数据挖掘中的元组重复
数据集成是一种数据预处理技术,涉及将来自多个异构数据源的数据组合到一个连贯的数据存储中,并提供数据的统一视图。这些源可能包括多个数据立方体、数据库或平面文件。
数据集成方法正式定义为三元组
- G 代表全局模式,
- S代表模式的异构源,
- M 代表源和全局模式查询之间的映射。
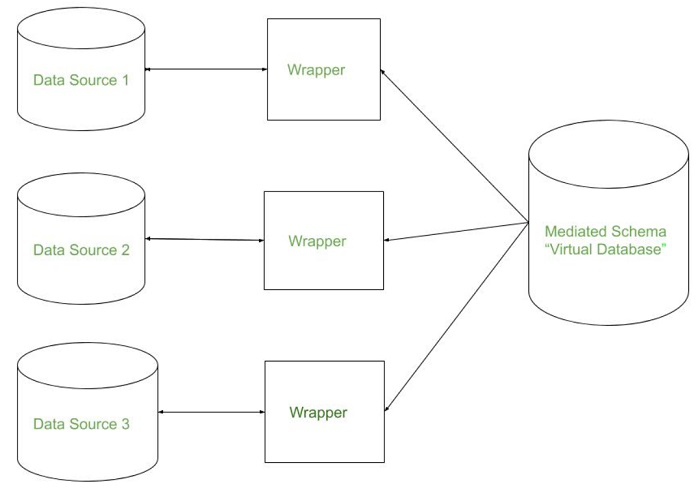
当数据从多个数据库或应用程序集成时,通常会出现冗余数据属性。冗余和元组重复是数据挖掘过程中数据集成中的重要问题。如果像年收入这样的属性是从其他关系的属性中导出的,那么它可能是多余的。重复的元组还会增加数据库的大小并使其变得复杂。重复的元组和属性会导致属性不一致以及数据库或数据集中的不一致。重复元组通常是由于数据输入不准确或更新类似数据出现的文件造成的。
如果数据库中的关系具有非规范化的表,那么它也会导致数据冗余。来自不同实体的属性的维度命名也会导致数据集中的冗余。当相同的现实世界实体用不同的属性名称表示时,关系数据库中也会出现重复的数据元组。这可能是由于数据值的表示或缩放差异造成的。
| S.No. | Petal length | Petal Width | Sepal Length | Sepal Width |
|---|---|---|---|---|
| 01. | 3.4 | 5.6 | 4.7 | 4.5 |
| 02. | 4.4 | 5.8 | 6.7 | 5.9 |
| 03. | 5.9 | 6.9 | 7.8 | 5.8 |
| 04. | 3.4 | 5.6 | 4.7 | 4.5 |
让我们考虑上面的花数据集表,它是一组值。表中的第一个和最后一个元组值相同。所以最后一个元组被认为是重复的。如果两行的所有属性值都相同,我们认为元组是重复的。
必须检测属性和重复元组之间的冗余。重复的数据元组单独给出相同的结果,如果数据集包含重复的元组,这会影响机器学习算法的整体性能。重复的元组也可能导致数据库维护困难。
因此,删除重复元组被认为是所有应用程序中数据处理的首要步骤。在对数据集执行操作或开发模型的数据集之前,先对数据集进行清理以去除噪声数据。重复元组是影响模型准确性的噪声数据。
在某些情况下,重复的元组会导致严重的问题,例如,如果另一个购买者具有相同的名称,则采购订单数据库包含诸如购买者的姓名和地址等属性,如果这两个购买者具有相同的地址,则由于技术问题,则很难找到订购产品的特定客户。我们可以在数据挖掘的数据清理过程中通过从数据集中删除重复的元组来处理它们。删除重复的元组是处理由此引起的冗余的唯一方法。