如何删除重复项并将其保留在 PySpark 数据框中
在本文中,我们将讨论如何处理 pyspark 数据帧中的重复值。数据集可能包含对我们的任务无用的重复行或重复数据点。我们数据框中的这些重复值称为重复值。
为了处理重复值,我们可以使用一种策略,保留第一次出现的值并删除其余的值。
dropduplicates(): Pyspark 数据帧提供 dropduplicates()函数,用于删除数据帧内重复出现的数据。
Syntax: dataframe_name.dropDuplicates(Column_name)
该函数将列名作为必须删除重复值的参数。
创建用于演示的数据框:
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField,
StringType, IntegerType, FloatType
# Start spark session
spark = SparkSession.builder.appName("Student_Info").getOrCreate()
# Initialize our data
data2 = [("Pulkit", 12, "CS32", 82, "Programming"),
("Ritika", 20, "CS32", 94, "Writing"),
("Ritika", 20, "CS32", 84, "Writing"),
("Atirikt", 4, "BB21", 58, "Doctor"),
("Atirikt", 4, "BB21", 78, "Doctor"),
("Ghanshyam", 4, "DD11", 38, "Lawyer"),
("Reshav", 18, "EE43", 56, "Timepass")
]
# Define schema
schema = StructType([
StructField("Name", StringType(), True),
StructField("Roll Number", IntegerType(), True),
StructField("Class ID", StringType(), True),
StructField("Marks", IntegerType(), True),
StructField("Extracurricular", StringType(), True)
])
# read the dataframe
df = spark.createDataFrame(data=data2, schema=schema)
df.show()Python3
# drop duplicates
df.dropDuplicates(['Roll Number']).show()
# stop Session
spark.stop()Python3
# drop duplicates
df.dropDuplicates(['Roll Number',"Name"]).show()
# stop the session
spark.stop()输出:
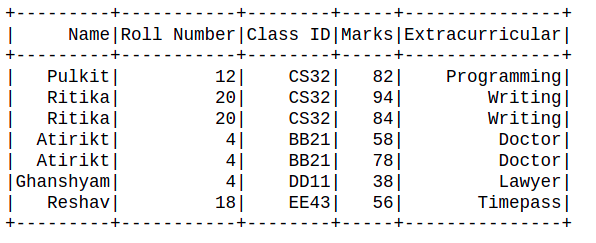
示例 1:此示例说明 dropDuplicates()函数对单个列参数的工作。数据集是定制的,所以我们定义了架构并使用 spark.createDataFrame()函数来创建数据帧。
蟒蛇3
# drop duplicates
df.dropDuplicates(['Roll Number']).show()
# stop Session
spark.stop()
输出:

从上面的观察中,很明显,具有重复卷号的行被删除,只有第一次出现在数据帧中。
示例 2:此示例说明了 dropDuplicates()函数对多个列参数的工作。数据集是定制的,所以我们定义了架构并使用 spark.createDataFrame()函数来创建数据帧。
蟒蛇3
# drop duplicates
df.dropDuplicates(['Roll Number',"Name"]).show()
# stop the session
spark.stop()
输出:

从上面的观察中,很明显,具有重复卷号和名称的数据点被删除,只有第一次出现在数据框中。
注意:仅删除了具有两个参数作为重复项的数据。在上面的例子中,“Ghanshyam”的列名有一个 Roll Number 重复值,但 Name 是唯一的,所以它没有从数据框中删除。因此,该函数考虑所有参数而不仅仅是其中之一。