Pandas – 数据帧上的 Groupby 值计数
先决条件:熊猫
可以使用Pandas来分别计算数据帧中每个值的频率。让我们看看如何对 Pandas 数据框进行 Groupby 值计数。要计算 pandas 数据框中的 Groupby 值,我们将使用 groupby() size() 和 unstack() 方法。
使用的功能:
- groupby(): groupby()函数用于根据某些条件将数据分组。 Pandas 对象可以在它们的任何轴上拆分。分组的抽象定义是提供标签到组名的映射
Syntax:
DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False, **kwargs)
Parameters :
- by : mapping, function, str, or iterable
- axis : int, default 0
- level : If the axis is a MultiIndex (hierarchical), group by a particular level or levels
- as_index : For aggregated output, return object with group labels as the index. Only relevant for DataFrame input. as_index=False is effectively “SQL-style” grouped output
- sort : Sort group keys. Get better performance by turning this off. Note this does not influence the order of observations within each group. groupby preserves the order of rows within each group.
- group_keys : When calling apply, add group keys to index to identify pieces
- squeeze : Reduce the dimensionality of the return type if possible, otherwise return a consistent type
Returns : GroupBy object
- size(): size 方法用于获取表示对象中元素数量的整数。如果是 DataFrame,size 方法是返回行数乘以列数。
Syntax:
Dataframe.size()
- unstack(): unstack 方法与 DataFrame 中的 MultiIndex 对象一起使用,生成一个带有新的最内层列标签的重塑 DataFrame。
Syntax:
Dataframe.unstack()
方法
- 导入模块
- 创建或加载数据
- 创建数据框
- 计算每个值出现的次数
- 打印结果数据框
示例 1:
Python
# import pandas
import pandas as pd
# create dataframe
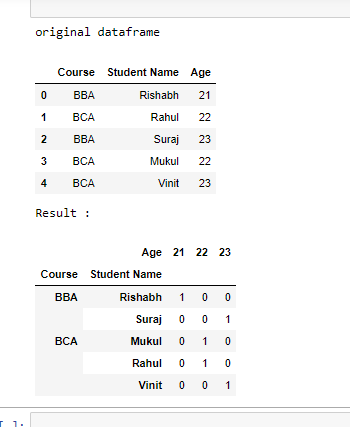
df = pd.DataFrame({
'Course': ['BBA', 'BCA', 'BBA', 'BCA', 'BCA'],
'Student Name': ['Rishabh', 'Rahul', 'Suraj', 'Mukul', 'Vinit'],
'Age': [21, 22, 23, 22, 23]})
# print original dataframe
print("original dataframe")
display(df)
# counts Groupby value
df = df.groupby(['Course', 'Student Name', 'Age']).size().unstack(fill_value=0)
# print dataframe
print("Result :")
display(df)Python
# import pandas
import pandas as pd
# create dataframe
df = pd.DataFrame({
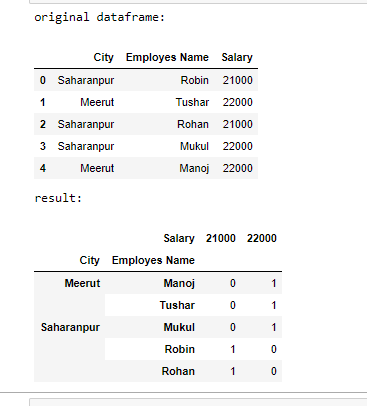
'City': ['Saharanpur', 'Meerut', 'Saharanpur', 'Saharanpur', 'Meerut'],
'Employes Name': ['Robin', 'Tushar', 'Rohan', 'Mukul', 'Manoj'],
'Salary': [21000, 22000, 21000, 22000, 22000]})
# print original dataframe
print("original dataframe: ")
display(df)
# counts Groupby value
df = df.groupby(['City', 'Employes Name', 'Salary']
).size().unstack(fill_value=0)
# print dataframe
print("result: ")
display(df)输出:
示例 2:
Python
# import pandas
import pandas as pd
# create dataframe
df = pd.DataFrame({
'City': ['Saharanpur', 'Meerut', 'Saharanpur', 'Saharanpur', 'Meerut'],
'Employes Name': ['Robin', 'Tushar', 'Rohan', 'Mukul', 'Manoj'],
'Salary': [21000, 22000, 21000, 22000, 22000]})
# print original dataframe
print("original dataframe: ")
display(df)
# counts Groupby value
df = df.groupby(['City', 'Employes Name', 'Salary']
).size().unstack(fill_value=0)
# print dataframe
print("result: ")
display(df)
输出: