Pandas GroupBy
Groupby 是一个非常简单的概念。我们可以创建一组类别并将函数应用于类别。这是一个简单的概念,但它是一种在数据科学中广泛使用的非常有价值的技术。在真正的数据科学项目中,您将处理大量数据并一遍又一遍地尝试,因此为了提高效率,我们使用 Groupby 概念。 Groupby 概念非常重要,因为它能够有效地聚合数据,无论是性能还是代码量都非常出色。 Groupby主要是指一个过程,涉及到以下一个或多个步骤,它们是:
- 拆分:这是我们通过在数据集上应用一些条件将数据拆分为组的过程。
- Applying :这是一个我们将函数独立应用于每个组的过程
- 组合:这是我们在应用 groupby 和结果后将不同的数据集组合成数据结构的过程
下图将有助于理解 Groupby 概念中涉及的过程。
1. 对 Team 列中的唯一值进行分组
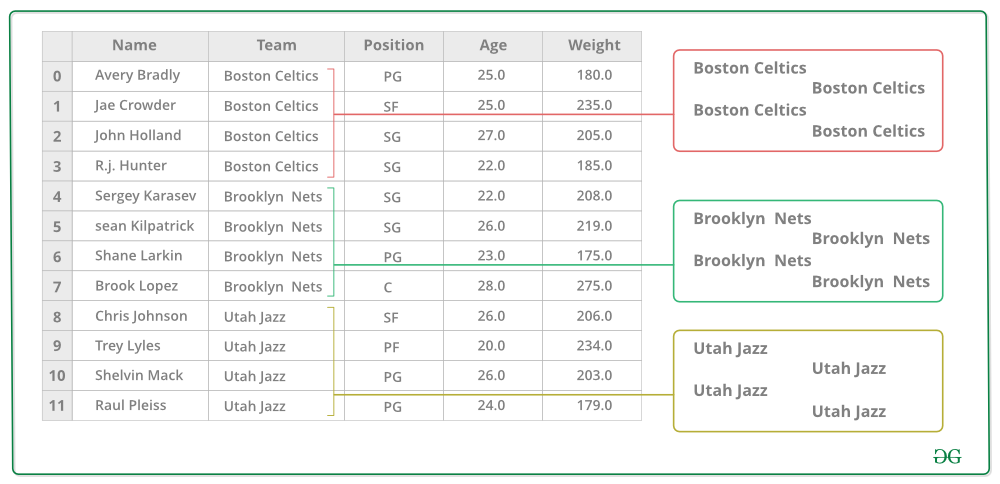
2. 现在每组都有一个桶
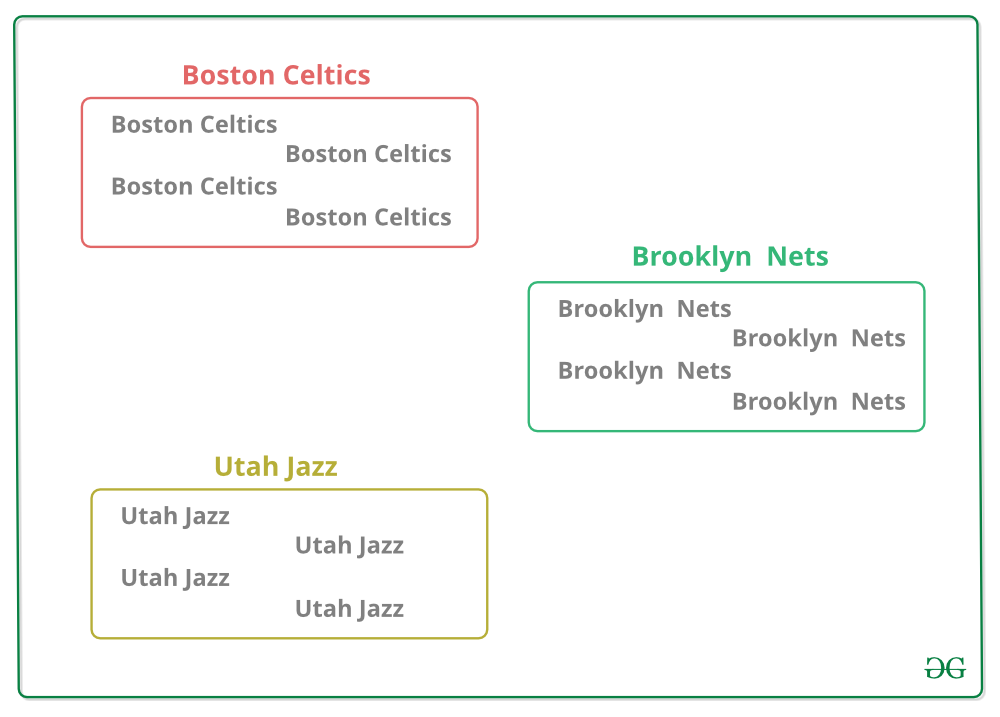
3. 将其他数据扔进桶中
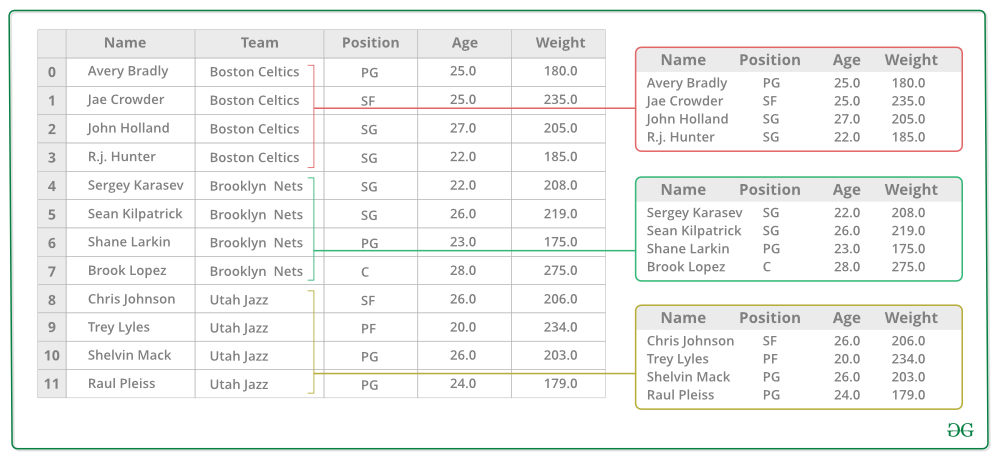
4. 对每个桶的权重列应用一个函数。

将数据分成组
拆分是我们通过对数据集应用某些条件将数据拆分为一组的过程。为了拆分数据,我们对数据集应用某些条件。为了分割数据,我们使用 groupby()函数,该函数用于根据某些标准将数据分组。 Pandas 对象可以在它们的任何轴上拆分。分组的抽象定义是提供标签到组名的映射。 Pandas 数据集可以拆分为任何对象。有多种方法可以拆分数据,例如:
- obj.groupby(键)
- obj.groupby(键,轴 = 1)
- obj.groupby([key1, key2])
注意:在此我们将分组对象称为键。
一键分组数据:
为了用一个键对数据进行分组,我们在 groupby函数中只传递一个键作为参数。
Python3
# importing pandas module
import pandas as pd
# Define a dictionary containing employee data
data1 = {'Name':['Jai', 'Anuj', 'Jai', 'Princi',
'Gaurav', 'Anuj', 'Princi', 'Abhi'],
'Age':[27, 24, 22, 32,
33, 36, 27, 32],
'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj',
'Jaunpur', 'Kanpur', 'Allahabad', 'Aligarh'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd',
'B.Tech', 'B.com', 'Msc', 'MA']}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data1)
print(df)Python3
# using groupby function
# with one key
df.groupby('Name')
print(df.groupby('Name').groups)Python3
# applying groupby() function to
# group the data on Name value.
gk = df.groupby('Name')
# Let's print the first entries
# in all the groups formed.
gk.first()Python3
# importing pandas module
import pandas as pd
# Define a dictionary containing employee data
data1 = {'Name':['Jai', 'Anuj', 'Jai', 'Princi',
'Gaurav', 'Anuj', 'Princi', 'Abhi'],
'Age':[27, 24, 22, 32,
33, 36, 27, 32],
'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj',
'Jaunpur', 'Kanpur', 'Allahabad', 'Aligarh'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd',
'B.Tech', 'B.com', 'Msc', 'MA']}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data1)
print(df)Python3
# Using multiple keys in
# groupby() function
df.groupby(['Name', 'Qualification'])
print(df.groupby(['Name', 'Qualification']).groups)Python3
# importing pandas module
import pandas as pd
# Define a dictionary containing employee data
data1 = {'Name':['Jai', 'Anuj', 'Jai', 'Princi',
'Gaurav', 'Anuj', 'Princi', 'Abhi'],
'Age':[27, 24, 22, 32,
33, 36, 27, 32], }
# Convert the dictionary into DataFrame
df = pd.DataFrame(data1)
print(df)Python3
# using groupby function
# without using sort
df.groupby(['Name']).sum()Python3
# using groupby function
# with sort
df.groupby(['Name'], sort = False).sum()Python3
# importing pandas module
import pandas as pd
# Define a dictionary containing employee data
data1 = {'Name':['Jai', 'Anuj', 'Jai', 'Princi',
'Gaurav', 'Anuj', 'Princi', 'Abhi'],
'Age':[27, 24, 22, 32,
33, 36, 27, 32],
'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj',
'Jaunpur', 'Kanpur', 'Allahabad', 'Aligarh'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd',
'B.Tech', 'B.com', 'Msc', 'MA']}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data1)
print(df)Python3
# using keys for grouping
# data
df.groupby('Name').groupsPython3
# importing pandas module
import pandas as pd
# Define a dictionary containing employee data
data1 = {'Name':['Jai', 'Anuj', 'Jai', 'Princi',
'Gaurav', 'Anuj', 'Princi', 'Abhi'],
'Age':[27, 24, 22, 32,
33, 36, 27, 32],
'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj',
'Jaunpur', 'Kanpur', 'Allahabad', 'Aligarh'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd',
'B.Tech', 'B.com', 'Msc', 'MA']}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data1)
print(df)Python3
# iterating an element
# of group
grp = df.groupby('Name')
for name, group in grp:
print(name)
print(group)
print()Python3
# iterating an element
# of group containing
# multiple keys
grp = df.groupby(['Name', 'Qualification'])
for name, group in grp:
print(name)
print(group)
print()Python3
# importing pandas module
import pandas as pd
# Define a dictionary containing employee data
data1 = {'Name':['Jai', 'Anuj', 'Jai', 'Princi',
'Gaurav', 'Anuj', 'Princi', 'Abhi'],
'Age':[27, 24, 22, 32,
33, 36, 27, 32],
'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj',
'Jaunpur', 'Kanpur', 'Allahabad', 'Aligarh'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd',
'B.Tech', 'B.com', 'Msc', 'MA']}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data1)
print(df)Python3
# selecting a single group
grp = df.groupby('Name')
grp.get_group('Jai')Python3
# selecting object grouped
# on multiple columns
grp = df.groupby(['Name', 'Qualification'])
grp.get_group(('Jai', 'Msc'))Python3
# importing pandas module
import pandas as pd
# importing numpy as np
import numpy as np
# Define a dictionary containing employee data
data1 = {'Name':['Jai', 'Anuj', 'Jai', 'Princi',
'Gaurav', 'Anuj', 'Princi', 'Abhi'],
'Age':[27, 24, 22, 32,
33, 36, 27, 32],
'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj',
'Jaunpur', 'Kanpur', 'Allahabad', 'Aligarh'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd',
'B.Tech', 'B.com', 'Msc', 'MA']}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data1)
print(df)Python3
# performing aggregation using
# aggregate method
grp1 = df.groupby('Name')
grp1.aggregate(np.sum)Python3
# performing aggregation on
# group containing multiple
# keys
grp1 = df.groupby(['Name', 'Qualification'])
grp1.aggregate(np.sum)Python3
# importing pandas module
import pandas as pd
# importing numpy as np
import numpy as np
# Define a dictionary containing employee data
data1 = {'Name':['Jai', 'Anuj', 'Jai', 'Princi',
'Gaurav', 'Anuj', 'Princi', 'Abhi'],
'Age':[27, 24, 22, 32,
33, 36, 27, 32],
'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj',
'Jaunpur', 'Kanpur', 'Allahabad', 'Aligarh'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd',
'B.Tech', 'B.com', 'Msc', 'MA']}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data1)
print(df)Python3
# applying a function by passing
# a list of functions
grp = df.groupby('Name')
grp['Age'].agg([np.sum, np.mean, np.std])Python3
# importing pandas module
import pandas as pd
# importing numpy as np
import numpy as np
# Define a dictionary containing employee data
data1 = {'Name':['Jai', 'Anuj', 'Jai', 'Princi',
'Gaurav', 'Anuj', 'Princi', 'Abhi'],
'Age':[27, 24, 22, 32,
33, 36, 27, 32],
'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj',
'Jaunpur', 'Kanpur', 'Allahabad', 'Aligarh'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd',
'B.Tech', 'B.com', 'Msc', 'MA'],
'Score': [23, 34, 35, 45, 47, 50, 52, 53]}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data1)
print(df)Python3
# using different aggregation
# function by passing dictionary
# to aggregate
grp = df.groupby('Name')
grp.agg({'Age' : 'sum', 'Score' : 'std'})Python3
# importing pandas module
import pandas as pd
# importing numpy as np
import numpy as np
# Define a dictionary containing employee data
data1 = {'Name':['Jai', 'Anuj', 'Jai', 'Princi',
'Gaurav', 'Anuj', 'Princi', 'Abhi'],
'Age':[27, 24, 22, 32,
33, 36, 27, 32],
'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj',
'Jaunpur', 'Kanpur', 'Allahabad', 'Aligarh'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd',
'B.Tech', 'B.com', 'Msc', 'MA'],
'Score': [23, 34, 35, 45, 47, 50, 52, 53]}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data1)
print(df)Python3
# using transform function
grp = df.groupby('Name')
sc = lambda x: (x - x.mean()) / x.std()*10
grp.transform(sc)Python3
# importing pandas module
import pandas as pd
# importing numpy as np
import numpy as np
# Define a dictionary containing employee data
data1 = {'Name':['Jai', 'Anuj', 'Jai', 'Princi',
'Gaurav', 'Anuj', 'Princi', 'Abhi'],
'Age':[27, 24, 22, 32,
33, 36, 27, 32],
'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj',
'Jaunpur', 'Kanpur', 'Allahabad', 'Aligarh'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd',
'B.Tech', 'B.com', 'Msc', 'MA'],
'Score': [23, 34, 35, 45, 47, 50, 52, 53]}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data1)
print(df)Python3
# filtering data using
# filter data
grp = df.groupby('Name')
grp.filter(lambda x: len(x) >= 2)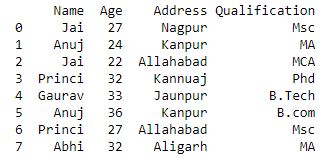
现在我们使用 groupby()函数对 Name 的数据进行分组。
Python3
# using groupby function
# with one key
df.groupby('Name')
print(df.groupby('Name').groups)
输出 :

现在我们打印所有形成的组中的第一个条目。
Python3
# applying groupby() function to
# group the data on Name value.
gk = df.groupby('Name')
# Let's print the first entries
# in all the groups formed.
gk.first()
输出 :

使用多个键对数据进行分组:
为了用多个键对数据进行分组,我们在 groupby函数中传递了多个键。
Python3
# importing pandas module
import pandas as pd
# Define a dictionary containing employee data
data1 = {'Name':['Jai', 'Anuj', 'Jai', 'Princi',
'Gaurav', 'Anuj', 'Princi', 'Abhi'],
'Age':[27, 24, 22, 32,
33, 36, 27, 32],
'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj',
'Jaunpur', 'Kanpur', 'Allahabad', 'Aligarh'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd',
'B.Tech', 'B.com', 'Msc', 'MA']}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data1)
print(df)

现在我们使用 groupby函数中的多个键将“姓名”和“资格”的数据组合在一起。
Python3
# Using multiple keys in
# groupby() function
df.groupby(['Name', 'Qualification'])
print(df.groupby(['Name', 'Qualification']).groups)
输出 :

通过排序键对数据进行分组:
组键默认使用 groupby 操作进行排序。用户可以传递 sort=False 以获得潜在的加速。
Python3
# importing pandas module
import pandas as pd
# Define a dictionary containing employee data
data1 = {'Name':['Jai', 'Anuj', 'Jai', 'Princi',
'Gaurav', 'Anuj', 'Princi', 'Abhi'],
'Age':[27, 24, 22, 32,
33, 36, 27, 32], }
# Convert the dictionary into DataFrame
df = pd.DataFrame(data1)
print(df)
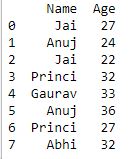
现在我们应用 groupby() 而不进行排序
Python3
# using groupby function
# without using sort
df.groupby(['Name']).sum()
输出 :

现在我们使用 sort 应用 groupby() 以获得潜在的加速
Python3
# using groupby function
# with sort
df.groupby(['Name'], sort = False).sum()
输出 :
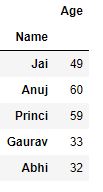
使用对象属性对数据进行分组:
Groups 属性就像字典,其键是计算的唯一组,对应的值是属于每个组的轴标签。
Python3
# importing pandas module
import pandas as pd
# Define a dictionary containing employee data
data1 = {'Name':['Jai', 'Anuj', 'Jai', 'Princi',
'Gaurav', 'Anuj', 'Princi', 'Abhi'],
'Age':[27, 24, 22, 32,
33, 36, 27, 32],
'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj',
'Jaunpur', 'Kanpur', 'Allahabad', 'Aligarh'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd',
'B.Tech', 'B.com', 'Msc', 'MA']}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data1)
print(df)
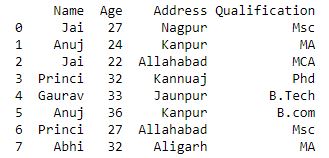
现在我们像在字典中一样使用键对数据进行分组。
Python3
# using keys for grouping
# data
df.groupby('Name').groups
输出 :

遍历组
为了迭代组元素,我们可以迭代类似于 itertools.obj 的对象。
Python3
# importing pandas module
import pandas as pd
# Define a dictionary containing employee data
data1 = {'Name':['Jai', 'Anuj', 'Jai', 'Princi',
'Gaurav', 'Anuj', 'Princi', 'Abhi'],
'Age':[27, 24, 22, 32,
33, 36, 27, 32],
'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj',
'Jaunpur', 'Kanpur', 'Allahabad', 'Aligarh'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd',
'B.Tech', 'B.com', 'Msc', 'MA']}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data1)
print(df)
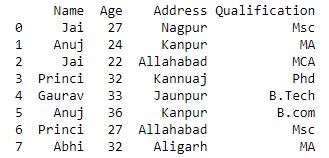
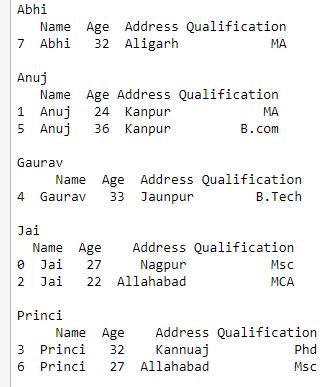
现在我们以与在 itertools.obj 中类似的方式迭代 group 的元素。
Python3
# iterating an element
# of group
grp = df.groupby('Name')
for name, group in grp:
print(name)
print(group)
print()
输出 :
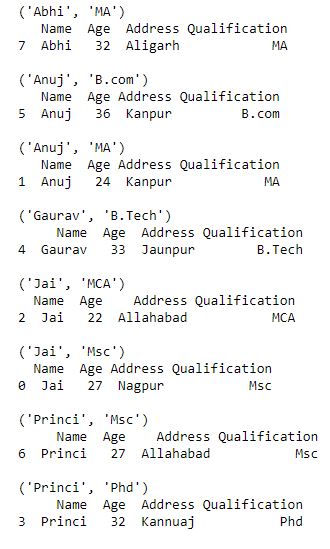
现在我们迭代包含多个键的组元素
Python3
# iterating an element
# of group containing
# multiple keys
grp = df.groupby(['Name', 'Qualification'])
for name, group in grp:
print(name)
print(group)
print()
输出 :
如输出所示,组名将是元组
选择组
为了选择一个组,我们可以使用 GroupBy.get_group() 选择组。我们可以通过应用一个函数GroupBy.get_group 来选择一个组,这个函数选择一个组。
Python3
# importing pandas module
import pandas as pd
# Define a dictionary containing employee data
data1 = {'Name':['Jai', 'Anuj', 'Jai', 'Princi',
'Gaurav', 'Anuj', 'Princi', 'Abhi'],
'Age':[27, 24, 22, 32,
33, 36, 27, 32],
'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj',
'Jaunpur', 'Kanpur', 'Allahabad', 'Aligarh'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd',
'B.Tech', 'B.com', 'Msc', 'MA']}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data1)
print(df)
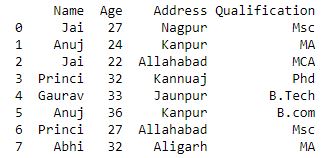
现在我们使用 Groupby.get_group 选择一个组。
Python3
# selecting a single group
grp = df.groupby('Name')
grp.get_group('Jai')
输出 :

