使用 stack、unstack 和 melt 方法重塑 pandas DataFrame
Pandas 使用各种方法来重塑数据框和系列。让我们看看一些重塑方法。
我们先导入一个数据框。
# import pandas module
import pandas as pd
# making dataframe
df = pd.read_csv("https://media.geeksforgeeks.org/wp-content/uploads/nba.csv")
# it was print the first 5-rows
print(df.head())
输出: 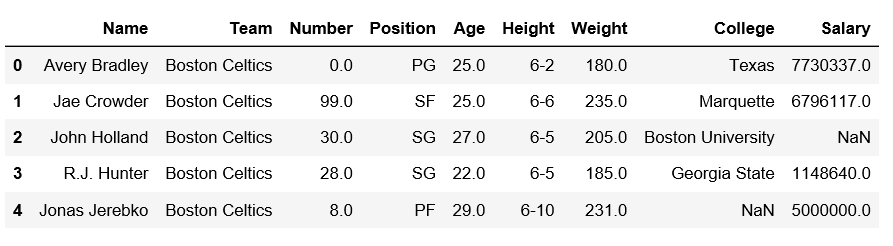
使用 stack() 方法:
Stack 方法与 DataFrame 中的 MultiIndex 对象一起使用,它返回一个 DataFrame,其索引具有新的最内层行标签。它将宽表更改为长表。
# import pandas module
import pandas as pd
# making dataframe
df = pd.read_csv("nba.csv")
# reshape the dataframe using stack() method
df_stacked = df.stack()
print(df_stacked.head(26))
输出:  使用 unstack() 方法:
使用 unstack() 方法:
unstack类似于 stack 方法,它也适用于数据帧中的多索引对象,产生一个具有新的最内层列标签的重塑数据帧。
# import pandas module
import pandas as pd
# making dataframe
df = pd.read_csv("nba.csv")
# unstack() method
df_unstacked = df_stacked.unstack()
print(df_unstacked.head(10))
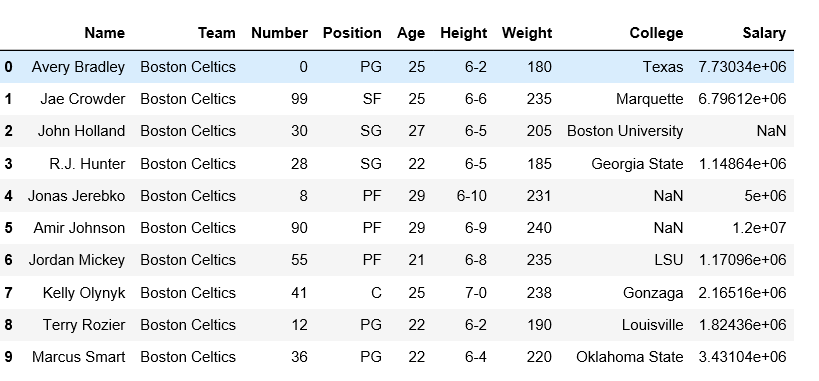
使用melt()方法:
在 pandas 中融化将数据帧从宽格式重塑为长格式。它使用“id_vars['col_names']”按列名融化数据框。
# import pandas module
import pandas as pd
# making dataframe
df = pd.read_csv("nba.csv")
# it takes two columns "Name" and "Team"
df_melt = df.melt(id_vars =['Name', 'Team'])
print(df_melt.head(10))
输出: 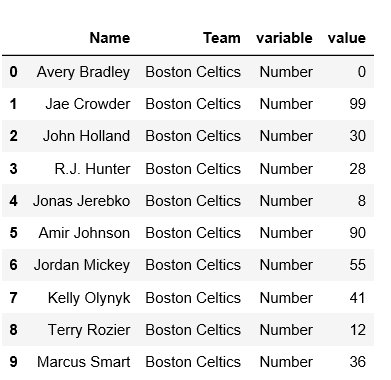
在评论中写代码?请使用 ide.geeksforgeeks.org,生成链接并在此处分享链接。