机器学习中的决策阈值
什么是决策阈值?
sklearn 不允许我们直接设置决策阈值,但它让我们可以访问决策分数 (决策函数o/p )用于进行预测。我们可以从决策函数输出中选择最好的分数并将其设置为决策阈值,并将所有小于此决策阈值的决策评分值视为负类(0),所有大于此决策的决策评分值阈值作为正类 (1)。
使用各种决策阈值的Precision-Recall曲线,我们可以根据我们的项目是否面向精度来选择决策阈值的最佳值,使其具有High Precision (不影响Recall much)或High Recall (不影响Precision much)或分别面向召回。
这样做的主要目的是根据我们的 ML 项目分别是面向精度还是面向召回,得到一个高精度的 ML 模型或高召回率的 ML 模型。
代码:用于构建高精度 ML 模型的Python代码
# Import required modules.
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import classification_report, recall_score, precision_score, accuracy_score
# Get the data.
data_set = datasets.load_breast_cancer()
# Get the data into an array form.
x = data_set.data # Input feature x.
y = data_set.target # Input target variable y.
# Get the names of the features.
feature_list = data_set.feature_names
# Convert the data into pandas data frame.
data_frame = pd.DataFrame(x, columns = feature_list)
# To insert an output column in data_frame.
data_frame.insert(30, 'Outcome', y) # Run this line only once for every new training.
# Data Frame.
data_frame.head(7)
输出: 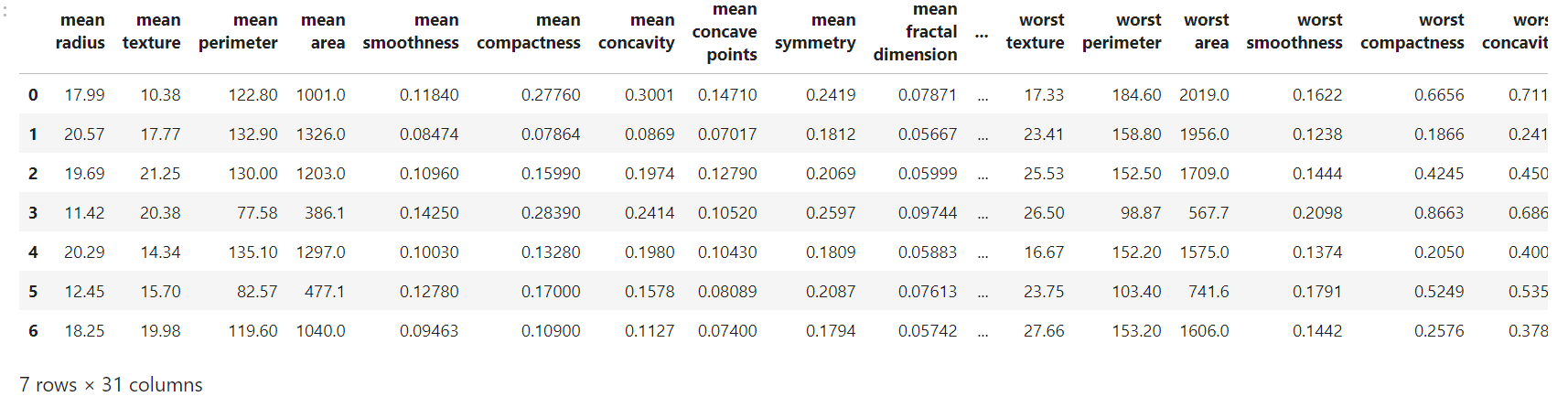
代码:训练模型
# Train Test Split.
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2, random_state = 42)
# Create Classifier Object.
clf = SVC()
clf.fit(x_train, y_train)
# Use decision_function method.
decision_function = clf.decision_function(x_test)
获得的实际分数:
# Actual obtained results without any manual setting of Decision Threshold.
predict_actual = clf.predict(x_test) # Predict using classifier.