现在我们选择一个在多列上分组的对象
Python3
# selecting object grouped
# on multiple columns
grp = df.groupby(['Name', 'Qualification'])
grp.get_group(('Jai', 'Msc'))
输出 :

对组应用函数
将数据分成组后,我们对每个组应用一个函数,以便我们执行一些操作,它们是:
- 聚合:这是一个我们计算每个组的汇总统计(或统计)的过程。例如,计算组求和或均值
- 转换:这是一个我们执行一些特定于组的计算并返回类似索引的过程。例如,用从每个组派生的值填充组内的 NA
- 过滤:这是一个我们丢弃一些组的过程,根据评估 True 或 False 的分组计算。例如,根据组总和或均值过滤掉数据
聚合:
聚合是我们计算每个组的汇总统计数据的过程。聚合函数为每个组返回一个聚合值。使用 groupby函数将数据分组后,可以对分组数据执行多个聚合操作。
代码 #1:通过聚合方法使用聚合
Python3
# importing pandas module
import pandas as pd
# importing numpy as np
import numpy as np
# Define a dictionary containing employee data
data1 = {'Name':['Jai', 'Anuj', 'Jai', 'Princi',
'Gaurav', 'Anuj', 'Princi', 'Abhi'],
'Age':[27, 24, 22, 32,
33, 36, 27, 32],
'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj',
'Jaunpur', 'Kanpur', 'Allahabad', 'Aligarh'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd',
'B.Tech', 'B.com', 'Msc', 'MA']}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data1)
print(df)
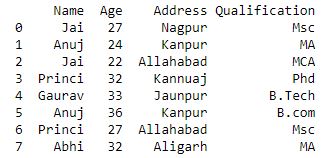
现在我们使用聚合方法进行聚合
Python3
# performing aggregation using
# aggregate method
grp1 = df.groupby('Name')
grp1.aggregate(np.sum)
输出 :

现在我们对包含多个键的组执行聚合
Python3
# performing aggregation on
# group containing multiple
# keys
grp1 = df.groupby(['Name', 'Qualification'])
grp1.aggregate(np.sum)
输出 :
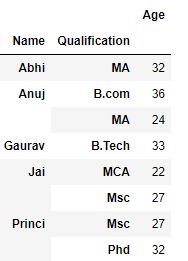
一次应用多个功能:
我们可以通过传递一个函数列表或字典来一次应用多个函数来进行聚合,输出一个 DataFrame。
Python3
# importing pandas module
import pandas as pd
# importing numpy as np
import numpy as np
# Define a dictionary containing employee data
data1 = {'Name':['Jai', 'Anuj', 'Jai', 'Princi',
'Gaurav', 'Anuj', 'Princi', 'Abhi'],
'Age':[27, 24, 22, 32,
33, 36, 27, 32],
'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj',
'Jaunpur', 'Kanpur', 'Allahabad', 'Aligarh'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd',
'B.Tech', 'B.com', 'Msc', 'MA']}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data1)
print(df)
现在我们通过传递函数列表来应用多个函数。
Python3
# applying a function by passing
# a list of functions
grp = df.groupby('Name')
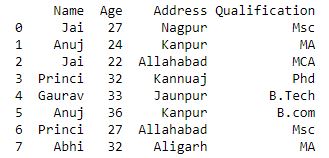
grp['Age'].agg([np.sum, np.mean, np.std])
输出 :

对 DataFrame 列应用不同的函数:
为了对 DataFrame 的列应用不同的聚合,我们可以将字典传递给聚合。
Python3
# importing pandas module
import pandas as pd
# importing numpy as np
import numpy as np
# Define a dictionary containing employee data
data1 = {'Name':['Jai', 'Anuj', 'Jai', 'Princi',
'Gaurav', 'Anuj', 'Princi', 'Abhi'],
'Age':[27, 24, 22, 32,
33, 36, 27, 32],
'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj',
'Jaunpur', 'Kanpur', 'Allahabad', 'Aligarh'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd',
'B.Tech', 'B.com', 'Msc', 'MA'],
'Score': [23, 34, 35, 45, 47, 50, 52, 53]}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data1)
print(df)
现在我们对数据框的列应用不同的聚合。
Python3
# using different aggregation
# function by passing dictionary
# to aggregate
grp = df.groupby('Name')
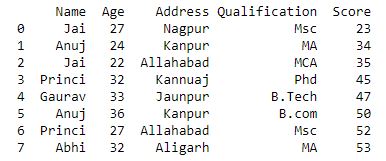
grp.agg({'Age' : 'sum', 'Score' : 'std'})
输出 :

转型 :
转换是我们执行一些特定于组的计算并返回相似索引的过程。 Transform 方法返回一个对象,该对象的索引与被分组的对象相同(相同大小)。变换函数必须:
- 返回与组块大小相同的结果
- 对组块逐列操作
- 不对组块执行就地操作。
Python3
# importing pandas module
import pandas as pd
# importing numpy as np
import numpy as np
# Define a dictionary containing employee data
data1 = {'Name':['Jai', 'Anuj', 'Jai', 'Princi',
'Gaurav', 'Anuj', 'Princi', 'Abhi'],
'Age':[27, 24, 22, 32,
33, 36, 27, 32],
'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj',
'Jaunpur', 'Kanpur', 'Allahabad', 'Aligarh'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd',
'B.Tech', 'B.com', 'Msc', 'MA'],
'Score': [23, 34, 35, 45, 47, 50, 52, 53]}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data1)
print(df)
现在我们执行一些特定于组的计算并返回一个相似索引。
Python3
# using transform function
grp = df.groupby('Name')
sc = lambda x: (x - x.mean()) / x.std()*10
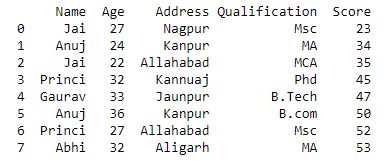
grp.transform(sc)
输出 :

过滤:
根据评估 True 或 False 的分组计算,过滤是我们丢弃一些组的过程。为了过滤组,我们使用过滤器方法并应用一些过滤组的条件。
Python3
# importing pandas module
import pandas as pd
# importing numpy as np
import numpy as np
# Define a dictionary containing employee data
data1 = {'Name':['Jai', 'Anuj', 'Jai', 'Princi',
'Gaurav', 'Anuj', 'Princi', 'Abhi'],
'Age':[27, 24, 22, 32,
33, 36, 27, 32],
'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj',
'Jaunpur', 'Kanpur', 'Allahabad', 'Aligarh'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd',
'B.Tech', 'B.com', 'Msc', 'MA'],
'Score': [23, 34, 35, 45, 47, 50, 52, 53]}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data1)
print(df)

现在我们过滤数据以返回已经存在两次或更多次的名称。
Python3
# filtering data using
# filter data
grp = df.groupby('Name')
grp.filter(lambda x: len(x) >= 2)
输出 :
