如何处理机器学习中的不平衡类
在机器学习中,“类不平衡”是一个熟悉的问题,尤其是在分类中,当我们拥有每个类中数据点比例不相等的数据集时。模型的训练变得更加棘手,因为典型的准确性不再是衡量模型性能的可靠指标。现在,如果少数类中的数据点数量少得多,那么它可能最终在训练过程中被完全忽略。
Over/Up-Sample 少数族裔类别
在上采样中,少数类的样本被随机复制,以达到与多数类的等价性。有许多方法可用于实现这一目标。
1.使用scikit-learn:
这可以通过从 scikit-learn 导入 resample 模块来完成。
Syntax: sklearn.utils.resample(*arrays, replace=True, n_samples=None, random_state=None, stratify=None)
Parameters:
- *arrays: Dataframe/lists/arrays
- replace: Implements resampling with or without replacement. Boolean type of value. Default value is True.
- n_samples: Number of samples to be generated. Default value is None. If value is None then first dimension of array is taken automatically. This value will not be longer than length of arrays if replace is given as False.
- random_state: Used for shuffling the data. If positive non zero number is given then it shuffles otherwise not. Default value is None.
- stratify: Data is split in stratified fashion if set to True. Default value is None.
Return Value: Sequence of resampled data.
例子 :
Python3
# Importing scikit-learn, pandas library
from sklearn.utils import resample
from sklearn.datasets import make_classification
import pandas as pd
# Making DataFrame having 100
# dummy samples with 4 features
# Divided in 2 classes in a ratio of 80:20
X, y = make_classification(n_classes=2,
weights=[0.8, 0.2],
n_features=4,
n_samples=100,
random_state=42)
df = pd.DataFrame(X, columns=['feature_1',
'feature_2',
'feature_3',
'feature_4'])
df['balance'] = y
print(df)
# Let df represent the dataset
# Dividing majority and minority classes
df_major = df[df.balance == 0]
df_minor = df[df.balance == 1]
# Upsampling minority class
df_minor_sample = resample(df_minor,
# Upsample with replacement
replace=True,
# Number to match majority class
n_samples=80,
random_state=42)
# Combine majority and upsampled minority class
df_sample = pd.concat([df_major, df_minor_sample])
# Display count of data points in both class
print(df_sample.balance.value_counts())Python3
# Importing imblearn,scikit-learn library
from imblearn.over_sampling import RandomOverSampler
from sklearn.datasets import make_classification
# Making Dataset having 100
# dummy samples with 4 features
# Divided in 2 classes in a ratio of 80:20
X, y = make_classification(n_classes=2,
weights=[0.8, 0.2],
n_features=4,
n_samples=100,
random_state=42)
# Printing number of samples in
# each class before Over-Sampling
t = [(d) for d in y if d==0]
s = [(d) for d in y if d==1]
print('Before Over-Sampling: ')
print('Samples in class 0: ',len(t))
print('Samples in class 1: ',len(s))
# Over Sampling Minority class
OverS = RandomOverSampler(random_state=42)
# Fit predictor (x variable)
# and target (y variable) using fit_resample()
X_Over, Y_Over = OverS.fit_resample(X, y)
# Printing number of samples in
# each class after Over-Sampling
t = [(d) for d in Y_Over if d==0]
s = [(d) for d in Y_Over if d==1]
print('After Over-Sampling: ')
print('Samples in class 0: ',len(t))
print('Samples in class 1: ',len(s))Python3
# Importing imblearn, scikit-learn library
from imblearn.over_sampling import SMOTE
from sklearn.datasets import make_classification
# Making Dataset having
# 100 dummy samples with 4 features
# Divided in 2 classes in a ratio of 80:20
X, y = make_classification(n_classes=2,
weights=[0.8, 0.2],
n_features=4,
n_samples=100,
random_state=42)
# Printing number of samples in
# each class before Over-Sampling
t = [(d) for d in y if d==0]
s = [(d) for d in y if d==1]
print('Before Over-Sampling: ')
print('Samples in class 0: ',len(t))
print('Samples in class 1: ',len(s))
# Making an instance of SMOTE class
# For oversampling of minority class
smote = SMOTE()
# Fit predictor (x variable)
# and target (y variable) using fit_resample()
X_OverSmote, Y_OverSmote = smote.fit_resample(X, y)
# Printing number of samples
# in each class after Over-Sampling
t = [(d) for d in Y_OverSmote if d==0]
s = [(d) for d in Y_OverSmote if d==1]
print('After Over-Sampling: ')
print('Samples in class 0: ',len(t))
print('Samples in class 1: ',len(s))Python3
# Importing scikit-learn, pandas library
from sklearn.utils import resample
from sklearn.datasets import make_classification
import pandas as pd
# Making DataFrame having
# 100 dummy samples with 4 features
# Divided in 2 classes in a ratio of 80:20
X, y = make_classification(n_classes=2,
weights=[0.8, 0.2],
n_features=4,
n_samples=100,
random_state=42)
df = pd.DataFrame(X, columns=['feature_1',
'feature_2',
'feature_3',
'feature_4'])
df['balance'] = y
print(df)
# Let df represent the dataset
# Dividing majority and minority classes
df_major = df[df.balance==0]
df_minor = df[df.balance==1]
# Down sampling majority class
df_major_sample = resample(df_major,
replace=False, # Down sample without replacement
n_samples=20, # Number to match minority class
random_state=42)
# Combine down sampled majority class and minority class
df_sample = pd.concat([df_major_sample, df_minor])
# Display count of data points in both class
print(df_sample.balance.value_counts())Python3
# Importing imblearn library
from imblearn.under_sampling import RandomUnderSampler
from sklearn.datasets import make_classification
# Making Dataset having
# 100 dummy samples with 4 features
# Divided in 2 classes in a ratio of 80:20
X, y = make_classification(n_classes=2,
weights=[0.8, 0.2],
n_features=4,
n_samples=100,
random_state=42)
# Printing number of samples
# in each class before Under-Sampling
t = [(d) for d in y if d==0]
s = [(d) for d in y if d==1]
print('Before Under-Sampling: ')
print('Samples in class 0: ',len(t))
print('Samples in class 1: ',len(s))
# Down-Sampling majority class
UnderS = RandomUnderSampler(random_state=42,
replacement=True)
# Fit predictor (x variable)
# and target (y variable) using fit_resample()
X_Under, Y_Under = UnderS.fit_resample(X, y)
# Printing number of samples in
# each class after Under-Sampling
t = [(d) for d in Y_Under if d==0]
s = [(d) for d in Y_Under if d==1]
print('After Under-Sampling: ')
print('Samples in class 0: ',len(t))
print('Samples in class 1: ',len(s))输出:

解释 :
- 首先,我们将每个类的数据点划分为单独的 DataFrame。
- 在此之后,通过将数据点的数量设置为与多数类的数量相等,对少数类进行重采样。
- 最后,我们将连接原始的多数类 DataFrame 和上采样的少数类 DataFrame。
2. 使用 RandomOverSampler:
这可以在 imblearn 中的 RandomOverSampler 方法的帮助下完成。此函数随机生成属于少数类的新数据点(默认情况下)。
Syntax: RandomOverSampler(sampling_strategy=’auto’, random_state=None, shrinkage=None)
Parameters:
- sampling_strategy: Sampling Information for dataset.Some Values are- ‘minority’: only minority class ‘not minority’: all classes except minority class, ‘not majority’: all classes except majority class, ‘all’: all classes, ‘auto’: similar to ‘not majority’, Default value is ‘auto’
- random_state: Used for shuffling the data. If a positive non-zero number is given then it shuffles otherwise not. Default value is None.
- shrinkage: Parameter controlling the shrinkage. Values are: float: Shrinkage factor applied on all classes. dict: Every class will have a specific shrinkage factor. None: Shrinkage= 0. Default value is None.
例子:
Python3
# Importing imblearn,scikit-learn library
from imblearn.over_sampling import RandomOverSampler
from sklearn.datasets import make_classification
# Making Dataset having 100
# dummy samples with 4 features
# Divided in 2 classes in a ratio of 80:20
X, y = make_classification(n_classes=2,
weights=[0.8, 0.2],
n_features=4,
n_samples=100,
random_state=42)
# Printing number of samples in
# each class before Over-Sampling
t = [(d) for d in y if d==0]
s = [(d) for d in y if d==1]
print('Before Over-Sampling: ')
print('Samples in class 0: ',len(t))
print('Samples in class 1: ',len(s))
# Over Sampling Minority class
OverS = RandomOverSampler(random_state=42)
# Fit predictor (x variable)
# and target (y variable) using fit_resample()
X_Over, Y_Over = OverS.fit_resample(X, y)
# Printing number of samples in
# each class after Over-Sampling
t = [(d) for d in Y_Over if d==0]
s = [(d) for d in Y_Over if d==1]
print('After Over-Sampling: ')
print('Samples in class 0: ',len(t))
print('Samples in class 1: ',len(s))
输出:
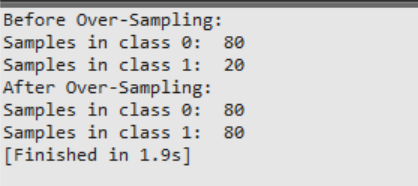
3. 合成少数过采样技术(SMOTE):
SMOTE 用于为少数类生成人工/合成样本。该技术的工作原理是从少数类中随机选择一个样本并确定该样本的 K-Nearest Neighbors,然后将人工样本添加到挑选的样本及其邻居之间。此函数存在于 imblearn 模块中。
Syntax: SMOTE(sampling_strategy=’auto’, random_state=None, k_neighbors=5, n_jobs=None)
Parameters:
- sampling_strategy: Sampling Information for dataset
- random_state: Used for shuffling the data. If positive non zero number is given then it shuffles otherwise not. Default value is None.
- k_neighbors: Number count of nearest neighbours used to generate artificial/synthetic samples. Default value is 5
- n_jobs: Number of CPU cores to be used. Default value is None. None here means 1 not 0.
例子:
Python3
# Importing imblearn, scikit-learn library
from imblearn.over_sampling import SMOTE
from sklearn.datasets import make_classification
# Making Dataset having
# 100 dummy samples with 4 features
# Divided in 2 classes in a ratio of 80:20
X, y = make_classification(n_classes=2,
weights=[0.8, 0.2],
n_features=4,
n_samples=100,
random_state=42)
# Printing number of samples in
# each class before Over-Sampling
t = [(d) for d in y if d==0]
s = [(d) for d in y if d==1]
print('Before Over-Sampling: ')
print('Samples in class 0: ',len(t))
print('Samples in class 1: ',len(s))
# Making an instance of SMOTE class
# For oversampling of minority class
smote = SMOTE()
# Fit predictor (x variable)
# and target (y variable) using fit_resample()
X_OverSmote, Y_OverSmote = smote.fit_resample(X, y)
# Printing number of samples
# in each class after Over-Sampling
t = [(d) for d in Y_OverSmote if d==0]
s = [(d) for d in Y_OverSmote if d==1]
print('After Over-Sampling: ')
print('Samples in class 0: ',len(t))
print('Samples in class 1: ',len(s))
输出:

解释:
- 少数类作为输入向量给出。
- 确定其 K 最近邻
- 选择其中一个邻居,并在邻居和正在考虑的采样点之间的任何位置放置一个人工采样点。
- 重复直到数据集平衡。
过采样的优点:
- 无信息丢失
- 优于抽样不足
过采样的缺点:
- 随着少数类的重复,过度拟合的机会增加
下/欠样本多数类
Down/Under Sampling 是随机选择多数类样本并将其删除以防止它们在数据集中控制少数类的过程。
1. 使用 scikit-learn :
它类似于上采样,可以通过从 scikit-learn 导入重采样模块来完成。
例子 :
Python3
# Importing scikit-learn, pandas library
from sklearn.utils import resample
from sklearn.datasets import make_classification
import pandas as pd
# Making DataFrame having
# 100 dummy samples with 4 features
# Divided in 2 classes in a ratio of 80:20
X, y = make_classification(n_classes=2,
weights=[0.8, 0.2],
n_features=4,
n_samples=100,
random_state=42)
df = pd.DataFrame(X, columns=['feature_1',
'feature_2',
'feature_3',
'feature_4'])
df['balance'] = y
print(df)
# Let df represent the dataset
# Dividing majority and minority classes
df_major = df[df.balance==0]
df_minor = df[df.balance==1]
# Down sampling majority class
df_major_sample = resample(df_major,
replace=False, # Down sample without replacement
n_samples=20, # Number to match minority class
random_state=42)
# Combine down sampled majority class and minority class
df_sample = pd.concat([df_major_sample, df_minor])
# Display count of data points in both class
print(df_sample.balance.value_counts())
输出:

解释 :
- 首先,我们将每个类的数据点划分为单独的 DataFrame。
- 之后,通过将数据点的数量设置为与少数类相同,对多数类进行重新采样而不进行替换。
- 最后,我们将连接原始的少数类 DataFrame 和下采样的多数类 DataFrame。
2:使用 RandomUnderSampler
这可以借助 imblearn 中的 RandomUnderSampler 方法来完成。此函数随机选择该类的数据子集。
Syntax: RandomUnderSampler(sampling_strategy=’auto’, random_state=None, replacement=False)
Parameters:
- sampling_strategy: Sampling Information for dataset.
- random_state: Used for shuffling the data. If positive non zero number is given then it shuffles otherwise not. Default value is None.
- replacement: Implements resampling with or without replacement. Boolean type of value. Default value is False.
例子:
Python3
# Importing imblearn library
from imblearn.under_sampling import RandomUnderSampler
from sklearn.datasets import make_classification
# Making Dataset having
# 100 dummy samples with 4 features
# Divided in 2 classes in a ratio of 80:20
X, y = make_classification(n_classes=2,
weights=[0.8, 0.2],
n_features=4,
n_samples=100,
random_state=42)
# Printing number of samples
# in each class before Under-Sampling
t = [(d) for d in y if d==0]
s = [(d) for d in y if d==1]
print('Before Under-Sampling: ')
print('Samples in class 0: ',len(t))
print('Samples in class 1: ',len(s))
# Down-Sampling majority class
UnderS = RandomUnderSampler(random_state=42,
replacement=True)
# Fit predictor (x variable)
# and target (y variable) using fit_resample()
X_Under, Y_Under = UnderS.fit_resample(X, y)
# Printing number of samples in
# each class after Under-Sampling
t = [(d) for d in Y_Under if d==0]
s = [(d) for d in Y_Under if d==1]
print('After Under-Sampling: ')
print('Samples in class 0: ',len(t))
print('Samples in class 1: ',len(s))
输出:

欠采样的优点:
- 更好的运行时间
- 随着训练示例的减少,改进了存储问题
欠采样的缺点:
- 可能会丢弃潜在的重要信息。
- 选择的样本可以是有偏见的实例。