accuracy_actual = clf.score(x_test, y_test)
classification_report_actual = classification_report(y_test, predict_actual)
print(predict_actual, accuracy_actual, classification_report_actual, sep ='\n')
输出: 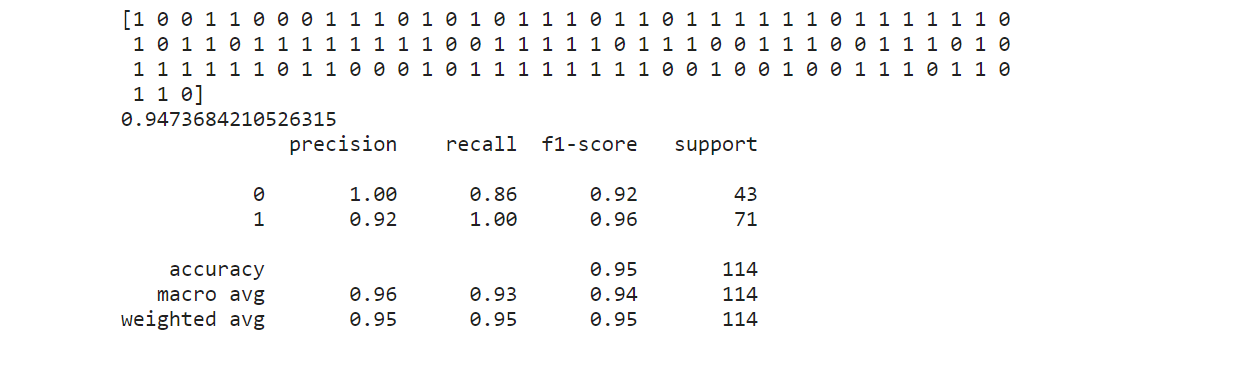
在上面的分类报告中,我们可以看到(1)的模型精度值为 0.92,(1)的召回值为 1.00。由于我们在本文中的目标是在不影响 Recall 的情况下,在预测 (1) 中建立一个高精度 ML 模型,因此我们需要从下面的 Precision-Recall 曲线中手动选择决策阈值的最佳值,这样我们就可以增加这个模型的精度。
代码:
# Plot Precision-Recall curve using sklearn.
from sklearn.metrics import precision_recall_curve
precision, recall, threshold = precision_recall_curve(y_test, decision_function)
# Plot the output.
plt.plot(threshold, precision[:-1], c ='r', label ='PRECISION')
plt.plot(threshold, recall[:-1], c ='b', label ='RECALL')
plt.grid()
plt.legend()
plt.title('Precision-Recall Curve')
输出:

在上图中,我们可以看到,如果我们想要高精度值,那么我们需要增加决策阈值(x 轴)的值,但这会降低召回值(这是不利的)。所以我们需要选择决策阈值的值,它会增加精确度但不会降低召回率。上图中的一个这样的值大约是 0.6 决策阈值。
代码:
# Implementing main logic.
# Based on analysis of the Precision-Recall curve.
# Let Decision Threshold value be around 0.6... to get high Precision without affecting recall much.
# Desired results.
# Decision Function output for x_test.
df = clf.decision_function(x_test)
# Set the value of decision threshold.
decision_teshold = 0.5914643767268305
# Desired prediction to increase precision value.
desired_predict =[]
# Iterate through each value of decision function output
# and if decision score is > than Decision threshold then,
# append (1) to the empty list ( desired_prediction) else
# append (0).
for i in df:
if i代码:新旧精度值之间的比较。
# Comparison
# Old Precision Value
print("old precision value:", precision_score(y_test, predict_actual))
# New precision Value
print("new precision value:", precision_score(y_test, desired_predict))
输出:
old precision value: 0.922077922077922
new precision value: 0.9714285714285714
观察:
- 精度值从 0.92 增加到 0.97。
- 由于精确召回权衡,召回的价值有所下降。
笔记:
上面的代码没有经过数据预处理(Data Cleaned 或 Feature Engineered),这会使本文冗长。这只是一个如何在实践中使用决策阈值的想法。