使用 BeautifulSoup 按 CSS 类查找标签
在本文中,我们将讨论如何使用 BeautifulSoup 通过 CSS 查找标签。我们得到一个 HTML 文档,我们需要使用 CSS 类从文档中查找和提取标签。
例子:
HTML Document:
Geeksforgeeks
Extract this tag
Output:
Extract this tag所需模块:
- bs4:它是一个Python库,用于从 HTML、XML 和其他标记语言中抓取数据。
确保您的系统上安装了 pip。
在终端中运行以下命令来安装这个库——
pip install bs4
or
pip install beautifulsoup4方法:
- 导入 bs4 库
- 创建 HTML 文档
- 将内容解析为 BeautifulSoup 对象
- 按 CSS 类搜索 – CSS 属性的名称“class”是Python的保留字。如果class用作关键字参数,编译器会给出语法错误。我们可以使用关键字参数class_搜索 CSS 类
我们可以向 class_ 传递一个字符串、一个正则表达式、一个函数或 True。 - find_all()与关键字参数class_用于查找具有给定 CSS 类的所有标签
如果我们只需要找到一个标签,则使用find() - 打印提取的标签。
示例 1:使用 find() 方法查找标签
Python3
# Import Module
from bs4 import BeautifulSoup
# HTML Document
HTML_DOC = """
Geeksforgeeks
Extract this tag
"""
# Function to find tags
def find_tags_from_class(html):
# parse html content
soup = BeautifulSoup(html, "html.parser")
# find tags by CSS class
div = soup.find("div", class_= "ext")
# Print the extracted tag
print(div)
# Function Call
find_tags_from_class(HTML_DOC)Python3
# Import Module
from bs4 import BeautifulSoup
# HTML Document
HTML_DOC = """
Table Data
This is row 1
This is row 2
This is row 3
This is row 4
This is row 5
"""
# Function to find tags
def find_tags_from_class(html):
# parse html content
soup = BeautifulSoup(html, "html.parser")
# find tags by CSS class
rows = soup.find_all("td", class_= "table-row")
# Print the extracted tag
for row in rows:
print(row)
# Function Call
find_tags_from_class(HTML_DOC)Python3
# Import Module
from bs4 import BeautifulSoup
import re
# HTML Document
HTML_DOC = """
Table Data
This is row 1
This is row 2
This is row 3
This is row 4
This is row 5
"""
# Function to find tags
def find_tags_from_class(html):
# parse html content
soup = BeautifulSoup(html, "html.parser")
# find tags by CSS class using regular expressions
# $ is used to match pattern ending with
# Here we are finding class that ends with "row"
rows = soup.find_all("td", class_= re.compile("row$"))
# Print the extracted tag
for row in rows:
print(row)
# Function Call
find_tags_from_class(HTML_DOC)Python3
# Import Module
from bs4 import BeautifulSoup
# HTML Document
HTML_DOC = """
Table Data
This is invalid because len(table) != 3
This is valid because len(row) == 3
This is invalid because len(data) != 3
This is valid because len(hii) == 3
This is invalid because class is None
"""
# Returns true if the css_class is not None
# and length of css_class is equal to 3
# else returns false
def has_three_characters(css_class):
return css_class is not None and len(css_class) == 3
# Function to find tags
def find_tags_from_class(html):
# parse html content
soup = BeautifulSoup(html, "html.parser")
# find tags by CSS class using user-defined function
rows = soup.find_all("td", class_= has_three_characters)
# Print the extracted tag
for row in rows:
print(row)
# Function Call
find_tags_from_class(HTML_DOC)Python3
# Import Module
from bs4 import BeautifulSoup
import requests
# Assign website
import requests
URL = "https://www.geeksforgeeks.org/"
HTML_DOC = requests.get(URL)
# Function to find tags
def find_tags_from_class(html):
# parse html content
soup = BeautifulSoup(html.content, "html5lib")
# find tags by CSS class
div = soup.find("div", class_= "article--container_content")
# Print the extracted tag
print(div)
# Function Call
find_tags_from_class(HTML_DOC)输出:

示例 2:使用 find_all() 方法查找所有标签
蟒蛇3
# Import Module
from bs4 import BeautifulSoup
# HTML Document
HTML_DOC = """
Table Data
This is row 1
This is row 2
This is row 3
This is row 4
This is row 5
"""
# Function to find tags
def find_tags_from_class(html):
# parse html content
soup = BeautifulSoup(html, "html.parser")
# find tags by CSS class
rows = soup.find_all("td", class_= "table-row")
# Print the extracted tag
for row in rows:
print(row)
# Function Call
find_tags_from_class(HTML_DOC)
输出:

示例 3:使用正则表达式按 CSS 类查找标签。
蟒蛇3
# Import Module
from bs4 import BeautifulSoup
import re
# HTML Document
HTML_DOC = """
Table Data
This is row 1
This is row 2
This is row 3
This is row 4
This is row 5
"""
# Function to find tags
def find_tags_from_class(html):
# parse html content
soup = BeautifulSoup(html, "html.parser")
# find tags by CSS class using regular expressions
# $ is used to match pattern ending with
# Here we are finding class that ends with "row"
rows = soup.find_all("td", class_= re.compile("row$"))
# Print the extracted tag
for row in rows:
print(row)
# Function Call
find_tags_from_class(HTML_DOC)
输出:

解释:
This is row 2
This is row 4 以上两个标签类名以“row”结尾。因此,它们被提取。其他标签类名不以“row”结尾。因此,它们不会被提取。
示例 4:使用用户定义函数按 CSS 类查找标签。
蟒蛇3
# Import Module
from bs4 import BeautifulSoup
# HTML Document
HTML_DOC = """
Table Data
This is invalid because len(table) != 3
This is valid because len(row) == 3
This is invalid because len(data) != 3
This is valid because len(hii) == 3
This is invalid because class is None
"""
# Returns true if the css_class is not None
# and length of css_class is equal to 3
# else returns false
def has_three_characters(css_class):
return css_class is not None and len(css_class) == 3
# Function to find tags
def find_tags_from_class(html):
# parse html content
soup = BeautifulSoup(html, "html.parser")
# find tags by CSS class using user-defined function
rows = soup.find_all("td", class_= has_three_characters)
# Print the extracted tag
for row in rows:
print(row)
# Function Call
find_tags_from_class(HTML_DOC)
输出:

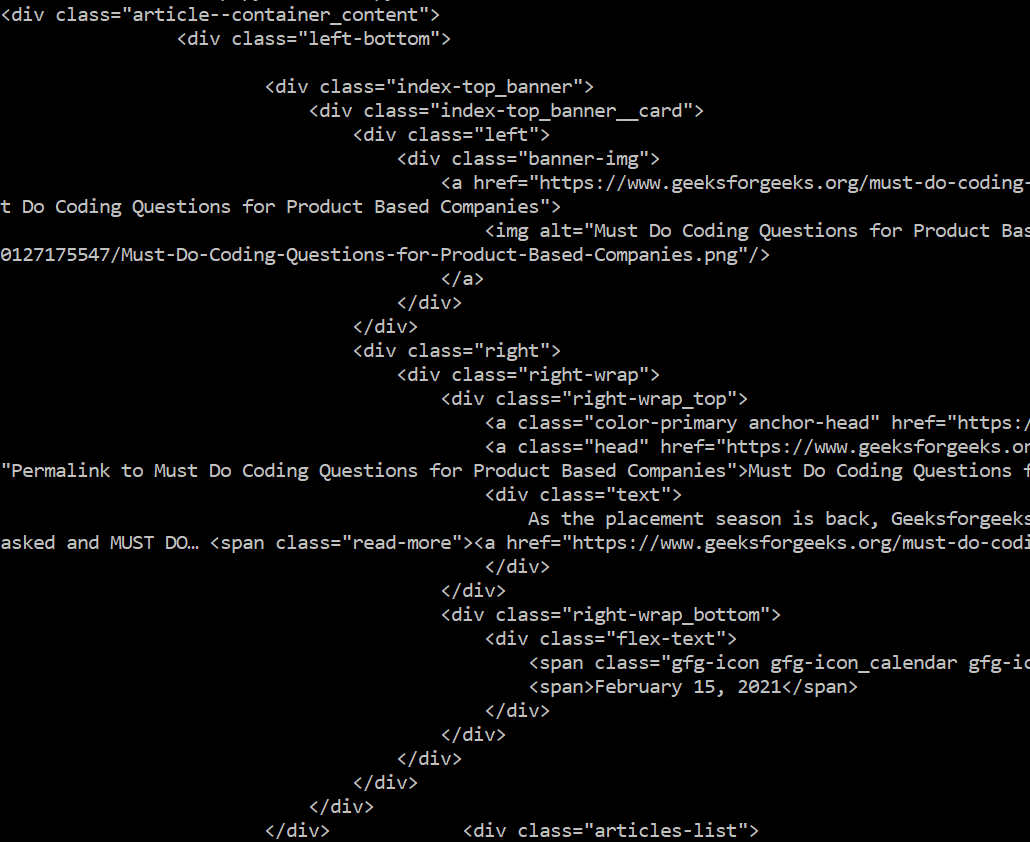
示例 5:从网站中按 CSS 类查找标签
蟒蛇3
# Import Module
from bs4 import BeautifulSoup
import requests
# Assign website
import requests
URL = "https://www.geeksforgeeks.org/"
HTML_DOC = requests.get(URL)
# Function to find tags
def find_tags_from_class(html):
# parse html content
soup = BeautifulSoup(html.content, "html5lib")
# find tags by CSS class
div = soup.find("div", class_= "article--container_content")
# Print the extracted tag
print(div)
# Function Call
find_tags_from_class(HTML_DOC)
输出: