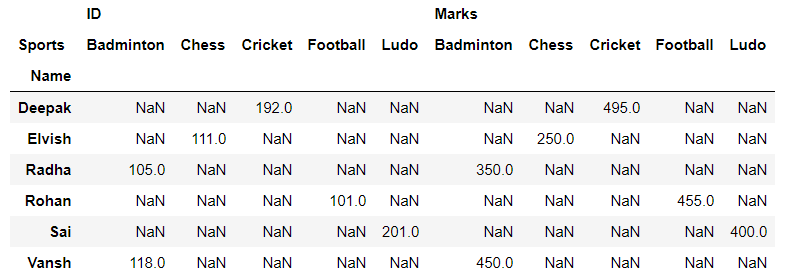
围绕专栏体育解开:
蟒蛇3
# unmelting
reshaped_df = df.pivot(index='Name', columns='Sports')
# displaying the reshaped data frame
reshaped_df
输出:
示例 2:
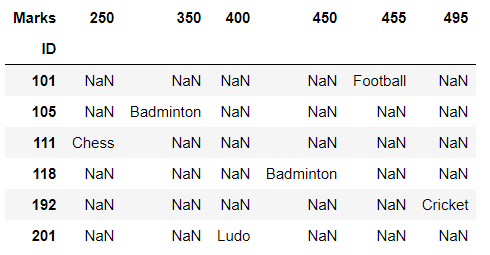
考虑上面示例中使用的相同数据帧。也可以基于多于一根柱子进行解熔。
蟒蛇3
reshaped_df = df.pivot('ID', 'Marks', 'Sports')
# displaying the reshaped data frame
reshaped_df
输出:
但在索引方面,重构后的数据框与原始数据框几乎没有什么不同。要将索引也设置为原始数据帧,请在重塑的数据帧上使用reset_index()函数。
蟒蛇3
reshaped_df = df.pivot('ID', 'Marks', 'Sports')
# reseting index
df_new = reshaped_df.reset_index()
# displaying the reshaped data frame
df_new
输出: